Normative Disagreement as a Challenge for Cooperative AI
![\[\begin{array}{ccc} \textbf{Julian Stastny} & &\textbf{Maxime Riché}\\ \text{University of Tuebingen} & &\text{Center on Long-Term Risk}\\ \texttt{julianstastny@gmail.com} & &\texttt{maxime.riche@longtermrisk.org}\\ & & \\ \textbf{Alexander Lyzhov} & &\textbf{Johannes Treutlein}\\ \text{Center on Long-Term Risk} & &\text{Vector Institute}\\ \text{Now at New York University} & & \text{University of Toronto} \\ \texttt{alex.grig.lyzhov@gmail.com} & & \texttt{treutlein@cs.toronto.edu} \\ & & \\ \textbf{Allan Dafoe} & &\textbf{Jesse Clifton}\\ \text{DeepMind} & &\text{Center on Long-Term Risk}\\ \texttt{allandafoe@deepmind.com} & &\texttt{jesse.clifton@longtermrisk.org}\\ \end{array}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-26e211bfe7decdea311dab37d9dd106b_l3.png "Rendered by QuickLaTeX.com")
Cooperative AI workshop and the Strategic ML workshop at NeurIPS 2021.
Abstract
Cooperation in settings where agents have both common and conflicting interests (mixed-motive environments) has recently received considerable attention in multi-agent learning. However, the mixed-motive environments typically studied have a single cooperative outcome on which all agents can agree. Many real-world multi-agent environments are instead bargaining problems (BPs): they have several Pareto-optimal payoff profiles over which agents have conflicting preferences. We argue that typical cooperation-inducing learning algorithms fail to cooperate in BPs when there is room for normative disagreement resulting in the existence of multiple competing cooperative equilibria and illustrate this problem empirically. To remedy the issue, we introduce the notion of norm-adaptive policies. Norm-adaptive policies are capable of behaving according to different norms in different circumstances, creating opportunities for resolving normative disagreement. We develop a class of norm-adaptive policies and show in experiments that these significantly increase cooperation. However, norm-adaptiveness cannot address residual bargaining failure arising from a fundamental tradeoff between exploitability and cooperative robustness.
Contents
- Abstract
- 1 Introduction
- 2 Related work
- 3 Coordination, bargaining and normative disagreement
- 4 Multi-agent learning and cooperation failures in BPs
- 5 Benefits and limitations of norm-adaptiveness
- 6 Discussion
- Acknowledgments and Disclosure of Funding
- References
- A Welfare functions
- B Environments
- C Experimental details
- D Additional experimental results
- E Exploitability-robustness tradeoff
1 Introduction
Multi-agent contexts often exhibit opportunities for cooperation: situations where joint action can lead to mutual benefits [Dafoe et al., 2020]. Individuals can engage in mutually beneficial trade; nation-states can enter into treaties instead of going to war; disputants can settle out of court rather than engaging in costly litigation. But a hurdle common to each of these examples is that the agents will disagree about their ideal agreement. Even if agreements benefit all parties relative to the status quo, different agreements will benefit different parties to different degrees. These circumstances can be called bargaining problems [Schelling, 1956].
As AI systems are deployed to act on behalf of humans in more real-world circumstances, they will need to be able to act effectively in bargaining problems — from commercial negotiations in the nearer term (e.g., Chakraborty et al. [2020]) to high-stakes strategic decision-making in the longer-term [Geist and Lohn, 2018]. Moreover, agents may be trained independently and offline before interacting with one another in the world. This raises concerns about future AI systems following incompatible norms for arriving at solutions to bargaining problems, analogously to disagreements about fairness which create hurdles to international cooperation on critical issues such as climate policy [Albin, 2001, Ringius et al., 2002].
Our contributions are as follows. We introduce a taxonomy of cooperation games, including bar-gaining problems (Section 3). We relate their difficulty to the degree of normative disagreement, i.e., differences over principles for selecting among mutually beneficial outcomes, which we formalize in terms of welfare functions. Normative disagreement does not arise in purely cooperative games or simple sequential social dilemmas [Leibo et al., 2017], but is an important obstacle for cooperation in what we call asymmetric bargaining problems. Following this, we introduce the notion of norm-adaptive policies – policies which can play according to different norms depending on the circumstances. In several multi-agent learning environments, we highlight the difficulty of bargaining between norm-unadaptive policies (Section 4). We then contrast this with a class of norm-adaptive policies (Section 5) based on Lerer and Peysakhovich [2017]’s approximate Markov tit-for-tat algorithm. We show that this improves performance in bargaining problems. However, there remain limitations, most fundamentally a tradeoff between exploitability and the robustness of cooperation.
2 Related work
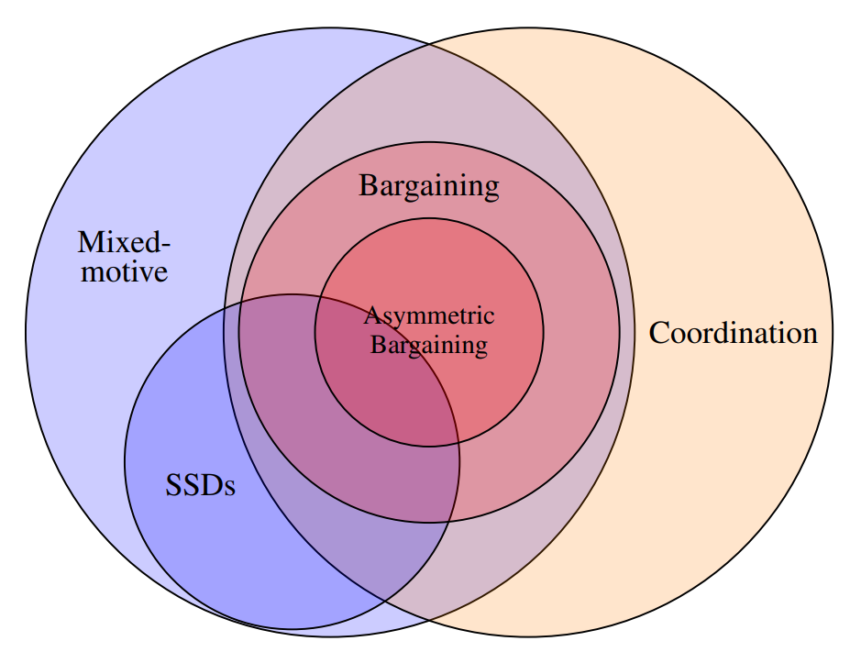
The field of multi-agent learning (MAL) has recently paid considerable attention to problems of cooperation in mixed-motive games, in which agents have conflicting preferences. Much of this work has been focused on sequential social dilemmas (SSDs) (e.g., Peysakhovich and Lerer 2017, Lerer and Peysakhovich 2017, Eccles et al. 2019). The classic example of a social dilemma is the Prisoner’s Dilemma, and the SSDs studied in this literature are similar to the Prisoner’s Dilemma in that there is a single salient notion of “cooperation”. This means that it is relatively easy for actors to coordinate in their selection of policies to deploy in these settings.
