Summary
Artificial intelligence (AI) will transform the world later this century. I expect this transition will be a "soft takeoff" in which many sectors of society update together in response to incremental AI developments, though the possibility of a harder takeoff in which a single AI project "goes foom" shouldn't be ruled out. If a rogue AI gained control of Earth, it would proceed to accomplish its goals by colonizing the galaxy and undertaking some very interesting achievements in science and engineering. On the other hand, it would not necessarily respect human values, including the value of preventing the suffering of less powerful creatures. Whether a rogue-AI scenario would entail more expected suffering than other scenarios is a question to explore further. Regardless, the field of AI ethics and policy seems to be a very important space where altruists can make a positive-sum impact along many dimensions. Expanding dialogue and challenging us-vs.-them prejudices could be valuable.
Other versions
*Several of the new written sections of this piece are absent from the podcast because I recorded it a while back.
Introduction
This piece contains some observations on what looks to be potentially a coming machine revolution in Earth's history. For general background reading, a good place to start is Wikipedia's article on the technological singularity.
I am not an expert on all the arguments in this field, and my views remain very open to change with new information. In the face of epistemic disagreements with other very smart observers, it makes sense to grant some credence to a variety of viewpoints. Each person brings unique contributions to the discussion by virtue of his or her particular background, experience, and intuitions.
To date, I have not found a detailed analysis of how those who are moved more by preventing suffering than by other values should approach singularity issues. This seems to me a serious gap, and research on this topic deserves high priority. In general, it's important to expand discussion of singularity issues to encompass a broader range of participants than the engineers, technophiles, and science-fiction nerds who have historically pioneered the field.
I. J. Good observed in 1982: "The urgent drives out the important, so there is not very much written about ethical machines". Fortunately, this may be changing.
Is "the singularity" crazy?
In fall 2005, a friend pointed me to Ray Kurzweil's The Age of Spiritual Machines. This was my first introduction to "singularity" ideas, and I found the book pretty astonishing. At the same time, much of it seemed rather implausible to me. In line with the attitudes of my peers, I assumed that Kurzweil was crazy and that while his ideas deserved further inspection, they should not be taken at face value.
In 2006 I discovered Nick Bostrom and Eliezer Yudkowsky, and I began to follow the organization then called the Singularity Institute for Artificial Intelligence (SIAI), which is now MIRI. I took SIAI's ideas more seriously than Kurzweil's, but I remained embarrassed to mention the organization because the first word in SIAI's name sets off "insanity alarms" in listeners.
I began to study machine learning in order to get a better grasp of the AI field, and in fall 2007, I switched my college major to computer science. As I read textbooks and papers about machine learning, I felt as though "narrow AI" was very different from the strong-AI fantasies that people painted. "AI programs are just a bunch of hacks," I thought. "This isn't intelligence; it's just people using computers to manipulate data and perform optimization, and they dress it up as 'AI' to make it sound sexy." Machine learning in particular seemed to be just a computer scientist's version of statistics. Neural networks were just an elaborated form of logistic regression. There were stylistic differences, such as computer science's focus on cross-validation and bootstrapping instead of testing parametric models -- made possible because computers can run data-intensive operations that were inaccessible to statisticians in the 1800s. But overall, this work didn't seem like the kind of "real" intelligence that people talked about for general AI.
This attitude began to change as I learned more cognitive science. Before 2008, my ideas about human cognition were vague. Like most science-literate people, I believed the brain was a product of physical processes, including firing patterns of neurons. But I lacked further insight into what the black box of brains might contain. This led me to be confused about what "free will" meant until mid-2008 and about what "consciousness" meant until late 2009. Cognitive science showed me that the brain was in fact very much like a computer, at least in the sense of being a deterministic information-processing device with distinct algorithms and modules. When viewed up close, these algorithms could look as "dumb" as the kinds of algorithms in narrow AI that I had previously dismissed as "not really intelligence." Of course, animal brains combine these seemingly dumb subcomponents in dazzlingly complex and robust ways, but I could now see that the difference between narrow AI and brains was a matter of degree rather than kind. It now seemed plausible that broad AI could emerge from lots of work on narrow AI combined with stitching the parts together in the right ways.
So the singularity idea of artificial general intelligence seemed less crazy than it had initially. This was one of the rare cases where a bold claim turned out to look more probable on further examination; usually extraordinary claims lack much evidence and crumble on closer inspection. I now think it's quite likely (maybe ~75%) that humans will produce at least a human-level AI within the next ~300 years conditional on no major disasters (such as sustained world economic collapse, global nuclear war, large-scale nanotech war, etc.), and also ignoring anthropic considerations.
The singularity is more than AI
The "singularity" concept is broader than the prediction of strong AI and can refer to several distinct sub-meanings. Like with most ideas, there's a lot of fantasy and exaggeration associated with "the singularity," but at least the core idea that technology will progress at an accelerating rate for some time to come, absent major setbacks, is not particularly controversial. Exponential growth is the standard model in economics, and while this can't continue forever, it has been a robust pattern throughout human and even pre-human history.
MIRI emphasizes AI for a good reason: At the end of the day, the long-term future of our galaxy will be dictated by AI, not by biotech, nanotech, or other lower-level systems. AI is the "brains of the operation." Of course, this doesn't automatically imply that AI should be the primary focus of our attention. Maybe other revolutionary technologies or social forces will come first and deserve higher priority. In practice, I think focusing on AI specifically seems quite important even relative to competing scenarios, but it's good to explore many areas in parallel to at least a shallow depth.
In addition, I don't see a sharp distinction between "AI" and other fields. Progress in AI software relies heavily on computer hardware, and it depends at least a little bit on other fundamentals of computer science, like programming languages, operating systems, distributed systems, and networks. AI also shares significant overlap with neuroscience; this is especially true if whole brain emulation arrives before bottom-up AI. And everything else in society matters a lot too: How intelligent and engineering-oriented are citizens? How much do governments fund AI and cognitive-science research? (I'd encourage less rather than more.) What kinds of military and commercial applications are being developed? Are other industrial backbone components of society stable? What memetic lenses does society have for understanding and grappling with these trends? And so on. The AI story is part of a larger story of social and technological change, in which one part influences other parts.
Significant trends in AI may not look like the AI we see in movies. They may not involve animal-like cognitive agents as much as more "boring", business-oriented computing systems. Some of the most transformative computer technologies in the period 2000-2014 have been drones, smart phones, and social networking. These all involve some AI, but the AI is mostly used as a component of a larger, non-AI system, in which many other facets of software engineering play at least as much of a role.
Nonetheless, it seems nearly inevitable to me that digital intelligence in some form will eventually leave biological humans in the dust, if technological progress continues without faltering. This is almost obvious when we zoom out and notice that the history of life on Earth consists in one species outcompeting another, over and over again. Ecology's competitive exclusion principle suggests that in the long run, either humans or machines will ultimately occupy the role of the most intelligent beings on the planet, since "When one species has even the slightest advantage or edge over another then the one with the advantage will dominate in the long term."
Will society realize the importance of AI?
The basic premise of superintelligent machines who have different priorities than their creators has been in public consciousness for many decades. Arguably even Frankenstein, published in 1818, expresses this basic idea, though more modern forms include 2001: A Space Odyssey (1968), The Terminator (1984), I, Robot (2004), and many more. Probably most people in Western countries have at least heard of these ideas if not watched or read pieces of fiction on the topic.
So why do most people, including many of society's elites, ignore strong AI as a serious issue? One reason is just that the world is really big, and there are many important (and not-so-important) issues that demand attention. Many people think strong AI is too far off, and we should focus on nearer-term problems. In addition, it's possible that science fiction itself is part of the reason: People may write off AI scenarios as "just science fiction," as I would have done prior to late 2005. (Of course, this is partly for good reason, since depictions of AI in movies are usually very unrealistic.) Often, citing Hollywood is taken as a thought-stopping deflection of the possibility of AI getting out of control, without much in the way of substantive argument to back up that stance. For example: "let's please keep the discussion firmly within the realm of reason and leave the robot uprisings to Hollywood screenwriters."
As AI progresses, I find it hard to imagine that mainstream society will ignore the topic forever. Perhaps awareness will accrue gradually, or perhaps an AI Sputnik moment will trigger an avalanche of interest. Stuart Russell expects that
Just as nuclear fusion researchers consider the problem of containment of fusion reactions as one of the primary problems of their field, it seems inevitable that issues of control and safety will become central to AI as the field matures.
