When does technical work to reduce AGI conflict make a difference?: Introduction
Contents
This is a pared-down version of a longer draft report. We went with a more concise version to get it out faster, so it ended up being more of an overview of definitions and concepts, and is thin on concrete examples and details. Hopefully subsequent work will help fill those gaps.
Sequence Summary
Some researchers are focused on reducing the risks of conflict between AGIs. In this sequence, we’ll present several necessary conditions for technical work on AGI conflict reduction to be effective, and survey circumstances under which these conditions hold. We’ll also present some tentative thoughts on promising directions for research and intervention to prevent AGI conflict.
- This post
- We give a breakdown of necessary conditions for technical work on AGI conflict reduction to make a difference: “AGIs won’t always avoid conflict, despite it being materially costly” and “intent alignment is either insufficient or unnecessary for conflict reduction work to make a difference.” (more)
- Would AGIs avoid conflict by default?
- To assess the claim that AGIs would figure out how to avoid conflict, we give a breakdown — which we believe is exhaustive — of the causes of conflict between rational agents. Some kinds of conflict can be avoided if the agents are sufficiently capable of credible commitment and disclosure of private information. Two barriers to preventing conflict by these means are (a) strategic pressures early in multipolar AI takeoff that make it risky to implement cooperation-improving technologies, and (b) fundamental computational hurdles to credible commitment and disclosure. Other causes of conflict — miscoordination and conflict-prone preferences — can’t be solved by credible commitment and information disclosure alone. (more)
- We give examples of technical work aimed at each of the causes of conflict surveyed in (2). (more)
- Is intent alignment necessary or sufficient to prevent unendorsed AGI conflict?
- We survey conditions under which intent-aligned AGIs could engage in conflict that is not endorsed by their overseers. Scenarios include: locking in architectures that can’t solve informational and commitment problems; the unintentional corruption of human preferences by AGIs; and catastrophes which leave human overseers unable to prevent intent-aligned AGIs from acting on misunderstandings of their preferences. (more)
- We consider whether it is possible to shape an AGI’s conflict behavior even if it is misaligned. We suggest that coarse modifications to an AI’s training distribution could make a difference by causing it to acquire a less conflict-prone (e.g., spiteful or risk-seeking) mesa-objective before it starts “playing the training game”. (more)
- We tentatively conclude that two of the most promising directions for technical research to reduce AGI conflict are (a) prescriptive work on bargaining aimed at preventing intent-aligned AIs from locking in catastrophic bargaining decisions, and (b) conceptual and empirical work on the origins of conflict-prone preferences, which we might be able to prevent even if AGI becomes misaligned at an early stage. Work on measuring and training cooperative behaviors in contemporary large language models could feed into both of these research streams. (more)
This sequence assumes familiarity with intermediate game theory.
Necessary Conditions for Technical Work on AGI Conflict to Have a Counterfactual Impact
Could powerful AI systems engage in catastrophic conflict? And if so, what are the best ways to reduce this risk? Several recent research agendas related to safe and beneficial AI have been motivated, in part, by reducing the risks of large-scale conflict involving artificial general intelligence (AGI). These include the Center on Long-Term Risk’s research agenda, Open Problems in Cooperative AI, and AI Research Considerations for Human Existential Safety (and this associated assessment of various AI research areas). As proposals for longtermist priorities, these research agendas are premised on a view that AGI conflict could destroy large amounts of value, and that a good way to reduce the risk of AGI conflict is to do work on conflict in particular. In this sequence, our goal is to assess conditions under which work specific to conflict reduction could make a difference, beyond non-conflict-focused work on AI alignment and capabilities.7
Examples of conflict include existentially catastrophic wars between AGI systems in a multipolar takeoff (e.g., 'flash war') or even between different civilizations (e.g., Sandberg 2021). We’ll assume that expected losses from catastrophic conflicts such as these are sufficiently high for this to be worth thinking about at all, and we won’t argue for that claim here.
We’ll restrict attention to technical (as opposed to, e.g., governance) interventions aimed at reducing the risks of catastrophic conflict involving AGI. These include Cooperative AI interventions, where Cooperative AI is concerned with improving the cooperative capabilities of self-interested actors (whether AI agents or AI-assisted humans).8 Candidates for cooperative capabilities include the ability to implement mutual auditing schemes in order to reduce uncertainties that contribute to conflict, and the ability to avoid conflict due to incompatible commitments (see Yudkowsky (2013); Oesterheld and Conitzer (2021); (Oesterheld and Conitzer 2021; Stastny et al. 2021)). The interventions under consideration also include improving AI systems’ ability to understand humans’ cooperation-relevant preferences. Finally, they include shaping agents’ cooperation-relevant preferences, e.g., preventing AGIs from acquiring conflict-prone preferences like spite. An overview of the kinds of interventions that we have in mind here is given in Table 1.