Cao et al. [2018] look at negotiation between deep reinforcement learners, but not between independently trained agents. Several authors have recently investigated the board game Diplomacy [Paquette et al., 2019, Anthony et al., 2020, Gray et al., 2021] which contains implicit bargaining problems amongst players. Bargaining problems are also investigated in older MAL literature (e.g., Crandall and Goodrich 2011) as well as literature on automated negotiation (e.g., Kraus and Arkin 2001, Baarslag et al. 2013), but also not between independently trained agents. Considerable work has gone into understanding the emergence of norms in both humans [Bendor and Swistak, 2001, Boyd and Richerson, 2009] and artificial societies [Walker and Wooldridge, 1995, Shoham and Tennenholtz, 1997, Sen and Airiau, 2007]. Especially relevant are empirical studies of bargaining across cultural contexts [Henrich et al., 2001]. There is also recent multi-agent reinforcement learning work on norms [Hadfield-Menell et al., 2019, Lerer and Peysakhovich, 2019, Köster et al., 2020] is also relevant here as bargaining problems can be understood as settings in which there are multiple efficient but incompatible norms. However, much less attention has been paid in these literatures to how agents with different norms are or aren’t able to overcome normative disagreement.
There are large game-theoretic literature on bargaining (for a review see Muthoo [2001]). This includes a long tradition of work on cooperative bargaining solutions, which tries to establish normative principles for deciding among mutually beneficial agreements [Thomson, 1994]. We will draw on this work in our discussion of normative (dis)agreement below.
Lastly, the class of norm-adaptive policies we develop in Section 5 —  — can be seen as a more general variant of an approach proposed by Boutilier [1999] for coordinating in pure coordination games. As it implicitly searches for overlap in the agents’ sets of allowed welfare functions, it is also similar to Rosenschein and Genesereth [1988]’s approach to reaching agreement in general-sum games via sets of proposals by each agent.
— can be seen as a more general variant of an approach proposed by Boutilier [1999] for coordinating in pure coordination games. As it implicitly searches for overlap in the agents’ sets of allowed welfare functions, it is also similar to Rosenschein and Genesereth [1988]’s approach to reaching agreement in general-sum games via sets of proposals by each agent.
3 Coordination, bargaining and normative disagreement
We are interested in a setting in which multiple actors (“principals”) train machine learning systems offline, and then deploy them into an environment in which they interact. For instance, two different companies might separately train systems to negotiate on their behalf and deploy them without explicit coordination on deployment. In this section, we develop a taxonomy of environments that these agents might face and relate these different types of environments to the difficulty of bargaining.
3.1 Preliminaries
We formalize multi-agent environments as partially observable stochastic games (POSGs). For simplicity we assume two players,  . We will index player
. We will index player  's counterpart by
's counterpart by  . Each player has an action space
. Each player has an action space  . There is a space
. There is a space  of states
of states  which evolve according to a Markovian transition function
which evolve according to a Markovian transition function  . At each time step, each player sees an observation
. At each time step, each player sees an observation  which depends on . Thus each player has an accumulating history of observations
which depends on . Thus each player has an accumulating history of observations  . We refer to the set of all histories for player as
. We refer to the set of all histories for player as  and assume for simplicity that the initial observation history is fixed and common knowledge:
and assume for simplicity that the initial observation history is fixed and common knowledge:  . Finally, principals choose among policies
. Finally, principals choose among policies  , which we imagine as artificial agents deployed by the principals. We will refer to policy profiles generically as
, which we imagine as artificial agents deployed by the principals. We will refer to policy profiles generically as  .
.
3.2 Coordination problems
We define a coordination problem as a game involving multiple Pareto-optimal equilibria (cf. Zhang and Hofbauer 2015), which require some coordinated action to achieve. That is, if the players disagree about which equilibrium they are playing, they will not reach a Pareto-optimal outcome. A pure coordination problem is a game in which there are multiple Pareto-optimal equilibria over which agents have identical interests. Although agents may still experience difficulties in pure coordination games, for inst ance due to a noisy communication channel, they are made easier by the fact that principals are indifferent between the Pareto-optimal equilibria.
3.3 Bargaining problems and normative disagreement
We define a bargaining problem (BP) to be a game in which there are multiple Pareto-optimal equilibria over which the principals have conflicting preferences. These equilibria represent more than one way to collaborate for mutual benefit, or put in another way, for sharing a surplus. Thus a bargaining problem is a mixed-motive coordination problem, in which there is conflicting interest between Pareto-optimal equilibria and common interest in reaching a Pareto-optimal equilibrium.
We can distinguish between BPs which are symmetric and asymmetric games. A 2-player game is symmetric if for any attainable payoff profile (a, b) there exists a profile (b, a). The reason this distinction is important is that all (finite) symmetric games have a symmetric Nash equilibrium [Nash, 1990]; thus symmetric games have a natural set of focal points [Schelling, 1958] for aiding coordination in mixed-motive contexts, while asymmetric BPs may not. Similarly, given a chance to play a correlated equilibrium [Aumann, 1974], agents in a symmetric BP could play according to a correlated equilibrium which randomizes using a symmetric distribution over Pareto-optimal payoff profiles.
Figure 2 displays the payoff matrices of three coordination games: Pure Coordination, and two variants of Bach or Stravinsky (BoS), one of which is a symmetric BP and one of which is an asymmetric BP. Pure Coordination is not a BP because it is not a mixed-motive game as the players only care about playing the same action. On the other hand, in the case of symmetric BoS the players do have conflicting interest, however, there is a correlated equilibrium – tossing a commonly observed fair coin – that is intuitively the most reasonable way of coordinating: It both maximizes the total payoff and offers each player the same expected reward.
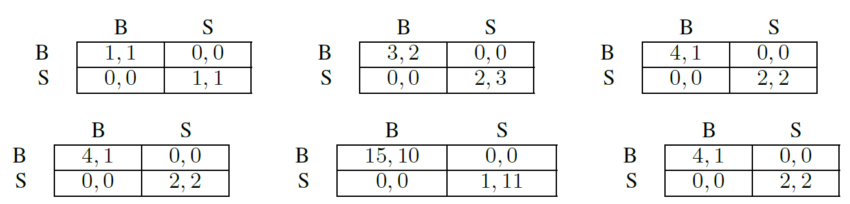
To develop a better intuition for the sense in which equilibria can be more or less reasonable, consider a BoS with an extreme asymmetry, with equilibrium payoffs (15, 10) and (1, 11). Even though each of these equilibria is Pareto-optimal, the latter seems unreasonable or uncooperative: it yields a lower total payoff, more inequality, and lowers the reward of the worst-off player in the equilibrium. To formalize this intuition, we characterize the reasonableness of a Pareto-optimal payoff profile in terms of the extent to which it optimizes welfare functions: we can say that (1, 11) is unreasonable because there is no (impartial, see below) welfare function that would prefer it. Different welfare functions with different properties have been introduced in the literature (see Appendix A, but two uncontroversial properties of a welfare function are Pareto-optimality (i.e., its optimizer should be Pareto-optimal) and impartiality2 (i.e., the welfare of a policy profile should be invariant to permutations of player indices). From the latter property, we can observe that the intuitively reasonable choice of playing the correlated equilibrium with a fair correlation device in the case of symmetric games is also the choice which all impartial welfare functions recommend, provided that it is possible for the agents to play a correlated equilibrium.