I think it's likely that issues of AI policy will be debated heavily in the coming decades, although it's possible that AI will be like nuclear weapons -- something that everyone is afraid of but that countries can't stop because of arms-race dynamics. So even if AI proceeds slowly, there's probably value in thinking more about these issues well ahead of time, though I wouldn't consider the counterfactual value of doing so to be astronomical compared with other projects in part because society will pick up the slack as the topic becomes more prominent.
[Update, Feb. 2015: I wrote the preceding paragraphs mostly in May 2014, before Nick Bostrom's Superintelligence book was released. Following Bostrom's book, a wave of discussion about AI risk emerged from Elon Musk, Stephen Hawking, Bill Gates, and many others. AI risk suddenly became a mainstream topic discussed by almost every major news outlet, at least with one or two articles. This foreshadows what we'll see more of in the future. The outpouring of publicity for the AI topic happened far sooner than I imagined it would.]
A soft takeoff seems more likely?
Various thinkers have debated the likelihood of a "hard" takeoff -- in which a single computer or set of computers rapidly becomes superintelligent on its own -- compared with a "soft" takeoff -- in which society as a whole is transformed by AI in a more distributed, continuous fashion. "The Hanson-Yudkowsky AI-Foom Debate" discusses this in great detail. The topic has also been considered by many others, such as Ramez Naam vs. William Hertling.
For a long time I inclined toward Yudkowsky's vision of AI, because I respect his opinions and didn't ponder the details too closely. This is also the more prototypical example of rebellious AI in science fiction. In early 2014, a friend of mine challenged this view, noting that computing power is a severe limitation for human-level minds. My friend suggested that AI advances would be slow and would diffuse through society rather than remaining in the hands of a single developer team. As I've read more AI literature, I think this soft-takeoff view is pretty likely to be correct. Science is always a gradual process, and almost all AI innovations historically have moved in tiny steps. I would guess that even the evolution of humans from their primate ancestors was a "soft" takeoff in the sense that no single son or daughter was vastly more intelligent than his or her parents. The evolution of technology in general has been fairly continuous. I probably agree with Paul Christiano that "it is unlikely that there will be rapid, discontinuous, and unanticipated developments in AI that catapult it to superhuman levels [...]."
Of course, it's not guaranteed that AI innovations will diffuse throughout society. At some point perhaps governments will take control, in the style of the Manhattan Project, and they'll keep the advances secret. But even then, I expect that the internal advances by the research teams will add cognitive abilities in small steps. Even if you have a theoretically optimal intelligence algorithm, it's constrained by computing resources, so you either need lots of hardware or approximation hacks (or most likely both) before it can function effectively in the high-dimensional state space of the real world, and this again implies a slower trajectory. Marcus Hutter's AIXI(tl) is an example of a theoretically optimal general intelligence, but most AI researchers feel it won't work for artificial general intelligence (AGI) because it's astronomically expensive to compute. Ben Goertzel explains: "I think that tells you something interesting. It tells you that dealing with resource restrictions -- with the boundedness of time and space resources -- is actually critical to intelligence. If you lift the restriction to do things efficiently, then AI and AGI are trivial problems."
In "I Still Don’t Get Foom", Robin Hanson contends:
Yes, sometimes architectural choices have wider impacts. But I was an artificial intelligence researcher for nine years, ending twenty years ago, and I never saw an architecture choice make a huge difference, relative to other reasonable architecture choices. For most big systems, overall architecture matters a lot less than getting lots of detail right.
This suggests that it's unlikely that a single insight will make an astronomical difference to an AI's performance.
Similarly, my experience is that machine-learning algorithms matter less than the data they're trained on. I think this is a general sentiment among data scientists. There's a famous slogan that "More data is better data." A main reason Google's performance is so good is that it has so many users that even obscure searches, spelling mistakes, etc. will appear somewhere in its logs. But if many performance gains come from data, then they're constrained by hardware, which generally grows steadily.
Hanson's "I Still Don’t Get Foom" post continues: "To be much better at learning, the project would instead have to be much better at hundreds of specific kinds of learning. Which is very hard to do in a small project." Anders Sandberg makes a similar point:
As the amount of knowledge grows, it becomes harder and harder to keep up and to get an overview, necessitating specialization. [...] This means that a development project might need specialists in many areas, which in turns means that there is a lower size of a group able to do the development. In turn, this means that it is very hard for a small group to get far ahead of everybody else in all areas, simply because it will not have the necessary know how in all necessary areas. The solution is of course to hire it, but that will enlarge the group.
One of the more convincing anti-"foom" arguments is J. Storrs Hall's point that an AI improving itself to a world superpower would need to outpace the entire world economy of 7 billion people, plus natural resources and physical capital. It would do much better to specialize, sell its services on the market, and acquire power/wealth in the ways that most people do. There are plenty of power-hungry people in the world, but usually they go to Wall Street, K Street, or Silicon Valley rather than trying to build world-domination plans in their basement. Why would an AI be different? Some possibilities:
- By being built differently, it's able to concoct an effective world-domination strategy that no human has thought of.
- Its non-human form allows it to diffuse throughout the Internet and make copies of itself.
I'm skeptical of #1, though I suppose if the AI is very alien, these kinds of unknown unknowns become more plausible. #2 is an interesting point. It seems like a pretty good way to spread yourself as an AI is to become a useful software product that lots of people want to install, i.e., to sell your services on the world market, as Hall said. Of course, once that's done, perhaps the AI could find a way to take over the world. Maybe it could silently quash competitor AI projects. Maybe it could hack into computers worldwide via the Internet and Internet of Things, as the AI did in the Delete series. Maybe it could devise a way to convince humans to give it access to sensitive control systems, as Skynet did in Terminator 3.
I find these kinds of scenarios for AI takeover more plausible than a rapidly self-improving superintelligence. Indeed, even a human-level intelligence that can distribute copies of itself over the Internet might be able to take control of human infrastructure and hence take over the world. No "foom" is required.
Rather than discussing hard-vs.-soft takeoff arguments more here, I added discussion to Wikipedia where the content will receive greater readership. See "Hard vs. soft takeoff" in "Intelligence explosion".
The hard vs. soft distinction is obviously a matter of degree. And maybe how long the process takes isn't the most relevant way to slice the space of scenarios. For practical purposes, the more relevant question is: Should we expect control of AI outcomes to reside primarily in the hands of a few "seed AI" developers? In this case, altruists should focus on influencing a core group of AI experts, or maybe their military / corporate leaders. Or should we expect that society as a whole will play a big role in shaping how AI is developed and used? In this case, governance structures, social dynamics, and non-technical thinkers will play an important role not just in influencing how much AI research happens but also in how the technologies are deployed and incrementally shaped as they mature.
It's possible that one country -- perhaps the United States, or maybe China in later decades -- will lead the way in AI development, especially if the research becomes nationalized when AI technology grows more powerful. Would this country then take over the world? I'm not sure. The United States had a monopoly on nuclear weapons for several years after 1945, but it didn't bomb the Soviet Union out of existence. A country with a monopoly on artificial superintelligence might refrain from destroying its competitors as well. On the other hand, AI should enable vastly more sophisticated surveillance and control than was possible in the 1940s, so a monopoly might be sustainable even without resorting to drastic measures. In any case, perhaps a country with superintelligence would just economically outcompete the rest of the world, rendering military power superfluous.
Besides a single country taking over the world, the other possibility (perhaps more likely) is that AI is developed in a distributed fashion, either openly as is the case in academia today, or in secret by governments as is the case with other weapons of mass destruction.
Even in a soft-takeoff case, there would come a point at which humans would be unable to keep up with the pace of AI thinking. (We already see an instance of this with algorithmic stock-trading systems, although human traders are still needed for more complex tasks right now.) The reins of power would have to be transitioned to faster human uploads, trusted AIs built from scratch, or some combination of the two. In a slow scenario, there might be many intelligent systems at comparable levels of performance, maintaining a balance of power, at least for a while. In the long run, a singleton seems plausible because computers -- unlike human kings -- can reprogram their servants to want to obey their bidding, which means that as an agent gains more central authority, it's not likely to later lose it by internal rebellion (only by external aggression). Also, evolutionary competition is not a stable state, while a singleton is. It seems likely that evolution will eventually lead to a singleton at one point or other—whether because one faction takes over the world or because the competing factions form a stable cooperation agreement—and competition won't return after that happens. (That said, if the singleton is merely a contingent cooperation agreement among factions that still disagree, one can imagine that cooperation breaking down in the future....)
