When is intent alignment sufficient or necessary to reduce AGI conflict?
Contents
In this post, we look at conditions under which Intent Alignment isn't Sufficient or Intent Alignment isn't Necessary for interventions on AGI systems to reduce the risks of (unendorsed) conflict to be effective. We then conclude this sequence by listing what we currently think are relatively promising directions for technical research and intervention to reduce AGI conflict.
Intent alignment is not sufficient to prevent unendorsed conflict
In the previous post, we outlined possible causes of conflict and directions for intervening on those causes. Many of the causes of conflict seem like they would be addressed by successful AI alignment. For example: if AIs acquire conflict-prone preferences from their training data when we didn’t want them to, that is a clear case of misalignment. One of the suggested solutions: improving adversarial training and interpretability, just is alignment research, albeit directed at a specific type of misaligned behavior. We might naturally ask, does all work to reduce conflict risk follow this pattern? That is, is intent alignment sufficient to avoid unendorsed conflict?
Intent Alignment isn't Sufficient is a claim about unendorsed conflict. We’re focusing on unendorsed conflict because we want to know whether technical interventions on AGIs to reduce the risks of conflict make a difference. These interventions mostly make sense for preventing conflict that isn’t desired by the overseers of the systems. (If the only conflict between AGIs is endorsed by their overseers, then conflict reduction is a problem of ensuring that AGI overseers aren’t motivated to start conflicts.)
Let H be a human principal and A be its AGI agent. “Unendorsed” conflict, in our sense, is conflict which would not have been endorsed on reflection by H at the time A was deployed. This notion of “unendorsed” is a bit complicated. In particular, it doesn’t just mean “not endorsed by a human at the time the agent decided to engage in conflict”. We chose it because we think it should include the following cases:
- H makes a mistake in designing A such that conflict at a later time is rational by H’s lights. For example, H could’ve built A so that it can solve Prisoner’s Dilemmas using open-source game theory but failed to do so. Then A finds itself in a one-shot Prisoner’s Dilemma (as evaluated by H’s preferences), and defects. Even though H would approve of A’s decision to defect at the time, they would not endorse their own mistake of locking in a suboptimal architecture for A.
- H’s interactions with A lead to H’s preferences being corrupted, and then H approves of a decision they would not have approved of if their preferences hadn’t been corrupted. (It’s sometimes hard to say whether changes in preferences count as “corruption”. Hopefully, our examples below are clear cases of preference corruption.)
We’ll use Evan Hubinger’s decomposition of the alignment problem. In Evan’s decomposition, an AI is aligned with humans (i.e., doesn’t take any actions we would consider bad/problematic/dangerous/catastrophic) if it is intent-aligned and capability robust. (An agent is capability robust if it performs well by its own lights once it is deployed.) So the question for us is: What aspects of capability robustness determine whether unendorsed conflict occurs, and will these be present by default if intent alignment succeeds?
Let’s decompose conflict-avoiding “capability robustness” into the capabilities necessary and sufficient for avoiding unendorsed conflict into two parts:
- Cooperative capabilities. An agent is cooperatively capable to the extent that it’s able to avoid conflict that is costly by its lights, when it is rational to do so.
- Understanding H’s cooperation-relevant preferences. This means that the agent understands H’s preferences sufficiently well that it would avoid unendorsed conflict, given that (i) it is intent-aligned and (ii) sufficiently cooperatively capable.
Two conditions need to hold for unendorsed conflict to occur if the AGIs are intent aligned (summarized in Figure 1): (1) the AIs lack some cooperative capability or have misunderstood their overseer’s cooperation-relevant preferences, and (2) conflict is not prevented by the AGI consulting with its overseer.
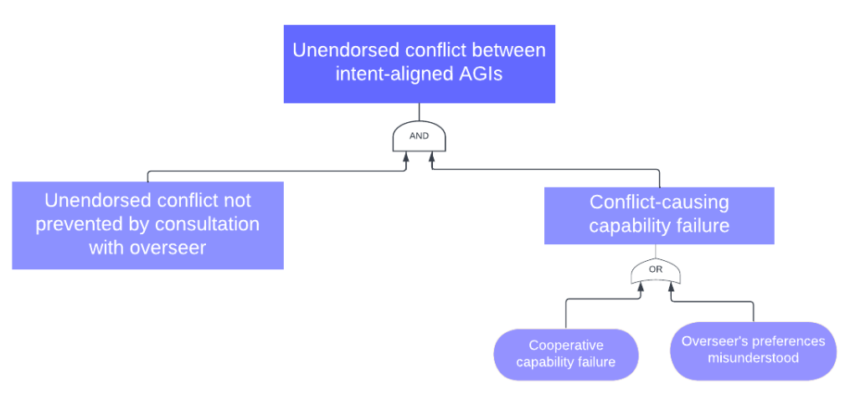
These conditions may sometimes hold. In the next section, we list scenarios in which consultation with overseers would fail to prevent conflict. We then look at “conflict-causing capabilities failures”.