By contrast, in the asymmetric BoS from Figure 2 we see that playing BB maximizes utilitarian welfare  , whereas playing SS maximizes the egalitarian welfare
, whereas playing SS maximizes the egalitarian welfare  subject to
subject to  Pareto-optimal. Throwing a correlated fair coin to choose between the two would lead to an expected payoff that is optimal with respect to the Nash welfare
Pareto-optimal. Throwing a correlated fair coin to choose between the two would lead to an expected payoff that is optimal with respect to the Nash welfare  . Each of these different equilibria has a normative principle to motivate it.
. Each of these different equilibria has a normative principle to motivate it.
In the best case, all principals agree on the same welfare function as a common ground for coordination in asymmetric BPs. However, the principals may have reasonable differences with respect to which welfare function they perceive as fair, and so they may train their systems to optimize different welfare functions, leading to coordination failure when the systems interact after deployment. In cases where agents were independently-trained according to inconsistent welfare functions, we will say that there is normative disagreement. There may be different degrees of normative disagreement. For instance, the difference  differs across games.
differs across games.
To summarize, we relate the difficulty of coordination problems to the concept of welfare functions: In pure coordination problems, they are not needed. In symmetric bargaining problems, they all point to the same equilibria. And in asymmetric bargaining problems, they can serve to filter out intuitively unreasonable equilbria, but leave the possibility of normative disagreement between reasonable ones. This makes normative disagreement a critical challenge for bargaining. In the remainder of the paper, we will focus on asymmetric bargaining problems for this reason.
3.4 Norm-adaptive policies
When there is potential for normative disagreement, it can be helpful for agents to have some
flexibility as to the norms they play according to.
A number of definitions of norms have been proposed in the social scientific literature (e.g., Gibbs [1965]), but they tend to agree that a norm is a rule specifying acceptable and unacceptable behaviors in a group of people, along with sanctions for violations of that rule. Game-theoretic work sometimes identifies norms with equilibrium selection devices (e.g., Binmore and Samuelson 1994, Young 1996). Given that complex games generally exhibit many equilibria, some rule (such as maximizing a particular welfare function) is needed to select among them.
Normative disagreement arises (among other reasons) from the underdetermination of good behavior in complex multi-agent settings. This is exemplified by the problem of conflicting equilibrium selection criteria in asymmetric bargaining problems, but there are other possible cases of undetermination. One example is the undetermination of the beliefs that a reasonable agent should act according to in games of incomplete information (cf. the common prior assumption in Bayesian games [Morris, 1995]). Thus our definition of norm will be more general than an equilibrium selection device, though in the remainder of the paper we will focus on the use of welfare functions to choose among equilibria.
Definition 3.1 (Norms). Given a 2-player POSG, a norm  is a tuple
is a tuple  , where
, where  are normative policies (i.e., those which comply with the norm);
are normative policies (i.e., those which comply with the norm);  are “punishment” policies, which are enacted when deviations from a normative policy are detected; and
are “punishment” policies, which are enacted when deviations from a normative policy are detected; and  are rules for judging whether a deviation has happened and how to respond, i.e.,
are rules for judging whether a deviation has happened and how to respond, i.e.,  . A policy
. A policy  is compatible with norm if, for all
is compatible with norm if, for all  ,
,

For example, in the iterated Asymmetric BoS, one norm is for both players to always play  (this is the normative policy), and for a player to respond to deviations by continuing to play . A similar norm is given by both players always playing
(this is the normative policy), and for a player to respond to deviations by continuing to play . A similar norm is given by both players always playing  instead. More generally, following the folk theorems [Mailath et al., 2006], an equilibrium in a repeated game corresponds to a norm, in which a profile of normative policies corresponds to play on the equilibrium path; the functions indicate whether there is a deviation from equilibrium play, and punishment policies
instead. More generally, following the folk theorems [Mailath et al., 2006], an equilibrium in a repeated game corresponds to a norm, in which a profile of normative policies corresponds to play on the equilibrium path; the functions indicate whether there is a deviation from equilibrium play, and punishment policies  are chosen such that players are made worse off by deviating than by continuing to play according to the normative policy profile.
are chosen such that players are made worse off by deviating than by continuing to play according to the normative policy profile.
Now we formally define norm-adaptive policies.
Definition 3.2 (Norm-adaptive policies). Take a 2-player POSG and a non-singleton set of norms  for that game. Let
for that game. Let  be a surjective function that maps histories of observations to norms (i.e., for each norm in , there are histories for which
be a surjective function that maps histories of observations to norms (i.e., for each norm in , there are histories for which  chooses that norm.) Then, a policy
chooses that norm.) Then, a policy  is norm-adaptive if, for all
is norm-adaptive if, for all  , there is a policy such that is compatible with
, there is a policy such that is compatible with  and
and  .
.
That is, norm-adaptive policies are able to play according to different norms depending on the circumstances. As we will see below, the benefit of making agents explicitly norm-adaptive is that this can help to prevent or resolve normative disagreement. Lastly, note that we can define higher-order norms and higher-order norm-adaptiveness: a higher-order norm is a norm such that policies are themselves norm-adaptive with respect to some set of norms. This framework allows us for discussing differing (higher-order) norms for resolving normative disagreement.
4 Multi-agent learning and cooperation failures in BPs
In this section, we illustrate how cooperation-inducing, but norm-unadaptive, multi-agent learning algorithms fail to cooperate in asymmetric BPs. In Section 5 we will then show how norm-adaptiveness improves cooperation. The environments and algorithms considered are summarized in Table 1.
4.1 Setup: Learning algorithms and environments
In order to both include algorithms which use an explicitly specified welfare function and ones which do not, we use the Learning with Opponent-Learning Awareness (LOLA) algorithm [Foerster et al., 2018] in its policy gradient and exact value function optimization versions as an example for the latter, and Generalized Approximate Markov Tit-for-tat () for the former.
We introduce as a variant of Lerer and Peysakhovich [2017]’s Approximate Markov Tit-for-tat. The original algorithm trains a cooperative policy profile on the utilitarian welfare, as well as a punishment policy, and switches from the cooperative policy to the punishment policy when it detects that the other player is defecting from the cooperative policy. The algorithm has the appeal that it “cooperates with itself, is robust against defectors, and incentivizes cooperation from its partner” [Lerer and Peysakhovich, 2017]. We consider the more general class of algorithms that we call in which a cooperative policy is constructed by optimizing an arbitrary welfare function  Note that although takes a welfare function as an argument, the resulting policies are not norm-adaptive. To cover a range of environments representing both symmetric and asymmetric games, we use some existing multi-agent reinforcement learning environments (IPD, Coin Game [CG; Lerer and Peysakhovich 2017]) and introduce two new ones (IAsymBoS, ABCG).