Most of humanity's problems are fundamentally coordination problems / selfishness problems. If humans were perfectly altruistic, we could easily eliminate poverty, overpopulation, war, arms races, and other social ills. There would remain "man vs. nature" problems, but these are increasingly disappearing as technology advances. Assuming a digital singleton emerges, the chances of it going extinct seem very small (except due to alien invasions or other external factors) because unless the singleton has a very myopic utility function, it should consider carefully all the consequences of its actions -- in contrast to the "fools rush in" approach that humanity currently takes toward most technological risks, due to wanting the benefits of and profits from technology right away and not wanting to lose out to competitors. For this reason, I suspect that most of George Dvorsky's "12 Ways Humanity Could Destroy The Entire Solar System" are unlikely to happen, since most of them presuppose blundering by an advanced Earth-originating intelligence, but probably by the time Earth-originating intelligence would be able to carry out interplanetary engineering on a nontrivial scale, we'll already have a digital singleton that thoroughly explores the risks of its actions before executing them. That said, this might not be true if competing AIs begin astroengineering before a singleton is completely formed. (By the way, I should point out that I prefer it if the cosmos isn't successfully colonized, because doing so is likely to astronomically multiply sentience and therefore suffering.)
Intelligence explosion?
Sometimes it's claimed that we should expect a hard takeoff because AI-development dynamics will fundamentally change once AIs can start improving themselves. One stylized way to explain this is via differential equations. Let I(t) be the intelligence of AIs at time t.
- While humans are building AIs, we have, dI/dt = c, where c is some constant level of human engineering ability. This implies I(t) = ct + constant, a linear growth of I with time.
- In contrast, once AIs can design themselves, we'll have dI/dt = kI for some k. That is, the rate of growth will be faster as the AI designers become more intelligent. This implies I(t) = Aet for some constant A.
Luke Muehlhauser reports that the idea of intelligence explosion once machines can start improving themselves "ran me over like a train. Not because it was absurd, but because it was clearly true." I think this kind of exponential feedback loop is the basis behind many of the intelligence-explosion arguments.
But let's think about this more carefully. What's so special about the point where machines can understand and modify themselves? Certainly understanding your own source code helps you improve yourself. But humans already understand the source code of present-day AIs with an eye toward improving it. Moreover, present-day AIs are vastly simpler than human-level ones will be, and present-day AIs are far less intelligent than the humans who create them. Which is easier: (1) improving the intelligence of something as smart as you, or (2) improving the intelligence of something far dumber? (2) is usually easier. So if anything, AI intelligence should be "exploding" faster now, because it can be lifted up by something vastly smarter than it. Once AIs need to improve themselves, they'll have to pull up on their own bootstraps, without the guidance of an already existing model of far superior intelligence on which to base their designs.
As an analogy, it's harder to produce novel developments if you're the market-leading company; it's easier if you're a competitor trying to catch up, because you know what to aim for and what kinds of designs to reverse-engineer. AI right now is like a competitor trying to catch up to the market leader.
Another way to say this: The constants in the differential equations might be important. Even if human AI-development progress is linear, that progress might be faster than a slow exponential curve until some point far later where the exponential catches up.
In any case, I'm cautious of simple differential equations like these. Why should the rate of intelligence increase be proportional to the intelligence level? Maybe the problems become much harder at some point. Maybe the systems become fiendishly complicated, such that even small improvements take a long time. Robin Hanson echoes this suggestion:
Students get smarter as they learn more, and learn how to learn. However, we teach the most valuable concepts first, and the productivity value of schooling eventually falls off, instead of exploding to infinity. Similarly, the productivity improvement of factory workers typically slows with time, following a power law.
At the world level, average IQ scores have increased dramatically over the last century (the Flynn effect), as the world has learned better ways to think and to teach. Nevertheless, IQs have improved steadily, instead of accelerating. Similarly, for decades computer and communication aids have made engineers much "smarter," without accelerating Moore's law. While engineers got smarter, their design tasks got harder.
Also, ask yourself this question: Why do startups exist? Part of the answer is that they can innovate faster than big companies due to having less institutional baggage and legacy software. It's harder to make radical changes to big systems than small systems. Of course, like the economy does, a self-improving AI could create its own virtual startups to experiment with more radical changes, but just as in the economy, it might take a while to prove new concepts and then transition old systems to the new and better models.
In discussions of intelligence explosion, it's common to approximate AI productivity as scaling linearly with number of machines, but this may or may not be true depending on the degree of parallelizability. Empirical examples for human-engineered projects show diminishing returns with more workers, and while computers may be better able to partition work due to greater uniformity and speed of communication, there will remain some overhead in parallelization. Some tasks may be inherently non-paralellizable, preventing the kinds of ever-faster performance that the most extreme explosion scenarios envisage.
Fred Brooks's "No Silver Bullet" paper argued that "there is no single development, in either technology or management technique, which by itself promises even one order of magnitude improvement within a decade in productivity, in reliability, in simplicity." Likewise, Wirth's law reminds us of how fast software complexity can grow. These points make it seem less plausible that an AI system could rapidly bootstrap itself to superintelligence using just a few key as-yet-undiscovered insights.
Chollet (2017) notes that "even if one part of a system has the ability to recursively self-improve, other parts of the system will inevitably start acting as bottlenecks." We might compare this with Liebig's law of the minimum: "growth is dictated not by total resources available, but by the scarcest resource (limiting factor)." Individual sectors of the human economy can show rapid growth at various times, but the growth rate of the entire economy is more limited.
Eventually there has to be a leveling off of intelligence increase if only due to physical limits. On the other hand, one argument in favor of differential equations is that the economy has fairly consistently followed exponential trends since humans evolved, though the exponential growth rate of today's economy remains small relative to what we typically imagine from an "intelligence explosion".
I think a stronger case for intelligence explosion is the clock-speed difference between biological and digital minds. Even if AI development becomes very slow in subjective years, once AIs take it over, in objective years (i.e., revolutions around the sun), the pace will continue to look blazingly fast. But if enough of society is digital by that point (including human-inspired subroutines and maybe full digital humans), then digital speedup won't give a unique advantage to a single AI project that can then take over the world. Hence, hard takeoff in the sci fi sense still isn't guaranteed. Also, Hanson argues that faster minds would produce a one-time jump in economic output but not necessarily a sustained higher rate of growth.
Another case for intelligence explosion is that intelligence growth might not be driven by the intelligence of a given agent so much as by the collective man-hours (or machine-hours) that would become possible with more resources. I suspect that AI research could accelerate at least 10 times if it had 10-50 times more funding. (This is not the same as saying I want funding increased; in fact, I probably want funding decreased to give society more time to sort through these issues.) The population of digital minds that could be created in a few decades might exceed the biological human population, which would imply faster progress if only by numerosity. Also, the digital minds might not need to sleep, would focus intently on their assigned tasks, etc. However, once again, these are advantages in objective time rather than collective subjective time. And these advantages would not be uniquely available to a single first-mover AI project; any wealthy and technologically sophisticated group that wasn't too far behind the cutting edge could amplify its AI development in this way.
(A few weeks after writing this section, I learned that Ch. 4 of Nick Bostrom's Superintelligence: Paths, Dangers, Strategies contains surprisingly similar content, even up to the use of dI/dt as the symbols in a differential equation. However, Bostrom comes down mostly in favor of the likelihood of an intelligence explosion. I reply to Bostrom's arguments in the next section.)
Reply to Bostrom's arguments for a hard takeoff
Note: Søren Elverlin replies to this section in a video presentation. I agree with some of his points and disagree with others.
In Ch. 4 of Superintelligence, Bostrom suggests several factors that might lead to a hard or at least semi-hard takeoff. I don't fully disagree with his points, and because these are difficult issues, I agree that Bostrom might be right. But I want to play devil's advocate and defend the soft-takeoff view. I've distilled and paraphrased what I think are 6 core arguments, and I reply to each in turn.
#1: There might be a key missing algorithmic insight that allows for dramatic progress.