| Class of technical interventions specific to reducing conflict | Examples |
| Improving cooperative capabilities (Cooperative AI) |
|
| Improving understanding of humans’ cooperation-relevant preferences |
|
| Shaping cooperation-relevant preferences |
|
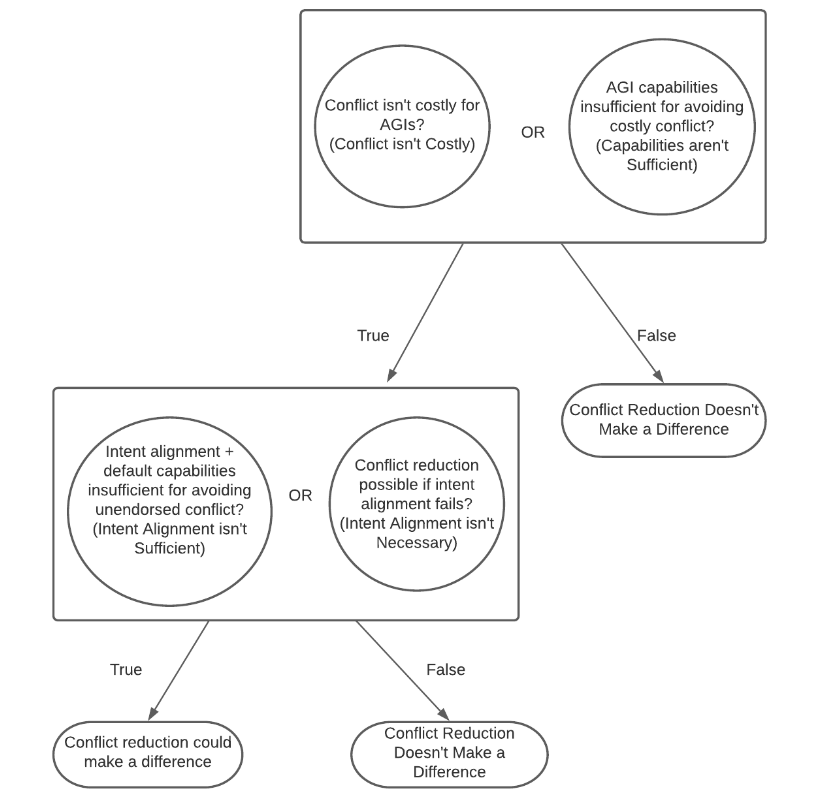
There are reasons to doubt the claim that (Technical Work Specific to) Conflict Reduction Makes a Difference.9 Conflict reduction won’t make a difference if the following conditions don’t hold: (a) AGIs won’t always avoid conflict, despite it being materially costly and (b) intent alignment is either insufficient or unnecessary for conflict reduction work to make a difference. In the rest of the sequence, we’ll look at what needs to happen for these conditions to hold.
Throughout the sequence, we will use “conflict” to refer to “conflict that is costly by our lights”, unless otherwise specified. Of course, conflict that is costly by our lights (e.g., wars that destroy resources that would otherwise be used to make things we value) are also likely to be costly by the AGIs’ lights, though this is not a logical necessity. For AGIs to fail to avoid conflict by default, one of these must be true:
Conflict isn't Costly
Conflict isn’t costly by the AGIs’ lights. That is, there don’t exist outcomes that all of the disputant AGIs would prefer to conflict.
Capabilities aren't Sufficient
AGIs that are sufficiently capable to engage in conflict that is costly for them wouldn’t also be sufficiently capable to avoid conflict that is costly for them.10
If either Conflict isn't Costly or Capabilities aren't Sufficient, then it may be possible to reduce the chances that AGIs engage in conflict. This could be done by improving their cooperation-relevant capabilities or by making their preferences less prone to conflict. But this is not enough for Conflict Reduction Makes a Difference to be true.
Intent alignment may be both sufficient and necessary to reduce the risks of AGI conflict that isn’t endorsed by human overseers, insofar as it is possible to do so. If that were true, technical work specific to conflict reduction would be redundant. This leads us to the next two conditions that we’ll consider.
Intent Alignment isn't Sufficient
Intent alignment — i.e., AI systems trying to do what their overseers want — combined with the capabilities that AI systems are very likely to have conditional on intent alignment, isn’t sufficient for avoiding conflict that is not endorsed (on reflection) by the AIs’ overseers.
Intent Alignment isn't Necessary
Even if intent alignment fails, it is still possible to intervene on an AI system to reduce the risks of conflict. (We may still want to prevent conflict if intent alignment fails and leads to an unrecoverable catastrophe, as this could make worse-than-extinction outcomes less likely.)
By unendorsed conflict, we mean conflict caused by AGIs that results from a sequence of decisions that none of the AIs’ human principals would endorse after an appropriate process of reflection.11 The reason we focus on unendorsed conflict is that we ultimately want to compare (i) conflict-specific interventions on how AI systems are designed and (ii) work on intent alignment.