When would consultation with overseers fail to prevent catastrophic decisions?
One reason to doubt that intent-aligned AIs will engage in unendorsed conflict is that these AIs should be trying to figure out what their overseers want. Whenever possible, and especially before taking any irreversible action like starting a destructive conflict, the AI should check whether its understanding of overseer preferences is accurate. Here are some reasons why we still might see catastrophic decisions, despite this4:
- the overseers are not present, perhaps as a result of a war that has already occurred, and therefore the AI must act on mistaken beliefs about their preferences;
- the AI judges that it doesn’t have time to clarify the overseer’s preferences before acting (likely due to competitive pressures, e.g., because the AI is making complex decisions in the middle of a war);
- the overseer’s values have been unintentionally corrupted by an AI, and thus the overseer approves of a decision that they would not have endorsed under an appropriate reflection process;
- the overseers have deliberately delegated lots of operations to the AI, and both the AI and the human operator were falsely confident that the AI understands the operator’s preferences well enough to not need to ask;
- the overseer has fully delegated to the AI as a commitment mechanism;
- a suboptimal architecture is locked in, making conflict rational by the overseer’s lights, such that consultation with an overseer wouldn’t help anyway. (Toy example: The agent isn’t able to use program equilibrium-type solutions to solve one-shot Prisoner’s Dilemmas, even though it would’ve been possible to build it such that it could.)
Conflict-causing capabilities failures
Failures of cooperative capabilities
Let’s return to our causes of conflict and see how intent-aligned AGIs might fail to have the capabilities necessary to avoid unendorsed conflict due to these factors.
- Informational and commitment inability problems. (We put these together because they are both problems stemming from certain kinds of technological constraints on the agents.) One reason intent-aligned AGIs might engage in unendorsed conflict is path-dependencies in their design: the humans or AIs who designed the systems locked in less transparent designs which prevented the AGIs from using commitment and information revelation schemes, or implementing a credible surrogate goal. These are unendorsed because the designers of these intent-aligned AGIs made a mistake when building their systems that they would not endorse on reflection. These failures seem most likely early in a multipolar AI takeoff, when time pressures or cognitive limitations might prevent AGIs from building successor agents that have the necessary commitment abilities or transparency.
- Miscoordination. An intent-aligned AGI might still be bad at reasoning about commitments, and make a catastrophic commitment. This seems most likely when an overseer is out of the loop, and therefore unable to override the AI’s decision, or early in takeoff, when an AI hasn’t had time to think carefully about how to make commitments.
Failures to understand cooperation-relevant preferences
We break cooperation-relevant preferences into “object-level preferences” (such as how bad a particular conflict would be) and “meta-preferences” (such as how to reflect about how one wants to approach complicated bargaining problems).
- Failure to understand object-level preferences. AI systems may infer that human preferences are more conflict-prone than they actually are, and then end up in one of the above situations where it will fail to clarify the human preferences.
- Failure to understand meta-preferences. Wei Dai has written about “value corruption”. The relevant kind of value corruption here is that an intent-aligned AI system could (unintentionally) influence the values of its human operator to be more conflict-prone in ways that wouldn’t have been endorsed by the human operator as they were before AI assistance. (Recall that this counts as “unendorsed conflict” in our terminology.) As a toy example of how this could lead to unendorsed conflict, we might imagine an AI advising a group of humans who are in intense competition with other groups. Due to the interaction of (i) the AI initially misunderstanding these humans’ preferences (in particular, overestimating their hawkishness) and (ii) humans’ inability to think carefully under these circumstances, discussions between the AI and humans about how to navigate the strategic situation cause humans to adopt more hawkish preferences.
Why not delegate work on conflict reduction?