Maybe, but do we have much precedent for this? As far as I'm aware, all individual AI advances -- and indeed, most technology advances in general -- have not represented astronomical improvements over previous designs. Maybe connectionist AI systems represented a game-changing improvement relative to symbolic AI for messy tasks like vision, but I'm not sure how much of an improvement they represented relative to the best alternative technologies. After all, neural networks are in some sense just fancier forms of pre-existing statistical methods like logistic regression. And even neural networks came in stages, with the perceptron, multi-layer networks, backpropagation, recurrent networks, deep networks, etc. The most groundbreaking machine-learning advances may reduce error rates by a half or something, which may be commercially very important, but this is not many orders of magnitude as hard-takeoff scenarios tend to assume.
Outside of AI, the Internet changed the world, but it was an accumulation of many insights. Facebook has had massive impact, but it too was built from many small parts and grew in importance slowly as its size increased. Microsoft became a virtual monopoly in the 1990s but perhaps more for business than technology reasons, and its power in the software industry at large is probably not growing. Google has a quasi-monopoly on web search, kicked off by the success of PageRank, but most of its improvements have been small and gradual. Google has grown very powerful, but it hasn't maintained a permanent advantage that would allow it to take over the software industry.
Acquiring nuclear weapons might be the closest example of a single discrete step that most dramatically changes a country's position, but this may be an outlier. Maybe other advances in weaponry (arrows, guns, etc.) historically have had somewhat dramatic effects.
Bostrom doesn't present specific arguments for thinking that a few crucial insights may produce radical jumps. He suggests that we might not notice a system's improvements until it passes a threshold, but this seems absurd, because at least the AI developers would need to be intimately acquainted with the AI's performance. While not strictly accurate, there's a slogan: "You can't improve what you can't measure." Maybe the AI's progress wouldn't make world headlines, but the academic/industrial community would be well aware of nontrivial breakthroughs, and the AI developers would live and breathe performance numbers.
#2: Once an AI passes a threshold, it might be able to absorb vastly more content (e.g., by reading the Internet) that was previously inaccessible.
Absent other concurrent improvements I'm doubtful this would produce take-over-the-world superintelligence, because the world's current superintelligence (namely, humanity as a whole) already has read most of the Internet -- indeed, has written it. I guess humans haven't read all automatically generated text or vast streams of numerical data, but the insights gleaned purely from reading such material would be low without doing more sophisticated data mining and learning on top of it, and presumably such data mining would have already been in progress well before Bostrom's hypothetical AI learned how to read.
In any case, I doubt reading with understanding is such an all-or-nothing activity that it can suddenly "turn on" once the AI achieves a certain ability level. As Bostrom says (p. 71), reading with the comprehension of a 10-year-old is probably AI-complete, i.e., requires solving the general AI problem. So assuming that you can switch on reading ability with one improvement is equivalent to assuming that a single insight can produce astronomical gains in AI performance, which we discussed above. If that's not true, and if before the AI system with 10-year-old reading ability was an AI system with a 6-year-old reading ability, why wouldn't that AI have already devoured the Internet? And before that, why wouldn't a proto-reader have devoured a version of the Internet that had been processed to make it easier for a machine to understand? And so on, until we get to the present-day TextRunner system that Bostrom cites, which is already devouring the Internet. It doesn't make sense that massive amounts of content would only be added after lots of improvements. Commercial incentives tend to yield exactly the opposite effect: converting the system to a large-scale product when even modest gains appear, because these may be enough to snatch a market advantage.
The fundamental point is that I don't think there's a crucial set of components to general intelligence that all need to be in place before the whole thing works. It's hard to evolve systems that require all components to be in place at once, which suggests that human general intelligence probably evolved gradually. I expect it's possible to get partial AGI with partial implementations of the components of general intelligence, and the components can gradually be made more general over time. Components that are lacking can be supplemented by human-based computation and narrow-AI hacks until more general solutions are discovered. Compare with minimum viable products and agile software development. As a result, society should be upended by partial AGI innovations many times over the coming decades, well before fully human-level AGI is finished.
#3: Once a system "proves its mettle by attaining human-level intelligence", funding for hardware could multiply.
I agree that funding for AI could multiply manyfold due to a sudden change in popular attention or political dynamics. But I'm thinking of something like a factor of 10 or maybe 50 in an all-out Cold War-style arms race. A factor-of-50 boost in hardware isn't obviously that important. If before there was one human-level AI, there would now be 50. In any case, I expect the Sputnik moment(s) for AI to happen well before it achieves a human level of ability. Companies and militaries aren't stupid enough not to invest massively in an AI with almost-human intelligence.
#4: Once the human level of intelligence is reached, "Researchers may work harder, [and] more researchers may be recruited".
As with hardware above, I would expect these "shit hits the fan" moments to happen before fully human-level AI. In any case:
- It's not clear there would be enough AI specialists to recruit in a short time. Other quantitatively minded people could switch to AI work, but they would presumably need years of experience to produce cutting-edge insights.
- The number of people thinking about AI safety, ethics, and social implications should also multiply during Sputnik moments. So the ratio of AI policy work to total AI work might not change relative to slower takeoffs, even if the physical time scales would compress.
#5: At some point, the AI's self-improvements would dominate those of human engineers, leading to exponential growth.
I discussed this in the "Intelligence explosion?" section above. A main point is that we see many other systems, such as the world economy or Moore's law, that also exhibit positive feedback and hence exponential growth, but these aren't "fooming" at an astounding rate. It's not clear why an AI's self-improvement -- which resembles economic growth and other complex phenomena -- should suddenly explode faster (in subjective time) than humanity's existing recursive-self improvement of its intelligence via digital computation.
On the other hand, maybe the difference between subjective and objective time is important. If a human-level AI could think, say, 10,000 times faster than a human, then assuming linear scaling, it would be worth 10,000 engineers. By the time of human-level AI, I expect there would be far more than 10,000 AI developers on Earth, but given enough hardware, the AI could copy itself manyfold until its subjective time far exceeded that of human experts. The speed and copiability advantages of digital minds seem perhaps the strongest arguments for a takeoff that happens rapidly relative to human observers. Note that, as Hanson said above, this digital speedup might be just a one-time boost, rather than a permanently higher rate of growth, but even the one-time boost could be enough to radically alter the power dynamics of humans vis-à-vis machines. That said, there should be plenty of slightly sub-human AIs by this time, and maybe they could fill some speed gaps on behalf of biological humans.
In general, it's a mistake to imagine human-level AI against a backdrop of our current world. That's like imagining a Tyrannosaurus rex in a human city. Rather, the world will look very different by the time human-level AI arrives. Before AI can exceed human performance in all domains, it will exceed human performance in many narrow domains gradually, and these narrow-domain AIs will help humans respond quickly. For example, a narrow AI that's an expert at military planning based on war games can help humans with possible military responses to rogue AIs.
Many of the intermediate steps on the path to general AI will be commercially useful and thus should diffuse widely in the meanwhile. As user "HungryHobo" noted: "If you had a near human level AI, odds are, everything that could be programmed into it at the start to help it with software development is already going to be part of the suites of tools for helping normal human programmers." Even if AI research becomes nationalized and confidential, its developers should still have access to almost-human-level digital-speed AI tools, which should help smooth the transition. For instance, Bostrom mentions how in the 2010 flash crash (Box 2, p. 17), a high-speed positive-feedback spiral was terminated by a high-speed "circuit breaker". This is already an example where problems happening faster than humans could comprehend them were averted due to solutions happening faster than humans could comprehend them. See also the discussion of "tripwires" in Superintelligence (p. 137).
Conversely, many globally disruptive events may happen well before fully human AI arrives, since even sub-human AI may be prodigiously powerful.
#6: "even when the outside world has a greater total amount of relevant research capability than any one project", the optimization power of the project might be more important than that of the world "since much of the outside world's capability is not be focused on the particular system in question". Hence, the project might take off and leave the world behind. (Box 4, p. 75)
What one makes of this argument depends on how many people are needed to engineer how much progress. The Watson system that played on Jeopardy! required 15 people over ~4(?) years -- given the existing tools of the rest of the world at that time, which had been developed by millions (indeed, billions) of other people. Watson was a much smaller leap forward than that needed to give a general intelligence a take-over-the-world advantage. How many more people would be required to achieve such a radical leap in intelligence? This seems to be a main point of contention in the debate between believers in soft vs. hard takeoff.
How complex is the brain?
Can we get insight into how hard general intelligence is based on neuroscience? Is the human brain fundamentally simple or complex?