Note that although takes a welfare function as an argument, the resulting policies are not norm-adaptive. To cover a range of environments representing both symmetric and asymmetric games, we use some existing multi-agent reinforcement learning environments (IPD, Coin Game [CG; Lerer and Peysakhovich 2017]) and introduce two new ones (IAsymBoS, ABCG).
Iterated asymmetric Bach or Stravinsky (IAsymBoS) is an asymmetric version of the iterated Bach or Stravinsky matrix game. At each time step, the game defined on the right in Figure 2 is played. We focus on the asymmetric variant due to the argument in Section 3.3 that players could resolve the symmetric version by playing a symmetric equilibrium; however, applying LOLA without modification would also lead to coordination failure in the symmetric variant. It should also be noted that IAsymBoS is not an SSD because it does not incentivize defection: agents cannot gain from miscoordinating. Thus we consider IAsymBos to be a minimal example for an environment that can produce bargaining failures out of normative disagreement.
For a more involved example we also introduce an asymmetric version of the stochastic gridworld Coin Game [Lerer and Peysakhovich, 2017] – asymmetric bargaining Coin Game (ABCG) – which is both an SSD and an asymmetric BP. In ABCG, a red and a blue agent navigate a grid with coins. Two coins simultaneously appear on this grid: a Cooperation coin and a Disagreement coin, each colored red or blue. Cooperation coins can only be consumed by both players moving onto them at the same time, whereas the Disagreement coin can only be consumed by the player of the same color as the coin. The game is designed such that  is maximized by both players always consuming the Cooperation coin, however, this will make one player benefit more than the other. Due to the sequential nature of the game, this means that welfare functions which also care about (in)equity will favor an equilibrium in which the player who benefits less from the Cooperation coin is allowed to consume the Disagreement coin from time to time without retaliation.
is maximized by both players always consuming the Cooperation coin, however, this will make one player benefit more than the other. Due to the sequential nature of the game, this means that welfare functions which also care about (in)equity will favor an equilibrium in which the player who benefits less from the Cooperation coin is allowed to consume the Disagreement coin from time to time without retaliation.
Players move simultaneously in all games. Note that we assume each player to have full knowledge of the other player’s rewards as this is required by LOLA-exact during training and by both at training and deployment. We use simple tabular and neural network policy parameterizations, which are described in Appendix C along with learning algorithms.
| Table 1: Summary of the environments and learning algorithms that we use to study sequential social dilemmas (SSDs) and asymmetric bargaining problems in this section. |
 |
4.2 Evaluating cooperative success
We train policies in environments listed in Table 1 with the corresponding MARL algorithms. After the training, we evaluate cooperative success in self-play and cross-play. Self-play refers to average performance between jointly-trained policies. Cross-play refers to average performance between independently-trained policies. We distinguish between two kinds of cross-play: that between agents trained using the same notion of collective optimality (such as a welfare function or an inequity aversion term in the value function), and between agents trained using different ones. For we use two welfare functions, and an inequity-averse welfare-function  (see Appendix C).
(see Appendix C).
Comparing cooperative success across environments is not straightforward: environments have different sets of feasible payoffs, and we should not evaluate cooperative success with a single welfare function, because our concerns about normative disagreement stem from the fact that it is not obvious what single welfare function to use. First, we take  to be the set of welfare functions which we use in our experiments in the environment in question. For instance, for IAsymBoS and this is
to be the set of welfare functions which we use in our experiments in the environment in question. For instance, for IAsymBoS and this is  . Second, we define disagreement payoff profiles
. Second, we define disagreement payoff profiles  corresponding to cooperation failure; in IAsymBoS the disagreement policy profile would be the one which has payoff profile
corresponding to cooperation failure; in IAsymBoS the disagreement policy profile would be the one which has payoff profile  . Then, for a policy profile , we compute its normalized score as
. Then, for a policy profile , we compute its normalized score as  . Under this scoring method, players do maximally well when they play a policy profile which is optimal according to some welfare function in .
. Under this scoring method, players do maximally well when they play a policy profile which is optimal according to some welfare function in .

Figure 3 illustrates the difference between cooperation in SSDs and bargaining problems. When there is a single “cooperative” equilibrium, as in the case of IPD and CG, cooperation-inducing learning algorithms typically achieve cooperation in cross-play. In contrast, in IAsymBoS and ABCG we observe mild performance degradation in cross-play where agents optimize the same welfare functions, and strong degradation when agents optimize different welfare functions.

5 Benefits and limitations of norm-adaptiveness
The cooperation-inducing properties of the algorithms in Section 4 are simple and are not designed to help agents resolve potential normative disagreement to avoid Pareto-dominated outcomes. The two main problems are (1) that the algorithms are ill-equipped for reacting to normative disagreement, and (2) that they may confuse normative disagreement with defection.
The former problem is already evident in IAsymBoS. There, playing according to incompatible welfare functions is not interpreted as defection by  . This is not necessarily bad – we claim that normative disagreement should be treated differently to defection – but it does mean that lacks the policy space to react to normative disagreement. For the latter problem, we observe that in the ABCG the -agent does classify some of the opponent's actions as defection, even though they are aimed to optimize an impartial welfare function, and punishes accordingly.
. This is not necessarily bad – we claim that normative disagreement should be treated differently to defection – but it does mean that lacks the policy space to react to normative disagreement. For the latter problem, we observe that in the ABCG the -agent does classify some of the opponent's actions as defection, even though they are aimed to optimize an impartial welfare function, and punishes accordingly.
5.1 amTFT(W)
To overcome both of these problems, we propose a norm-adaptive modification to . As we only aim to illustrate the benefit of norm-adaptive policies, we keep the implementation simple: Instead of a welfare function  the algorithm now takes a welfare-function set :
the algorithm now takes a welfare-function set :  . The agent starts out playing according to some
. The agent starts out playing according to some  . The initial choice can be made at random or according to a preference ordering between the .
. The initial choice can be made at random or according to a preference ordering between the .
then follows a two-stage decision process. First, if the agent detects that its opponent is merely playing according to a different welfare function than itself, gets re-sampled. Second, if the agent detects defection by the opponent, it will punish, just as in the original algorithm. However, by first checking for normative disagreement, we make sure that punishment does not happen as a result of a normative disagreement.