One objection to doing work specific to reducing conflict between intent-aligned AIs now is that this work can be deferred to a time when we have highly capable and aligned AI assistants. We’d plausibly be able to do technical research drastically faster then. While this is a separate question to whether Intent Alignment isn't Sufficient, this is an important objection to conflict-specific work, so we briefly address it here.
Some reasons we might benefit from work on conflict reduction now, even in worlds where we get intent-aligned AGIs, include:
- We might be able to prevent locking in AI architectures that are less capable of commitment and disclosure, or train surrogate goals in a way that is credible to other AI developers;
- It may be possible for early AGI systems to lock in bad path dependencies or catastrophic conflict, such that there won’t be much time to use intent-aligned AGI assistants to help solve these problems;
- Work done on conflict now may have the instrumental benefit of making the overseers of early intent-aligned AGIs more likely to use them to do research on conflict reduction;
Still, the fact that intent-aligned AGI assistants may be able to do much of the research on conflict reduction that we would do now has important implications for prioritization. We should prioritize thinking about how to use intent-aligned assistants to reduce the risks of conflict, and deprioritize questions that are likely to be deferrable.
On the other hand, AI systems might be incorrigibly misaligned before they are in a position to substantially contribute to research on conflict reduction. We might still be able to reduce the chances of particularly bad outcomes involving misaligned AGI, without the help of intent-aligned assistants.
Intent alignment may not be necessary to reduce the risk of conflict
Whether or not Intent Alignment isn't Sufficient to prevent unendorsed conflict, we may not get intent-aligned AGIs in the first place. But it might still be possible to prevent worse-than-extinction outcomes resulting from an intent-misaligned AGI engaging in conflict. On the other hand, it seems difficult to steer a misaligned AGI’s conflict behavior in any particular direction.
Coarse-grained interventions on AIs’ preferences to make them less conflict-prone seem prima facie more likely to be effective given misalignment than trying to make more fine-grained interventions on how they approach bargaining problems (such as biasing AIs towards more cautious reasoning about commitments, as discussed previously). Let’s look at one reason to think that coarse-grained interventions on misaligned AIs’ preferences may succeed and thus that Intent Alignment isn't Necessary.
Assume that at some point during training, the AI begins 'playing the training game'. Some time before it starts playing the training game, it has started pursuing a misaligned goal. What, if anything, can we predict about the conflict-proneness of this from the AI’s training data?
A key problem is that there are many objective functions  such that trying to optimize is consistent with good early training performance, even if the agent isn’t playing the training game. However, we may not need to predict in much detail to know that a particular training regime will tend to select for more or less conflict-prone . For example, consider a 2-agent training environment, let
such that trying to optimize is consistent with good early training performance, even if the agent isn’t playing the training game. However, we may not need to predict in much detail to know that a particular training regime will tend to select for more or less conflict-prone . For example, consider a 2-agent training environment, let  be agent
be agent  ’s reward signal. Suppose we have reason to believe that a training process selects for spiteful agents, that is, agents who act as if optimizing for
’s reward signal. Suppose we have reason to believe that a training process selects for spiteful agents, that is, agents who act as if optimizing for  on the training distribution.5 This gives us reason to think that agents will learn to optimize for
on the training distribution.5 This gives us reason to think that agents will learn to optimize for  for some objectives
for some objectives  correlated with on the training distribution. Importantly, we don’t need to predict
correlated with on the training distribution. Importantly, we don’t need to predict  to worry that agent 1 will learn a spiteful objective.6
to worry that agent 1 will learn a spiteful objective.6
Concretely, imagine an extension of the SmartVault example from the ELK report, in which multiple SmartVault reporters are trained in a shared environment. And suppose that the human overseers iteratively select the SmartVault system that gets the highest reward out of several in the environment. This creates incentives for the SmartVault systems to reduce each other’s reward. It may lead to them acquiring a terminal preference for harming (some proxy for) their counterpart’s reward. But this reasoning doesn’t rest on a specific prediction about what proxies for human approval the reporters are optimizing for. As long as SmartVault1 is harming some good proxy for SmartVault2’s approval, they will be more likely to be selected. (Again, this is only true because we are assuming that the SmartVaults are not yet playing the training game.)
What this argument shows is that choosing not to reward SmartVault1 or 2 competitively eliminates a training signal towards conflict-proneness, regardless of whether either is truthful. So there are some circumstances under which we might not be able to select for truthful reporters in the SmartVault but could still avoid selecting for agents that are conflict-prone.