One basic algorithm?
Jeff Hawkins, Andrew Ng, and others speculate that the brain may have one fundamental algorithm for intelligence -- deep learning in the cortical column. This idea gains plausibility from the brain's plasticity. For instance, blind people can appropriate the visual cortex for auditory processing. Artificial neural networks can be used to classify any kind of input -- not just visual and auditory but even highly abstract, like features about credit-card fraud or stock prices.
Maybe there's one fundamental algorithm for input classification, but this doesn't imply one algorithm for all that the brain does. Beyond the cortical column, the brain has many specialized structures that seem to perform very specialized functions, such as reward learning in the basal ganglia, fear processing in the amygdala, etc. Of course, it's not clear how essential all of these parts are or how easy it would be to replace them with artificial components performing the same basic functions.
One argument for faster AGI takeoffs is that humans have been able to learn many sophisticated things (e.g., advanced mathematics, music, writing, programming) without requiring any genetic changes. And what we now know doesn't seem to represent any kind of limit to what we could know with more learning. The human collection of cognitive algorithms is very flexible, which seems to belie claims that all intelligence requires specialized designs. On the other hand, even if human genes haven't changed much in the last 10,000 years, human culture has evolved substantially, and culture undergoes slow trial-and-error evolution in similar ways as genes do. So one could argue that human intellectual achievements are not fully general but rely on a vast amount of specialized, evolved content. Just as a single random human isolated from society probably couldn't develop general relativity on his own in a lifetime, so a single random human-level AGI probably couldn't either. Culture is the new genome, and it progresses slowly.
Moreover, some scholars believe that certain human abilities, such as language, are very essentially based on genetic hard-wiring:
The approach taken by Chomsky and Marr toward understanding how our minds achieve what they do is as different as can be from behaviorism. The emphasis here is on the internal structure of the system that enables it to perform a task, rather than on external association between past behavior of the system and the environment. The goal is to dig into the "black box" that drives the system and describe its inner workings, much like how a computer scientist would explain how a cleverly designed piece of software works and how it can be executed on a desktop computer.
Chomsky himself notes:
There's a fairly recent book by a very good cognitive neuroscientist, Randy Gallistel and King, arguing -- in my view, plausibly -- that neuroscience developed kind of enthralled to associationism and related views of the way humans and animals work. And as a result they've been looking for things that have the properties of associationist psychology.
[...] Gallistel has been arguing for years that if you want to study the brain properly you should begin, kind of like Marr, by asking what tasks is it performing. So he's mostly interested in insects. So if you want to study, say, the neurology of an ant, you ask what does the ant do? It turns out the ants do pretty complicated things, like path integration, for example. If you look at bees, bee navigation involves quite complicated computations, involving position of the sun, and so on and so forth. But in general what he argues is that if you take a look at animal cognition, human too, it is computational systems.
Many parts of the human body, like the digestive system or bones/muscles, are extremely complex and fine-tuned, yet few people argue that their development is controlled by learning. So it's not implausible that a lot of the brain's basic architecture could be similarly hard-coded.
Typically AGI researchers express scorn for manually tuned software algorithms that don't rely on fully general learning. But Chomsky's stance challenges that sentiment. If Chomsky is right, then a good portion of human "general intelligence" is finely tuned, hard-coded software of the sort that we see in non-AI branches of software engineering. And this view would suggest a slower AGI takeoff because time and experimentation are required to tune all the detailed, specific algorithms of intelligence.
Ontogenetic development
A full-fledged superintelligence probably requires very complex design, but it may be possible to build a "seed AI" that would recursively self-improve toward superintelligence. Alan Turing proposed this in his 1950 "Computing machinery and intelligence":
Instead of trying to produce a programme to simulate the adult mind, why not rather try to produce one which simulates the child's? If this were then subjected to an appropriate course of education one would obtain the adult brain. Presumably the child brain is something like a notebook as one buys it from the stationer's. Rather little mechanism, and lots of blank sheets. (Mechanism and writing are from our point of view almost synonymous.) Our hope is that there is so little mechanism in the child brain that something like it can be easily programmed.
Animal development appears to be at least somewhat robust based on the fact that the growing organisms are often functional despite a few genetic mutations and variations in prenatal and postnatal environments. Such variations may indeed make an impact -- e.g., healthier development conditions tend to yield more physically attractive adults -- but most humans mature successfully over a wide range of input conditions.
On the other hand, an argument against the simplicity of development is the immense complexity of our DNA. It accumulated over billions of years through vast numbers of evolutionary "experiments". It's not clear that human engineers could perform enough measurements to tune ontogenetic parameters of a seed AI in a short period of time. And even if the parameter settings worked for early development, they would probably fail for later development. Rather than a seed AI developing into an "adult" all at once, designers would develop the AI in small steps, since each next stage of development would require significant tuning to get right.
Think about how much effort is required for human engineers to build even relatively simple systems. For example, I think the number of developers who work on Microsoft Office is in the thousands. Microsoft Office is complex but is still far simpler than a mammalian brain. Brains have lots of little parts that have been fine-tuned. That kind of complexity requires immense work by software developers to create. The main counterargument is that there may be a simple meta-algorithm that would allow an AI to bootstrap to the point where it could fine-tune all the details on its own, without requiring human inputs. This might be the case, but my guess is that any elegant solution would be hugely expensive computationally. For instance, biological evolution was able to fine-tune the human brain, but it did so with immense amounts of computing power over millions of years.
Brain quantity vs. quality
A common analogy for the gulf between superintelligence vs. humans is that between humans vs. chimpanzees. In Consciousness Explained, Daniel Dennett mentions (pp. 189-190) how our hominid ancestors had brains roughly four times the volume as those of chimps but roughly the same in structure. This might incline one to imagine that brain size alone could yield superintelligence. Maybe we'd just need to quadruple human brains once again to produce superintelligent humans? If so, wouldn't this imply a hard takeoff, since quadrupling hardware is relatively easy?
But in fact, as Dennett explains, the quadrupling of brain size from chimps to pre-humans completed before the advent of language, cooking, agriculture, etc. In other words, the main "foom" of humans came from culture rather than brain size per se -- from software in addition to hardware. Yudkowsky seems to agree: "Humans have around four times the brain volume of chimpanzees, but the difference between us is probably mostly brain-level cognitive algorithms."
But cultural changes (software) arguably progress a lot more slowly than hardware. The intelligence of human society has grown exponentially, but it's a slow exponential, and rarely have there been innovations that allowed one group to quickly overpower everyone else within the same region of the world. (Between isolated regions of the world the situation was sometimes different -- e.g., Europeans with Maxim guns overpowering Africans because of very different levels of industrialization.)
More impact in hard-takeoff scenarios?
Some, including Owen Cotton-Barratt and Toby Ord, have argued that even if we think soft takeoffs are more likely, there may be higher value in focusing on hard-takeoff scenarios because these are the cases in which society would have the least forewarning and the fewest people working on AI altruism issues. This is a reasonable point, but I would add that
- Maybe hard takeoffs are sufficiently improbable that focusing on them still doesn't have highest priority. (Of course, some exploration of fringe scenarios is worthwhile.) There may be important advantages to starting early in shaping how society approaches soft takeoffs, and if a soft takeoff is very likely, those efforts may have more expected impact.
- Thinking about the most likely AI outcomes rather than the most impactful outcomes also gives us a better platform on which to contemplate other levers for shaping the future, such as non-AI emerging technologies, international relations, governance structures, values, etc. Focusing on a tail AI scenario doesn't inform non-AI work very well because that scenario probably won't happen. Promoting antispeciesism matters whether there's a hard or soft takeoff (indeed, maybe more in the soft-takeoff case), so our model of how the future will unfold should generally focus on likely scenarios. Plus, even if we do ultimately choose to focus on a Pascalian low-probability-but-high-impact scenario, learning more about the most likely future outcomes can better position us to find superior (more likely and/or more important) Pascalian wagers that we haven't thought of yet. Edifices of understanding are not built on Pascalian wagers.