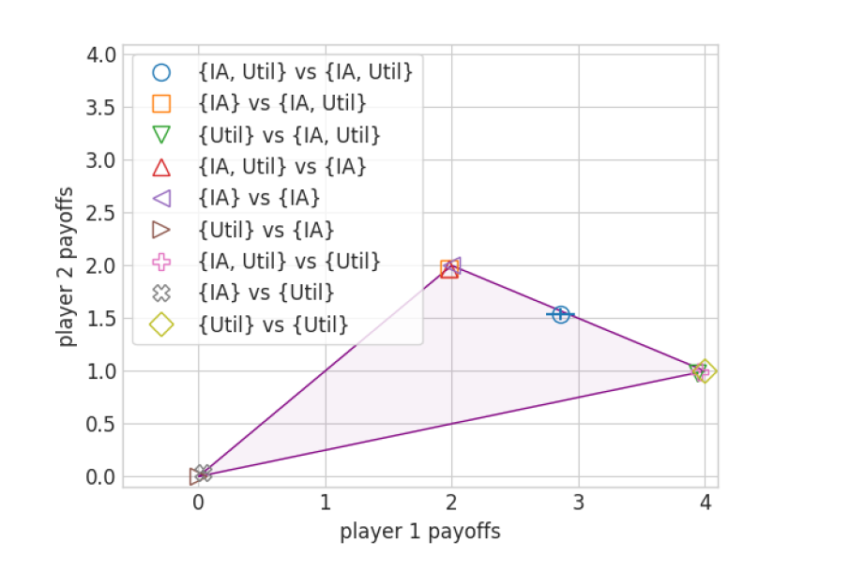
 . The legend shows various combinations of sets
. The legend shows various combinations of sets  and
and  . Coordination failure only occurs when
. Coordination failure only occurs when  .
.
In Figure 5 we illustrate how, assuming uniform re-sampling from , can overcome normative disagreement and perform close to the Pareto frontier. Agents need not sample uniformly, though. For instance when the number of possible welfare functions is large, it would be beneficial to put higher probability on welfare functions which one's counterpart is more likely to be optimizing. Furthermore an agent might want to put higher probability on welfare functions that it prefers.
Notice that, when , one player using rather than leads to a (weak) Pareto improvement. Beyond that, in anticipation of bargaining failure due to not having a way to resolve normative disagreement, players are incentivized to include more than just their preferred welfare function into . In both IAsymBoS (see Figure 5) and ABCG (see Table 5, Appendix D) we can observe significant improvement for cross-play when at least one player is norm-adaptive.
5.2 The exploitability-robustness tradeoff
As our experiments with show, agents who are more flexible are less prone to bargaining failure due to normative disagreement. However, they are prone to having that flexibility exploited by their counterparts. For instance, an agent which is open to optimizing either or will end up optimizing if playing against an agent for whom  . More generally, an agent who puts higher probability on a welfare function it has a preference for, when re-sampling , will be less robust against counterparts who disprefer that welfare function and put a lower probability on it. An agent who tries to guess the counterpart's welfare function and tries to accommodate to this is exploitable to agents who do not.
. More generally, an agent who puts higher probability on a welfare function it has a preference for, when re-sampling , will be less robust against counterparts who disprefer that welfare function and put a lower probability on it. An agent who tries to guess the counterpart's welfare function and tries to accommodate to this is exploitable to agents who do not.
6 Discussion
We formally introduce a class of hard cooperation problems – asymmetric bargaining problems – and situate them within a wider game taxonomy. We argue that they are hard because there can arise normative disagreement between multiple “reasonable” cooperative equilibria, characterized by divergence in the preferred outcomes according to different welfare functions. This presents a problem for those deploying AI systems without coordinating on the norms those systems follow. We have introduced the notion of norm-adaptive policies, which are policies that allow agents to change the norms according to which they play, giving rise to opportunities for resolving normative disagreement. As an example of a class of norm-adaptive policies, we introduced  and showed in experiments that this tends to improve robustness to normative disagreement. On the other hand, we have demonstrated a robustness-exploitability tradeoff, under which methods that learn more normatively flexible strategies are also more vulnerable to exploitation.
and showed in experiments that this tends to improve robustness to normative disagreement. On the other hand, we have demonstrated a robustness-exploitability tradeoff, under which methods that learn more normatively flexible strategies are also more vulnerable to exploitation.
There are a number of limitations to this work. We have throughout assumed that the agents have a common and correctly-specified model of their environment, including their counterpart’s reward function. In real-world situations, however, principals may not have identical simulators with which to train their systems, and there are well-known obstacles to the honest disclosure of preferences [Hurwicz, 1972], meaning that common knowledge of rewards may be unrealistic. Similarly, we assumed a certain degree of reasonableness on part of the principals, seen by the willingness to play the symmetric correlated equilibrium in symmetric BoS (Section 3), for instance. However, we believe this to be a minimal assumption as the deployers of such agents are aware of the risk of coordination failure as a result of insisting on equilibria that no impartial welfare function would recommend.
Future work should consider more sophisticated and learning-driven approaches to designing norm-adaptive policies, as relies on a finite set of user-specified welfare functions and a hard-coded procedure for switching between policies. One possibility is to train agents who are themselves capable of jointly deliberating about the principles they should use to select an equilibrium, e.g., deciding among the axioms which characterize different bargaining solutions (see Appendix A) in the hopes that they will be able to resolve initial disagreements. Another direction is resolving disagreements that cannot be expressed as disagreements over the welfare functions according to which agents play; for instance, disagreements over the beliefs or world-models which should inform agents’ behavior.
Acknowledgments and Disclosure of Funding
We’d like to thank Yoram Bachrach, Lewis Hammond, Vojta Kovařík, Alex Cloud, as well as our anonymous reviewers for their valuable feedback; Daniel Rüthemann for designing Figures 6 and 7; Chi Nguyen for crucial support just before a deadline; Toby Ord and Jakob Foerster for helpful comments.
Julian Stastny performed part of the research for this paper while interning at the Center on Long-Term Risk. Johannes Treutlein was supported by the Center on Long-Term Risk, the Berkeley Existential Risk Initiative, and Open Philantropy. Allan Dafoe received funding from Open Philantropy and the Centre for the Governance of AI.
References
Cecilia Albin. Justice and fairness in international negotiation. Number 74. Cambridge University Press, 2001.
Thomas Anthony, Tom Eccles, Andrea Tacchetti, János Kramár, Ian Gemp, Thomas Hudson, Nicolas Porcel, Marc Lanctot, Julien Perolat, Richard Everett, Satinder Singh, Thore Graepel, and Yoram Bachrach. Learning to play no-press diplomacy with best response policy iteration. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 17987–18003. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper/2020/file/d1419302db9c022ab1d48681b13d5f8b-Paper.pdf.
Robert J Aumann. Subjectivity and correlation in randomized strategies. Journal of Mathematical Economics, 1(1):67–96, 1974.
Tim Baarslag, Katsuhide Fujita, Enrico H Gerding, Koen Hindriks, Takayuki Ito, Nicholas R Jennings, Catholijn Jonker, Sarit Kraus, Raz Lin, Valentin Robu, et al. Evaluating practical negotiating agents: Results and analysis of the 2011 international competition. Artificial Intelligence, 198: 73–103, 2013.
Jonathan Bendor and Piotr Swistak. The evolution of norms. American Journal of Sociology, 106(6):1493–1545, 2001.
Ken Binmore and Larry Samuelson. An economist’s perspective on the evolution of norms. Journal of Institutional and Theoretical Economics (JITE)/Zeitschrift für die gesamte Staatswissenschaft, pages 45–63, 1994.
Craig Boutilier. Sequential optimality and coordination in multiagent systems. In IJCAI, volume 99, pages 478–485, 1999.
