Outcome robustness and implementation robustness
Anthony DiGiovanni
Credit to Anni Leskelä for coming up with this framework.
We’d like to take interventions that look net-positive even after accounting for our deep uncertainty about the long-term future. I’ll say an intervention is robust to the extent that the argument for the intervention being net-positive is not sensitive to unusually hard-to-estimate factors. Most notably, these hard-to-estimate factors might be crucial considerations we haven’t yet discovered, about mechanisms by which the intervention could backfire.
It’s helpful to distinguish two aspects of an intervention’s robustness:
- Outcome robustness: Intervening on some (coarse-grained) target variable in a given direction would be net-positive.
- Implementation robustness: Our intervention on the target variable would (i) change that variable in the intended direction, and (ii) avoid changing other variables in directions that might outweigh the intended positive effect.
Fig. 1 visually summarizes this distinction.
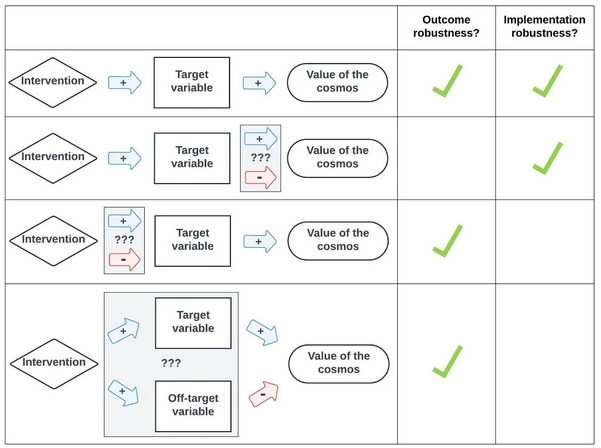
Example of outcome robustness failure
It's unclear whether “human” space colonization (SC) is better than misaligned AI SC, given how many systematic ways these coarse categories could differ in various directions. (Especially when we consider exotic possibilities, like interactions with alien civilizations and acausal trade.)
Example of implementation robustness failure
AI safety interventions might (i) increase the risk of human disempowerment by AI, e.g., by increasing AI companies’ complacency; or (ii) increase the risk of extinction by causes other than successful AI takeover, e.g., a great power war with novel WMDs.
It can be easy to mistakenly conclude an intervention is robust merely because it’s outcome-robust, neglecting implementation robustness (or vice versa). Likewise, it can be easy to conclude an intervention is implementation-robust merely because it satisfies condition (i) above, neglecting condition (ii).