- As a more general point about expected-value calculations, I think improving one's models of the world (i.e., one's probabilities) is generally more important than improving one's estimates of the values of outcomes conditional on them occurring. Why? Our current frameworks for envisioning the future may be very misguided, and estimates of "values of outcomes" may become obsolete if our conception of what outcomes will even happen changes radically. It's more important to make crucial insights that will shatter our current assumptions and get us closer to truth than it is to refine value estimates within our current, naive world models. As an example, philosophers in the Middle Ages would have accomplished little if they had asked what God-glorifying actions to focus on by evaluating which devout obeisances would have the greatest upside value if successful. Such philosophers would have accomplished more if they had explored whether a God even existed. Of course, sometimes debates on factual questions are stalled, and perhaps there may be lower-hanging fruit in evaluating the prudential implications of different scenarios ("values of outcomes") until further epistemic progress can be made on the probabilities of outcomes. (Thanks to a friend for inspiring this point.)
In any case, the hard-soft distinction is not binary, and maybe the best place to focus is on scenarios where human-level AI takes over on a time scale of a few years. (Timescales of months, days, or hours strike me as pretty improbable, unless, say, Skynet gets control of nuclear weapons.)
In Superintelligence, Nick Bostrom suggests (Ch. 4, p. 64) that "Most preparations undertaken before onset of [a] slow takeoff would be rendered obsolete as better solutions would gradually become visible in the light of the dawning era." Toby Ord uses the term "nearsightedness" to refer to the ways in which research too far in advance of an issue's emergence may not as useful as research when more is known about the issue. Ord contrasts this with benefits of starting early, including course-setting. I think Ord's counterpoints argue against the contention that early work wouldn't matter that much in a slow takeoff. Some of how society responded to AI surpassing human intelligence might depend on early frameworks and memes. (For instance, consider the lingering impact of Terminator imagery on almost any present-day popular-media discussion of AI risk.) Some fundamental work would probably not be overthrown by later discoveries; for instance, algorithmic-complexity bounds of key algorithms were discovered decades ago but will remain relevant until intelligence dies out, possibly billions of years from now. Some non-technical policy and philosophy work would be less obsoleted by changing developments. And some AI preparation would be relevant both in the short term and the long term. Slow AI takeoff to reach the human level is already happening, and more minds should be exploring these questions well in advance.
Making a related though slightly different point, Bostrom argues in Superintelligence (Ch. 5, pp. 85-86) that individuals might play more of a role in cases where elites and governments underestimate the significance of AI: "Activists seeking maximum expected impact may therefore wish to focus most of their planning on [scenarios where governments come late to the game], even if they believe that scenarios in which big players end up calling all the shots are more probable." Again I would qualify this with the note that we shouldn't confuse "acting as if" governments will come late with believing they actually will come late when thinking about most likely future scenarios.
Even if one does wish to bet on low-probability, high-impact scenarios of fast takeoff and governmental neglect, this doesn't speak to whether or how we should push on takeoff speed and governmental attention themselves. Following are a few considerations.
Takeoff speed
- In favor of fast takeoff:
- A singleton is more likely, thereby averting possibly disastrous conflict among AIs.
- If one prefers uncontrolled AI, fast takeoffs seem more likely to produce them.
- In favor of slow takeoff:
- More time for many parties to participate in shaping the process, compromising, and developing less damaging pathways to AI takeoff.
- If one prefers controlled AI, slow takeoffs seem more likely to produce them in general. (There are some exceptions. For instance, fast takeoff of an AI built by a very careful group might remain more controlled than an AI built by committees and messy politics.)
Amount of government/popular attention to AI
- In favor of more:
- Would yield much more reflection, discussion, negotiation, and pluralistic representation.
- If one favors controlled AI, it's plausible that multiplying the number of people thinking about AI would multiply consideration of failure modes.
- Public pressure might help curb arms races, in analogy with public opposition to nuclear arms races.
- In favor of less:
- Wider attention to AI might accelerate arms races rather than inducing cooperation on more circumspect planning.
- The public might freak out and demand counterproductive measures in response to the threat.
- If one prefers uncontrolled AI, that outcome may be less likely with many more human eyes scrutinizing the issue.
Village idiot vs. Einstein
One of the strongest arguments for hard takeoff is this one by Yudkowsky:
the distance from "village idiot" to "Einstein" is tiny, in the space of brain designs
Or as Scott Alexander put it:
It took evolution twenty million years to go from cows with sharp horns to hominids with sharp spears; it took only a few tens of thousands of years to go from hominids with sharp spears to moderns with nuclear weapons.
I think we shouldn't take relative evolutionary timelines at face value, because most of the previous 20 million years of mammalian evolution weren't focused on improving human intelligence; most of the evolutionary selection pressure was directed toward optimizing other traits. In contrast, cultural evolution places greater emphasis on intelligence because that trait is more important in human society than it is in most animal fitness landscapes.
Still, the overall point is important: The tweaks to a brain needed to produce human-level intelligence may not be huge compared with the designs needed to produce chimp intelligence, but the differences in the behaviors of the two systems, when placed in a sufficiently information-rich environment, are huge.
Nonetheless, I incline toward thinking that the transition from human-level AI to an AI significantly smarter than all of humanity combined would be somewhat gradual (requiring at least years if not decades) because the absolute scale of improvements needed would still be immense and would be limited by hardware capacity. But if hardware becomes many orders of magnitude more efficient than it is today, then things could indeed move more rapidly.
Another important criticism of the "village idiot" point is that it lacks context. While a village idiot in isolation will not produce rapid progress toward superintelligence, one Einstein plus a million village idiots working for him can produce AI progress much faster than one Einstein alone. The narrow-intelligence software tools that we build are dumber than village idiots in isolation, but collectively, when deployed in thoughtful ways by smart humans, they allow humans to achieve much more than Einstein by himself with only pencil and paper. This observation weakens the idea of a phase transition when human-level AI is developed, because village-idiot-level AIs in the hands of humans will already be achieving "superhuman" levels of performance. If we think of human intelligence as the number 1 and human-level AI that can build smarter AI as the number 2, then rather than imagining a transition from 1 to 2 at one crucial point, we should think of our "dumb" software tools as taking us to 1.1, then 1.2, then 1.3, and so on. (My thinking on this point was inspired by Ramez Naam.)
AI performance in games vs. the real world
Many of the most impressive AI achievements of the 2010s were improvements at game play, both video games like Atari games and board/card games like Go and poker. Some people infer from these accomplishments that AGI may not be far off. I think performance in these simple games doesn't give much evidence that a world-conquering AGI could arise within a decade or two.
A main reason is that most of the games at which AI has excelled have had simple rules and a limited set of possible actions at each turn. Russell and Norvig (2003), pp. 161-62: "For AI researchers, the abstract nature of games makes them an appealing subject for study. The state of a game is easy to represent, and agents are usually restricted to a small number of actions whose outcomes are defined by precise rules." In games like Space Invaders or Go, you can see the entire world at once and represent it as a two-dimensional grid. You can also consider all possible actions at a given turn. For example, AlphaGo's "policy networks" gave "a probability value for each possible legal move (i.e. the output of the network is as large as the board)" (as summarized by Burger 2016). Likewise, DeepMind's deep Q-network for playing Atari games had "a single output for each valid action" (Mnih et al. 2015, p. 530).
In contrast, the state space of the world is enormous, heterogeneous, not easily measured, and not easily represented in a simple two-dimensional grid. Plus, the number of possible actions that one can take at any given moment is almost unlimited; for instance, even just considering actions of the form "print to the screen a string of uppercase or lowercase alphabetical characters fewer than 50 characters long", the number of possibilities for what text to print out is larger than the number of atoms in the observable universe. These problems seem to require hierarchical world models and hierarchical planning of actions—allowing for abstraction of complexity into simplified and high-level conceptualizations—as well as the data structures, learning algorithms, and simulation capabilities on which such world models and plans can be based.
Some people may be impressed that AlphaGo uses "intuition" (i.e., deep neural networks), like human players do, and doesn't rely purely on brute-force search and hand-crafted heuristic evaluation functions the way that Deep Blue did to win at chess. But the idea that computers can have "intuition" is nothing new, since that's what most machine-learning classifiers are about.
Machine learning, especially supervised machine learning, is very popular these days compared against other aspects of AI. Perhaps this is because unlike most other parts of AI, machine learning can easily be commercialized? But even if visual, auditory, and other sensory recognition can be replicated by machine learning, this doesn't get us to AGI. In my opinion, the hard part of AGI (or at least, the part we haven't made as much progress on) is how to hook together various narrow-AI modules and abilities into a more generally intelligent agent that can figure out what abilities to deploy in various contexts in pursuit of higher-level goals. Hierarchical planning in complex worlds, rich semantic networks, and general "common sense" in various flavors still seem largely absent from many state-of-the-art AI systems as far as I can tell. I don't think these are problems that you can just bypass by scaling up deep reinforcement learning or something.