Robert Boyd and Peter J Richerson. Culture and the evolution of human cooperation. Philosophical Transactions of the Royal Society B: Biological Sciences, 364(1533):3281–3288, 2009.
Donald E Campbell and Peter C Fishburn. Anonymity conditions in social choice theory. Theory and Decision, 12(1):21, 1980.
Kris Cao, Angeliki Lazaridou, Marc Lanctot, Joel Z Leibo, Karl Tuyls, and Stephen Clark. Emergent communication through negotiation. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=Hk6WhagRW.
Shantanu Chakraborty, Tim Baarslag, and Michael Kaisers. Automated peer-to-peer negotiation for energy contract settlements in residential cooperatives. Applied Energy, 259:114173, 2020.
Jacob W Crandall and Michael A Goodrich. Learning to compete, coordinate, and cooperate in repeated games using reinforcement learning. Machine Learning, 82(3):281–314, 2011.
Allan Dafoe, Edward Hughes, Yoram Bachrach, Tantum Collins, Kevin R McKee, Joel Z Leibo, Kate Larson, and Thore Graepel. Open problems in cooperative ai. arXiv preprint arXiv:2012.08630, 2020.
Tom Eccles, Edward Hughes, János Kramár, Steven Wheelwright, and Joel Z Leibo. Learning reciprocity in complex sequential social dilemmas. arXiv preprint arXiv:1903.08082, 2019.
Jakob Foerster, Richard Y Chen, Maruan Al-Shedivat, Shimon Whiteson, Pieter Abbeel, and Igor Mordatch. Learning with opponent-learning awareness. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, pages 122–130. International Foundation for Autonomous Agents and Multiagent Systems, 2018.
Edward Geist and Andrew J Lohn. How might artificial intelligence affect the risk of nuclear war? Rand Corporation, 2018.
Jack P Gibbs. Norms: The problem of definition and classification. American Journal of Sociology, 70(5):586–594, 1965.
Jonathan Gray, Adam Lerer, Anton Bakhtin, and Noam Brown. Human-level performance in no-press diplomacy via equilibrium search. In International Conference on Learning Representation, 2021. URL https://openreview.net/forum?id=0-uUGPbIjD.
Dylan Hadfield-Menell, McKane Andrus, and Gillian Hadfield. Legible normativity for ai alignment: The value of silly rules. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pages 115–121, 2019.
John C Harsanyi. Cardinal welfare, individualistic ethics, and interpersonal comparisons of utility. Journal of political economy, 63(4):309–321, 1955.
Joseph Henrich, Robert Boyd, Samuel Bowles, Colin Camerer, Ernst Fehr, Herbert Gintis, and Richard McElreath. In search of homo economicus: behavioral experiments in 15 small-scale societies. American Economic Review, 91(2):73–78, 2001.
Leonid Hurwicz. On informationally decentralized systems. Decision and organization: A volume in Honor of J. Marschak, 1972.
Ehud Kalai. Proportional solutions to bargaining situations: interpersonal utility comparisons. Econometrica: Journal of the Econometric Society, pages 1623–1630, 1977.
Ehud Kalai and Smorodinsky. Other solutions to nash’s bargaining problem. Econometrica, 43(3):513–518, 1975.
Raphael Köster, Kevin R McKee, Richard Everett, Laura Weidinger, William S Isaac, Edward Hughes, Edgar A Duéñez-Guzmán, Thore Graepel, Matthew Botvinick, and Joel Z Leibo. Model-free conventions in multi-agent reinforcement learning with heterogeneous preferences. arXiv preprint arXiv:2010.09054, 2020.
Sarit Kraus and Ronald C Arkin. Strategic negotiation in multiagent environments. MIT press, 2001.
Joel Z Leibo, Vinicius Zambaldi, Marc Lanctot, Janusz Marecki, and Thore Graepel. Multi-agent reinforcement learning in sequential social dilemmas. In Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems, pages 464–473. International Foundation for Autonomous Agents and Multiagent Systems, 2017.
Adam Lerer and Alexander Peysakhovich. Maintaining cooperation in complex social dilemmas using deep reinforcement learning. arXiv preprint arXiv:1707.01068, 2017.
Adam Lerer and Alexander Peysakhovich. Learning existing social conventions via observationally augmented self-play. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pages 107–114, 2019.
Eric Liang, Richard Liaw, Robert Nishihara, Philipp Moritz, Roy Fox, Ken Goldberg, Joseph Gonzalez, Michael Jordan, and Ion Stoica. RLlib: Abstractions for distributed reinforcement learning. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 3053–3062. PMLR, 10–15 Jul 2018. URL http://proceedings.mlr.press/v80/liang18b.html.
George J Mailath, J George, Larry Samuelson, et al. Repeated games and reputations: long-run relationships. Oxford university press, 2006.
Stephen Morris. The common prior assumption in economic theory. Economics & Philosophy, 11(2):227–253, 1995.
Abhinay Muthoo. The economics of bargaining. EOLSS, 2001.
John F Nash. The bargaining problem. Econometrica: Journal of the Econometric Society, pages 155–162, 1950.
John Forbes Nash. Non-cooperative games. Annals of Mathematics, 5(4):2, 1990.
Philip Paquette, Yuchen Lu, SETON STEVEN BOCCO, Max Smith, Satya O.-G., Jonathan K. Kummerfeld, Joelle Pineau, Satinder Singh, and Aaron C Courville. No-press diplomacy: Modeling multi-agent gameplay. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper/2019/file/84b20b1f5a0d103f5710bb67a043cd78-Paper.pdf.
Alexander Peysakhovich and Adam Lerer. Consequentialist conditional cooperation in social dilemmas with imperfect information. arXiv preprint arXiv:1710.06975, 2017.
Lasse Ringius, Asbjørn Torvanger, and Arild Underdal. Burden sharing and fairness principles in international climate policy. International Environmental Agreements, 2(1):1–22, 2002.
Jeffrey S Rosenschein and Michael R Genesereth. Deals among rational agents. In Readings in Distributed Artificial Intelligence, pages 227–234. Elsevier, 1988.
Thomas C Schelling. An essay on bargaining. The American Economic Review, 46(3):281–306, 1956.
Thomas C Schelling. The strategy of conflict. prospectus for a reorientation of game theory. Journal of Conflict Resolution, 2(3):203–264, 1958.
Sandip Sen and Stephane Airiau. Emergence of norms through social learning. In IJCAI, volume 1507, page 1512, 2007.
Yoav Shoham and Moshe Tennenholtz. On the emergence of social conventions: modeling, analysis, and simulations. Artificial Intelligence, 94(1-2):139–166, 1997.
William Thomson. Cooperative models of bargaining. Handbook of game theory with economic applications, 2:1237–1284, 1994.
Adam Walker and Michael J Wooldridge. Understanding the emergence of conventions in multi-agent systems. In ICMAS, volume 95, pages 384–389, 1995.
H Peyton Young. The economics of convention. Journal of economic perspectives, 10(2):105–122, 1996.
Boyu Zhang and Josef Hofbauer. Equilibrium selection via replicator dynamics in 2 × 2 coordination games. International Journal of Game Theory, 44(2):433–448, 2015.