Human evolution is another example. It may have been difficult for someone observing human evolution to predict precisely what proxies for inclusive fitness humans would end up caring about. But the game-theoretic structure of human evolution may have allowed them to predict that, whatever proxies for inclusive fitness humans ended up caring about, they would sometimes want to harm or help (proxies for) other humans’ fitness. And other-regarding human preferences (e.g., altruism, inequity aversion, spite) do still seem to play an important role in high-stakes human conflict.
The examples above focus on multi-agent training environments. This is not to suggest that multi-agent training, or training analogous to evolution, is the only regime in which we have any hope of intervening if intent alignment fails. Even in training environments in which a single agent is being trained, it will likely be exposed to “virtual” other agents, and these interactions may still select for dispositions to help or harm other agents. And, just naively rewarding agents for prosocial behavior and punishing them for antisocial behavior early in training may still be low-hanging fruit worth picking, in the hopes that this still exerts some positive influence over agents’ mesa-objective before they start playing the training game.
Tentative conclusions about directions for research & intervention
We’ve argued that Capabilities aren't Sufficient, Intent Alignment isn't Necessary and Intent Alignment isn't Sufficient, and therefore technical work specific to AGI conflict reduction could make a difference. It could still be that alignment research is a better bet for reducing AGI conflict. But we currently believe that there are several research directions that are sufficiently tractable, neglected, and likely to be important for conflict reduction that they are worth dedicating some portion of the existential AI safety portfolio to.
First, work on using intent-aligned AIs to navigate cooperation problems. This would involve conceptual research aimed at preventing intent-aligned AIs from locking in bad commitments or other catastrophic decisions early on, and preventing the corruption of AI-assisted deliberation about bargaining. One goal of this research would be to produce a manual for the overseers of intent-aligned AGIs with instructions on how to train their AI systems to avoid the failures of cooperation discussed in this sequence.
Second, research into how to train AIs in ways that don’t select for CPPs and inflexible commitments. Research into how to detect and select against CPPs or inflexible commitments could be useful (1) if intent alignment is solved, as part of the preparatory work to enable us to better understand what cooperation failures are common for AIs and how to avoid them, or (2) if intent alignment is not solved, it can be directly used to incentivise misaligned AIs to be less conflict-prone. This could involve conceptual work on mechanisms for preventing CPPs that could survive misalignment. It might also involve empirical work, e.g., to understand the scaling of analogs of conflict-proneness in contemporary language models.
There are several tractable directions for empirical work that could support both of these research streams. Improving our ability to measure cooperation-relevant features of foundation models, and carrying out these measurements, is one. Better understanding the kinds of feedback humans give to AI systems in conflict situations, and how to improve that feedback, is another. Finally, getting practice training powerful contemporary AI systems to behave cooperatively also seems valuable, for reasons similar to those given by Ajeya in The case for aligning narrowly superhuman models.
References
- See also Paul’s Decoupling deliberation from competition.
- This may happen when an environment exhibits 'strategic substitution' (Possajennikov 2000; Bolle 2000), or if agents are selected based on their fitness relative to other agents, rather than for optimizing absolute fitness.
- On the other hand, such preferences are most likely to cause problems when they generalize to spite towards any counterpart, as opposed to a specific objective $f_2$. So we do need to have some reason to think that this generalization might happen. It might be particularly likely if the agent is trained in several different spite-inducing environments, as it is simpler to have the policy of “infer my counterpart’s preferences and harm them” than to act spitefully towards a cached $f_2$ for each environment.
- See also Paul’s Decoupling deliberation from competition.
- This may happen when an environment exhibits 'strategic substitution' (Possajennikov 2000; Bolle 2000), or if agents are selected based on their fitness relative to other agents, rather than for optimizing absolute fitness.
- On the other hand, such preferences are most likely to cause problems when they generalize to spite towards any counterpart, as opposed to a specific objective
 . So we do need to have some reason to think that this generalization might happen. It might be particularly likely if the agent is trained in several different spite-inducing environments, as it is simpler to have the policy of “infer my counterpart’s preferences and harm them” than to act spitefully towards a cached for each environment.
. So we do need to have some reason to think that this generalization might happen. It might be particularly likely if the agent is trained in several different spite-inducing environments, as it is simpler to have the policy of “infer my counterpart’s preferences and harm them” than to act spitefully towards a cached for each environment.