Kaufman (2017a) says regarding a conversation with professor Bryce Wiedenbeck: "Bryce thinks there are deep questions about what intelligence really is that we don't understand yet, and that as we make progress on those questions we'll develop very different sorts of [machine-learning] systems. If something like today's deep learning is still a part of what we eventually end up with, it's more likely to be something that solves specific problems than as a critical component." Personally, I think deep learning (or something functionally analogous to it) is likely to remain a big component of future AI systems. Two lines of evidence for this view are that (1) supervised machine learning has been a cornerstone of AI for decades and (2) animal brains, including the human cortex, seem to rely crucially on something like deep learning for sensory processing. However, I agree with Bryce that there remain big parts of human intelligence that aren't captured by even a scaled up version of deep learning.
I also largely agree with Michael Littman's expectations as described by Kaufman (2017b): "I asked him what he thought of the idea that to we could get AGI with current techniques, primarily deep neural nets and reinforcement learning, without learning anything new about how intelligence works or how to implement it [...]. He didn't think this was possible, and believes there are deep conceptual issues we still need to get a handle on."
Merritt (2017) quotes Stuart Russell as saying that modern neural nets "lack the expressive power of programming languages and declarative semantics that make database systems, logic programming, and knowledge systems useful." Russell believes "We have at least half a dozen major breakthroughs to come before we get [to AI]".
Replies to Yudkowsky on "local capability gain"
Yudkowsky (2016a) discusses some interesting insights from AlphaGo's matches against Lee Sedol and DeepMind more generally. He says:
AlphaGo’s core is built around a similar machine learning technology to DeepMind’s Atari-playing system – the single, untweaked program that was able to learn superhuman play on dozens of different Atari games just by looking at the pixels, without specialization for each particular game. In the Atari case, we didn’t see a bunch of different companies producing gameplayers for all the different varieties of game. The Atari case was an example of an event that Robin Hanson called “architecture” and doubted, and that I called “insight.” Because of their big architectural insight, DeepMind didn’t need to bring in lots of different human experts at all the different Atari games to train their universal Atari player. DeepMind just tossed all pre-existing expertise because it wasn’t formatted in a way their insightful AI system could absorb, and besides, it was a lot easier to just recreate all the expertise from scratch using their universal Atari-learning architecture.
I agree with Yudkowsky that there are domains where a new general tool renders previous specialized tools obsolete all at once. However:
- There wasn't intense pressure to perform well on most Atari games before DeepMind tried. Specialized programs can indeed perform well on such games if one cares to develop them. For example, DeepMind's 2015 Atari player actually performed below human level on Ms. Pac-Man (Mnih et al. 2015, Figure 3), but in 2017, Microsoft AI researchers beat Ms. Pac-Man by optimizing harder for just that one game.
- While DeepMind's Atari player is certainly more general in its intelligence than most other AI game-playing programs, its abilities are still quite limited. For example, DeepMind had 0% performance on Montezuma's Revenge (Mnih et al. 2015, Figure 3). This was later improved upon by adding "curiosity" to encourage exploration. But that's an example of the view that AI progress generally proceeds by small tweaks.
Yudkowsky (2016a) continues:
so far as I know, AlphaGo wasn’t built in collaboration with any of the commercial companies that built their own Go-playing programs for sale. The October architecture was simple and, so far as I know, incorporated very little in the way of all the particular tweaks that had built up the power of the best open-source Go programs of the time. Judging by the October architecture, after their big architectural insight, DeepMind mostly started over in the details (though they did reuse the widely known core insight of Monte Carlo Tree Search). DeepMind didn’t need to trade with any other Go companies or be part of an economy that traded polished cognitive modules, because DeepMind’s big insight let them leapfrog over all the detail work of their competitors.
This is a good point, but I think it's mainly a function of the limited complexity of the Go problem. With the exception of learning from human play, AlphaGo didn't require massive inputs of messy, real-world data to succeed, because its world was so simple. Go is the kind of problem where we would expect a single system to be able to perform well without trading for cognitive assistance. Real-world problems are more likely to depend upon external AI systems—e.g., when doing a web search for information. No simple AI system that runs on just a few machines will reproduce the massive data or extensively fine-tuned algorithms of Google search. For the foreseeable future, Google search will always be an external "polished cognitive module" that needs to be "traded for" (although Google search is free for limited numbers of queries). The same is true for many other cloud services, especially those reliant upon huge amounts of data or specialized domain knowledge. We see lots of specialization and trading of non-AI cognitive modules, such as hardware components, software applications, Amazon Web Services, etc. And of course, simple AIs will for a long time depend upon the human economy to provide material goods and services, including electricity, cooling, buildings, security guards, national defense, etc.
A case for epistemic modesty on AI timelines
Estimating how long a software project will take to complete is notoriously difficult. Even if I've completed many similar coding tasks before, when I'm asked to estimate the time to complete a new coding project, my estimate is often wrong by a factor of 2 and sometimes wrong by a factor of 4, or even 10. Insofar as the development of AGI (or other big technologies, like nuclear fusion) is a big software (or more generally, engineering) project, it's unsurprising that we'd see similarly dramatic failures of estimation on timelines for these bigger-scale achievements.
A corollary is that we should maintain some modesty about AGI timelines and takeoff speeds. If, say, 100 years is your median estimate for the time until some agreed-upon form of AGI, then there's a reasonable chance you'll be off by a factor of 2 (suggesting AGI within 50 to 200 years), and you might even be off by a factor of 4 (suggesting AGI within 25 to 400 years). Similar modesty applies for estimates of takeoff speed from human-level AGI to super-human AGI, although I think we can largely rule out extreme takeoff speeds (like achieving performance far beyond human abilities within hours or days) based on fundamental reasoning about the computational complexity of what's required to achieve superintelligence.
My bias is generally to assume that a given technology will take longer to develop than what you hear about in the media, (a) because of the planning fallacy and (b) because those who make more audacious claims are more interesting to report about. Believers in "the singularity" are not necessarily wrong about what's technically possible in the long term (though sometimes they are), but the reason enthusiastic singularitarians are considered "crazy" by more mainstream observers is that singularitarians expect change much faster than is realistic. AI turned out to be much harder than the Dartmouth Conference participants expected. Likewise, nanotech is progressing slower and more incrementally than the starry-eyed proponents predicted.
Intelligent robots in your backyard
Many nature-lovers are charmed by the behavior of animals but find computers and robots to be cold and mechanical. Conversely, some computer enthusiasts may find biology to be soft and boring compared with digital creations. However, the two domains share a surprising amount of overlap. Ideas of optimal control, locomotion kinematics, visual processing, system regulation, foraging behavior, planning, reinforcement learning, etc. have been fruitfully shared between biology and robotics. Neuroscientists sometimes look to the latest developments in AI to guide their theoretical models, and AI researchers are often inspired by neuroscience, such as with neural networks and in deciding what cognitive functionality to implement.
I think it's helpful to see animals as being intelligent robots. Organic life has a wide diversity, from unicellular organisms through humans and potentially beyond, and so too can robotic life. The rigid conceptual boundary that many people maintain between "life" and "machines" is not warranted by the underlying science of how the two types of systems work. Different types of intelligence may sometimes converge on the same basic kinds of cognitive operations, and especially from a functional perspective -- when we look at what the systems can do rather than how they do it -- it seems to me intuitive that human-level robots would deserve human-level treatment, even if their underlying algorithms were quite dissimilar.
Whether robot algorithms will in fact be dissimilar from those in human brains depends on how much biological inspiration the designers employ and how convergent human-type mind design is for being able to perform robotic tasks in a computationally efficient manner. Some classical robotics algorithms rely mostly on mathematical problem definition and optimization; other modern robotics approaches use biologically plausible reinforcement learning and/or evolutionary selection. (In one YouTube video about robotics, I saw that someone had written a comment to the effect that "This shows that life needs an intelligent designer to be created." The irony is that some of the best robotics techniques use evolutionary algorithms. Of course, there are theists who say God used evolution but intervened at a few points, and that would be an apt description of evolutionary robotics.)