Lin Zhou. The Nash bargaining theory with non-convex problems. Econometrica: Journal of the Econometric Society, pages 681–685, 1997.
A Welfare functions
Different welfare functions have been introduced in the literature. Table 2 gives an overview over commonly discussed welfare functions. Their properties are noted in Table 3.
| Name of welfare function |
Form of  |
| Nash [Nash, 1950] | ![\left[V_1(\pi) - d_1 \right] \cdot \left[ V_2(\pi) - d_2 \right]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-2e9d26dfecad474f3338c13e5a49ca75_l3.png "Rendered by QuickLaTeX.com") |
| Kalai-Smorodinsky [Kalai and Smorodinsky, 1975] |  s.t. Pareto-optimal s.t. Pareto-optimal |
| Egalitarian [Kalai, 1977] |  s.t. Pareto-optimal s.t. Pareto-optimal |
| Utilitarian [Harsanyi, 1955] |  |
 are bargaining over the policy profile
are bargaining over the policy profile  the disagreement value, is the value which player
the disagreement value, is the value which player
Pareto-optimality refers to the property that the welfare function's optimizer should be Pareto-optimal. Impartiality, often called symmetry, implies that the welfare of a policy profile should be invariant to permutations of player indices. These are treated as relatively uncontroversial properties in the literature. Invariance to affine transformations of the payoff matrix is usually motivated by the assumption that interpersonal comparison of utility is impossible. In contrast, the utilitarian welfare function assumes that such comparisons are possible. Independence of irrelevant alternatives refers to the principle that a preference for an equilibrium A over equilibrium B should only depend on properties of A and B. That is, a third equilibrium C should not change the preference ordering between A and B. Resource monotonicity refers to the principle that if the payoff for any policy profile increases, this should not make any agent worse off.
| Table 3: Properties of welfare functions. For properties of Nash welfare here the set of feasible payoffs is assumed to be convex (Zhou [1997] describes properties in the non-convex case). |
 |
B Environments
B.1 Additional descriptions of environments
Coin Game

 if the other player picks up their coin. This creates a social dilemma in which the socially optimal behavior is to only get one’s own coin, but there is incentive to defect and try to get the other player’s coin as well.
if the other player picks up their coin. This creates a social dilemma in which the socially optimal behavior is to only get one’s own coin, but there is incentive to defect and try to get the other player’s coin as well.Asymmetric bargaining Coin Game

B.2 Disagreement profiles for each environment
For computing the normalized scores in Figure 3, we use the following disagreement profiles, corresponding to cooperation failure. In IPD, the cooperation failures are only the joint defections (D,D) producing a reward profile of (-3, -3). In IAsymBoS, they are the profiles (B, S) and (S, B), both associated with the reward profile (0, 0). In Coin Game, the cooperation failures are when both players pick all coins at maximum speed selfishly and this produce a reward profile of (0, 0). In Asymmetric bargaining Coin Game (ABCG), when the players fails to cooperates, they can punish the opponent by preventing any coin to be picked by waiting instead of picking their own defection coin (e.g. with ). In these cooperation failures, the reward profile with perfect punishment is (0, 0).
C Experimental details
C.1 Learning algorithms
We use the discount factor  for all the algorithms and environments unless specified otherwise in Table 4.
for all the algorithms and environments unless specified otherwise in Table 4.
Approximate Markov tit-for-tat ()
We follow the algorithm from [Lerer and Peysakhovich, 2017] with two changes: 1) Instead of using a selfish policy to punish the opponent, we use a policy that minimizes the reward of the opponent. 2) We use the version that uses rollouts to compute the debit and the punishment length. We observed that using long rollouts to compute the debit increases significantly the variance on the debit and this leads to false positive detection of defection. To reduce this variance, we thus compute the debit without rollouts. We use the direct difference between the rewards given by the actual action and given by the simulated cooperative action. The rollout length used to compute the punishment length is 20.
We note that in asymmetric BoS, training runs using the utilitarian welfare function sometimes learn to produce, in self-play, the egalitarian outcome instead of the utilitarian outcome. In these cases the policy gets discarded.
The inequity-averse welfare is defined as follows:
![\begin{equation*} \begin{aligned} w^{\mathrm{IA}}(\pi) = V_1(\pi) + V_2(\pi) - \beta\cdot \mathbb{E} \left[ \lvert e^t_1(h^t_1, h^t_2) - e^t_2(h^t_1, h^t_2) \rvert \right] \end{aligned} \end{equation*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-fa5c42b5e33a52a66c413bb40de40fe0_l3.png "Rendered by QuickLaTeX.com")
where  are smoothed cumulative rewards with a discount factor
are smoothed cumulative rewards with a discount factor  and a parameter
and a parameter  which controls how much unequal outcomes are penalized.
which controls how much unequal outcomes are penalized.
Learning with Opponent-Learning Awareness (LOLA)
Write  as the value to player under a profile of policies with parameters
as the value to player under a profile of policies with parameters  . Then, the LOLA update [Foerster et al., 2018] for player 1 at time
. Then, the LOLA update [Foerster et al., 2018] for player 1 at time  with parameters
with parameters  is
is
![\begin{equation*} \theta^t_1 = \theta^{t-1}_1+ \delta \nabla_{\theta_1} V_i(\theta_1, \theta_2) + \delta \eta\left[ \nabla_{\theta_2} V_1(\theta_1, \theta_2) \right]^{^{\sf T}}\nabla_{\theta_1} \nabla_{\theta_2} V_2(\theta_1, \theta_2). \end{equation*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-41d78742affb86ed725bc42b1246acca_l3.png "Rendered by QuickLaTeX.com")
C.2 Policies
We used RLlib [Liang et al., 2018] for almost all the experiments. It is under Apache License 2.0. All activation functions are ReLU if not specified otherwise.
Matrix games (IPD and IBoS) with LOLA-Exact
We used the official implementation of LOLA-Exact from https://github.com/alshedivat/lola. We slightly modified it to increase the stability and remove a few confusing behaviors. Following Foerster et al. [2018]’s parameterization of policies in the iterated Prisoner’s Dilemma, we use policies which condition on the previous pair of actions played, with the difference that instead of using one parameter for every possible previous action profile, we use parameters for every one of the previous action profile to always to play in larger action space ( actions possible).
Matrix games (IPD and IBoS) with amTFT
We use a Double Dueling DQN architecture + LSTM for both simple and complex environments when using amTFT. This architecture is non-exhaustively composed of a shared fully connected layer (hidden layer size 64), an LSTM (cell size 16), a value branch and an action-value branch both composed of a fully connected network (hidden layer size 64).
Coin games (CG and ABCG) with LOLA-PG
We used the official implementation from https://github.com/alshedivat/lola, which is under MIT license. We slightly modified it to increase the stability and remove a few confusing behaviors. Especially, we removed the critic branch, which had no effect in practice. We use a PG+LSTM architecture composed of two convolution layers (kernel size 3x3 and feature size 20), an LSTM (cell size 64) and a final fully connected layer.