Neither of these is aimed at solving problems that are purely about human motivations, like human overseers instructing their AI systems to engage in clearly unjustified conflict.
Note on scope
Contrary to what our framings here might suggest, disagreements about the effectiveness of technical work to reduce AI conflict relative to other longtermist interventions are unlikely to be about the logical possibility of conflict reduction work making a difference. Instead, they are likely to involve quantitative disagreements about the likelihood and scale of different conflict scenarios, the degree to which we need AI systems to be aligned to intervene on them, and the effectiveness of specific interventions to reduce conflict (relative to intent alignment, say). We regard mapping out the space of logical possibilities for conflict reduction to make a difference as an important initial step in the longer-term project of assessing the effectiveness of technical work on conflict reduction.12
Acknowledgments
Thanks to Michael Aird, Jim Buhler, Steve Byrnes, Sam Clarke, Allan Dafoe, Daniel Eth, James Faville, Lukas Finnveden, Lewis Hammond, Julian Stastny, Daniel Kokotajlo, David Manheim, Rani Martin, Adam Shimi, Stefan Torges, and Francis Ward for comments on drafts of this sequence. Thanks to Beth Barnes, Evan Hubinger, Richard Ngo, and Carl Shulman for comments on a related draft.
References
Stastny, Julian, Maxime Riché, Alexander Lyzhov, Johannes Treutlein, Allan Dafoe, and Jesse Clifton. 2021. “Normative Disagreement as a Challenge for Cooperative AI.” arXiv [cs.MA]. arXiv. http://arxiv.org/abs/2111.13872.
- There are potential downsides to improving AGI cooperation, such as improving AIs’ ability to collude at the expense of humans. Analyzing these potential downsides is beyond the scope of this sequence, but should enter into an overall assessment of the value of the directions for research and intervention discussed here.
- The goal of Cooperative AI is not to make agents prosocial. It is concerned with helping agents to more effectively cooperate, holding their preferences fixed. (However, Cooperative AI research could help self-interested principals of AI systems to credibly commit to building prosocial agents, which would be an instance of improving the principals’ cooperative capabilities.)
- See here and here for some recent discussion related to the merits of working on AGI cooperation, for example.
- Thanks to Allan Dafoe for discussion of the related “Super-cooperative AGI hypothesis”, which he coined to refer to “the hypothesis that sufficiently advanced AI will be extremely capable at cooperating with other advanced AIs” (private communication).
- This is a vague definition and there are thorny issues around what it means for something to be “endorsed after an appropriate process of reflection”. See here for a recent discussion, for instance. Nevertheless, for the purposes of distinguishing between what can be achieved by technical interventions on AI systems as opposed to the motivations of human overseers, it seems difficult to avoid invoking this concept. But, we will try to discuss examples that involve behavior that would be obviously unendorsed after appropriate reflection (even if it is endorsed at the time).
- We can draw an analogy here with the shift in arguments around AGI alignment. Early work (for example Superintelligence) made the orthogonality and instrumental convergence theses prominent, because it was focused on arguing for the possibility of misaligned AI and rejecting reasons to think that misalignment was impossible or incoherent. Now, most discussion has moved onto more detailed technical reasons to expect misalignment.
- There are potential downsides to improving AGI cooperation, such as improving AIs’ ability to collude at the expense of humans. Analyzing these potential downsides is beyond the scope of this sequence, but should enter into an overall assessment of the value of the directions for research and intervention discussed here.
- The goal of Cooperative AI is not to make agents prosocial. It is concerned with helping agents to more effectively cooperate, holding their preferences fixed. (However, Cooperative AI research could help self-interested principals of AI systems to credibly commit to building prosocial agents, which would be an instance of improving the principals’ cooperative capabilities.)
- See here and here for some recent discussion related to the merits of working on AGI cooperation, for example.
- Thanks to Allan Dafoe for discussion of the related “Super-cooperative AGI hypothesis”, which he coined to refer to “the hypothesis that sufficiently advanced AI will be extremely capable at cooperating with other advanced AIs” (private communication).
- This is a vague definition and there are thorny issues around what it means for something to be “endorsed after an appropriate process of reflection”. See here for a recent discussion, for instance. Nevertheless, for the purposes of distinguishing between what can be achieved by technical interventions on AI systems as opposed to the motivations of human overseers, it seems difficult to avoid invoking this concept. But, we will try to discuss examples that involve behavior that would be obviously unendorsed after appropriate reflection (even if it is endorsed at the time).
- We can draw an analogy here with the shift in arguments around AGI alignment. Early work (for example Superintelligence) made the orthogonality and instrumental convergence theses prominent, because it was focused on arguing for the possibility of misaligned AI and rejecting reasons to think that misalignment was impossible or incoherent. Now, most discussion has moved onto more detailed technical reasons to expect misalignment.