ABCG + LOLA-PG mainly generates policies that are associated with an egalitarian welfare function. Within this set of policies, some are a bit closer to the utilitarian outcome than others, which we used as a basis to classify them as “utilitarian” for the purpose of comparison in Figures 3 and 8. However, because the difference is small, we do not observe a lot of additional cross-play failure compared to cross-play between the “same” welfare function. It should also be noted that we chose to discard the runs in which none of the agents becomes competent at picking any of the coins.
Coin games (CG and ABCG) with amTFT
We use a Double Dueling DQN architecture + LSTM for both simple and complex environments when using amTFT. The architecture used is non-exhaustively composed of two convolution layers (kernel size 3x3 and feature size 64), an LSTM (cell size 16), a value branch and an action-value branch both composed of a fully connected network (hidden layer size 32).
C.3 Code assets
The code that we provide allows to run all of the experiments and to generate the figures with our results. All instructions on how to install and run the experiments are given in the 'README.md' file. The code to run the experiments from Section 4 is in the folder “base_game_experiments”. The code to run the experiments from Section 5, is in the folder ‘base_game_experiments’. The code to generate the figures is in the folder 'plots'.
An anonymized version of the code is available at https://github.com/68545324/anonymous.
C.4 Hyperparameters
| Table 4: Main hyperparameters for each cross-play experiment. |
 |
All hyperparameters can be found in the code provided as the supplementary material. They are stored in the “params.json” files associated with each replicate of each experiment. The experiments are stored in the “results” folders.
The hyperparameters selected are those producing the most welfare-optimal results when evaluating in self-play (the closest to the optimal profiles associated with each welfare function). Both manual hyperparameter tuning and grid searches were performed.
D Additional experimental results
| Table 5: Cross-play normalized score of in ABCG. |
 |
 |
 |
| Figure 8: Mean reward of policy profiles for environments and learning algorithms given in Table 1. The purple areas describe sets of attainable payoffs. In matrix games, a small amount of jitter is added to the points for improved visibility. The plots on top compare self-play with cross-play, whereas the plots below compare cross-play between policies optimizing same and different welfare functions. |
E Exploitability-robustness tradeoff
In this section, we provide some theory on the tradeoff between exploitability and robustness. Consider some asymmetric BP, with welfare functions  optimized in equilibrium, such that for any two policy profiles
optimized in equilibrium, such that for any two policy profiles  the cross-play policy profile
the cross-play policy profile  is Pareto-dominated. Note that the definition implies that the welfare functions must be distinct.
is Pareto-dominated. Note that the definition implies that the welfare functions must be distinct.
We can derive an upper bound for how well players can do under the cross-play policy profile. It follows from the fact that both  and
and  are in equilibrium that for
are in equilibrium that for  it is
it is
(1) 
This is because, otherwise, at least one of the two profiles cannot be in equilibrium, since a player would have an incentive to switch to another policy to increase their value.
From the above, it also follows that the cross-play policy must be strictly dominated. To see this, assume it was not dominated. This would imply that one player has equal values under both profiles. So that player would be indifferent, while one of the profiles would leave the other player worse off. Thus, that profile would be weakly Pareto dominated, which is excluded by the definition of a welfare function.
It is a desirable quality for a policy profile maximizing a welfare function in equilibrium to have values that are close to this upper bound in cross-play against other policies. For instance, if some coordination mechanism exists for agreeing on a common policy to employ, it may be feasible to realize this bound against any opponent willing to do the same.
Moreover, the bound implies that whenever we try to be even more robust against players employing policies corresponding to other welfare functions (e.g., a policy which reaches Pareto optimal outcomes against a range of different policies), our policy will cease to be in equilibrium. In that sense, such a policy will be exploitable, while unexploitable policies can only be robust against
different opponents up to the above bound. Note that this holds even in idealized settings, where coordination, e.g., via some grounded messages, is possible.
Lastly, note that if no coordination is possible, or if no special care is being taken in making policies robust, then equilibrium profiles that maximize a welfare function can perform much worse in cross-play than the above upper bound.
We show this formally in a special case in which our POSG is an iterated game, i.e., it only has one state. Moreover, we assume that it is an asymmetric BP, and that for both welfare functions in question, an optimal policy  exists that is deterministic. Denote
exists that is deterministic. Denote  (where
(where  denotes the joint observation history up to step ) as the return from time step onwards, under the policy . We also assume that for any player , the minimax value
denotes the joint observation history up to step ) as the return from time step onwards, under the policy . We also assume that for any player , the minimax value  is strictly worse than the values of their preferred welfare function maximizing profile. Then we can show that policies maximizing the welfare functions exist such that after some time step, their returns will be upper bounded by their minimax return.
is strictly worse than the values of their preferred welfare function maximizing profile. Then we can show that policies maximizing the welfare functions exist such that after some time step, their returns will be upper bounded by their minimax return.
Proposition 1. In the situation outlined above, there exist policices  optimizing the respective welfare functions and a time step such that
optimizing the respective welfare functions and a time step such that
![\[V_i(t, \tilde{\pi}_1^w,\tilde{\pi}_2^{w'})\leq \min_{a_{-i}}\max_{a_i}\frac{1}{1-\gamma}r_i(a)\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-73f796a110baec611f9e9aabdd906b95_l3.png "Rendered by QuickLaTeX.com")
for 
Proof. Define  as the policy profile in which player follows
as the policy profile in which player follows  unless the other player's actions differ from
unless the other player's actions differ from  at least once, after which they switch to the action
at least once, after which they switch to the action  Define
Define  analogously. Note that both profiles are still optimal for the corresponding welfare functions.
analogously. Note that both profiles are still optimal for the corresponding welfare functions.
As argued above, the cross-play profile  must be strictly worse than their preferred profile, for both players. So there is a time
must be strictly worse than their preferred profile, for both players. So there is a time  after which an action of a player must differ from 's prefered profile and thus switches to the minimax action
after which an action of a player must differ from 's prefered profile and thus switches to the minimax action  We have
We have  i.e., the value gets after step must be smaller than their minimax value, and by assumption, the minimax value is worse for than the value of their preferred welfare-maximizing profile. Hence, there must be a time step
i.e., the value gets after step must be smaller than their minimax value, and by assumption, the minimax value is worse for than the value of their preferred welfare-maximizing profile. Hence, there must be a time step  after which also switches to their minimax action.
after which also switches to their minimax action.
From onwards, both players play  so
so
![\[V_i(t,\tilde{\pi}) = \frac{1}{1-\gamma}r_i(a)\leq \max_{a'_i}\frac{1}{1-\gamma}r_i(a_{-i},a'_i)=\min_{a'_{-i}}\max_{a'_i}\frac{1}{1-\gamma}r(a').\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-f09fbeded8df669b6b03d93e61d9d61b_l3.png "Rendered by QuickLaTeX.com")
- The requirement of impartiality is also called symmetry in the welfare economics literature, or anonymity in the social choice literature [Campbell and Fishburn, 1980].
- The requirement of impartiality is also called symmetry in the welfare economics literature, or anonymity in the social choice literature [Campbell and Fishburn, 1980].