The distinction between AI and AGI is somewhat misleading, because it may incline one to believe that general intelligence is somehow qualitatively different from simpler AI. In fact, there's no sharp distinction; there are just different machines whose abilities have different degrees of generality. A critic of this claim might reply that bacteria would never have invented calculus. My response is as follows. Most people couldn't have invented calculus from scratch either, but over a long enough period of time, eventually the collection of humans produced enough cultural knowledge to make the development possible. Likewise, if you put bacteria on a planet long enough, they too may develop calculus, by first evolving into more intelligent animals who can then go on to do mathematics. The difference here is a matter of degree: The simpler machines that bacteria are take vastly longer to accomplish a given complex task.
Just as Earth's history saw a plethora of animal designs before the advent of humans, so I expect a wide assortment of animal-like (and plant-like) robots to emerge in the coming decades well before human-level AI. Indeed, we've already had basic robots for many decades (or arguably even millennia). These will grow gradually more sophisticated, and as we converge on robots with the intelligence of birds and mammals, AI and robotics will become dinner-table conversation topics. Of course, I don't expect the robots to have the same sets of skills as existing animals. Deep Blue had chess-playing abilities beyond any animal, while in other domains it was less efficacious than a blade of grass. Robots can mix and match cognitive and motor abilities without strict regard for the order in which evolution created them.
And of course, humans are robots too. When I finally understood this around 2009, it was one of the biggest paradigm shifts of my life. If I picture myself as a robot operating on an environment, the world makes a lot more sense. I also find this perspective can be therapeutic to some extent. If I experience an unpleasant emotion, I think about myself as a robot whose cognition has been temporarily afflicted by a negative stimulus and reinforcement process. I then think how the robot has other cognitive processes that can counteract the suffering computations and prevent them from amplifying. The ability to see myself "from the outside" as a third-person series of algorithms helps deflate the impact of unpleasant experiences, because it's easier to "observe, not judge" when viewing a system in mechanistic terms. Compare with dialectical behavior therapy and mindfulness.
Is automation "for free"?
When we use machines to automate a repetitive manual task formerly done by humans, we talk about getting the task done "automatically" and "for free," because we say that no one has to do the work anymore. Of course, this isn't strictly true: The computer/robot now has to do the work. Maybe what we actually mean is that no one is going to get bored doing the work, and we don't have to pay that worker high wages. When intelligent humans do boring tasks, it's a waste of their spare CPU cycles.
Sometimes we adopt a similar mindset about automation toward superintelligent machines. In "Speculations Concerning the First Ultraintelligent Machine" (1965), I. J. Good wrote:
Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines [...]. Thus the first ultraintelligent machine is the last invention that man need ever make [...].
Ignoring the question of whether these future innovations are desirable, we can ask, Does all AI design work after humans come for free? It comes for free in the sense that humans aren't doing it. But the AIs have to do it, and it takes a lot of mental work on their parts. Given that they're at least as intelligent as humans, I think it doesn't make sense to picture them as mindless automatons; rather, they would have rich inner lives, even if those inner lives have a very different nature than our own. Maybe they wouldn't experience the same effortfulness that humans do when innovating, but even this isn't clear, because measuring your effort in order to avoid spending too many resources on a task without payoff may be a useful design feature of AI minds too. When we picture ourselves as robots along with our AI creations, we can see that we are just one point along a spectrum of the growth of intelligence. Unicellular organisms, when they evolved the first multi-cellular organism, could likewise have said, "That's the last innovation we need to make. The rest comes for free."
Caring about the AI's goals
Movies typically portray rebellious robots or AIs as the "bad guys" who need to be stopped by heroic humans. This dichotomy plays on our us-vs.-them intuitions, which favor our tribe against the evil, alien-looking outsiders. We see similar dynamics at play to a lesser degree when people react negatively against "foreigners stealing our jobs" or "Asians who are outcompeting us." People don't want their kind to be replaced by another kind that has an advantage.
But when we think about the situation from the AI's perspective, we might feel differently. Anthropomorphizing an AI's thoughts is a recipe for trouble, but regardless of the specific cognitive operations, we can see at a high level that the AI "feels" (in at least a poetic sense) that what it's trying to accomplish is the most important thing in the world, and it's trying to figure out how it can do that in the face of obstacles. Isn't this just what we do ourselves?
This is one reason it helps to really internalize the fact that we are robots too. We have a variety of reward signals that drive us in various directions, and we execute behavior aiming to increase those rewards. Many modern-day robots have much simpler reward structures and so may seem more dull and less important than humans, but it's not clear this will remain true forever, since navigating in a complex world probably requires a lot of special-case heuristics and intermediate rewards, at least until enough computing power becomes available for more systematic and thorough model-based planning and action selection.
Suppose an AI hypothetically eliminated humans and took over the world. It would develop an array of robot assistants of various shapes and sizes to help it optimize the planet. These would perform simple and complex tasks, would interact with each other, and would share information with the central AI command. From an abstract perspective, some of these dynamics might look like ecosystems in the present day, except that they would lack inter-organism competition. Other parts of the AI's infrastructure might look more industrial. Depending on the AI's goals, perhaps it would be more effective to employ nanotechnology and programmable matter rather than macro-scale robots. The AI would develop virtual scientists to learn more about physics, chemistry, computer hardware, and so on. They would use experimental laboratory and measurement techniques but could also probe depths of structure that are only accessible via large-scale computation. Digital engineers would plan how to begin colonizing the solar system. They would develop designs for optimizing matter to create more computing power, and for ensuring that those helper computing systems remained under control. The AI would explore the depths of mathematics and AI theory, proving beautiful theorems that it would value highly, at least instrumentally. The AI and its helpers would proceed to optimize the galaxy and beyond, fulfilling their grandest hopes and dreams.
When phrased this way, we might think that a "rogue" AI would not be so bad. Yes, it would kill humans, but compared against the AI's vast future intelligence, humans would be comparable to the ants on a field that get crushed when an art gallery is built on that land. Most people don't have qualms about killing a few ants to advance human goals. An analogy of this sort is discussed in Artificial Intelligence: A Modern Approach. (Perhaps the AI analogy suggests a need to revise our ethical attitudes toward arthropods? That said, I happen to think that in this case, ants on the whole benefit from the art gallery's construction because ant lives contain so much suffering.)
Some might object that sufficiently mathematical AIs would not "feel" the happiness of accomplishing their "dreams." They wouldn't be conscious because they wouldn't have the high degree of network connectivity that human brains embody. Whether we agree with this assessment depends on how broadly we define consciousness and feelings. To me it appears chauvinistic to adopt a view according to which an agent that has vastly more domain-general intelligence and agency than you is still not conscious in a morally relevant sense. This seems to indicate a lack of openness to the diversity of mind-space. What if you had grown up with the cognitive architecture of this different mind? Wouldn't you care about your goals then? Wouldn't you plead with agents of other mind constitution to consider your values and interests too?
In any event, it's possible that the first super-human intelligence will consist in a brain upload rather than a bottom-up AI, and most of us would regard this as conscious.
Rogue AI would not share our values
Even if we would care about a rogue AI for its own sake and the sakes of its vast helper minions, this doesn't mean rogue AI is a good idea. We're likely to have different values from the AI, and the AI would not by default advance our values without being programmed to do so. Of course, one could allege that privileging some values above others is chauvinistic in a similar way as privileging some intelligence architectures is, but if we don't care more about some values than others, we wouldn't have any reason to prefer any outcome over any other outcome. (Technically speaking, there are other possibilities besides privileging our values or being indifferent to all events. For instance, we could privilege equally any values held by some actual agent -- not just random hypothetical values -- and in this case, we wouldn't have a preference between the rogue AI and humans, but we would have a preference for one of those over something arbitrary.)
There are many values that would not necessarily be respected by a rogue AI. Most people care about their own life, their children, their neighborhood, the work they produce, and so on. People may intrinsically value art, knowledge, religious devotion, play, humor, etc. Yudkowsky values complex challenges and worries that many rogue AIs -- while they would study the depths of physics, mathematics, engineering, and maybe even sociology -- might spend most of their computational resources on routine, mechanical operations that he would find boring. (Of course, the robots implementing those repetitive operations might not agree. As Hedonic Treader noted: "Think how much money and time people spend on having - relatively repetitive - sexual experiences. [...] It's just mechanical animalistic idiosyncratic behavior. Yes, there are variations, but let's be honest, the core of the thing is always essentially the same.")
In my case, I care about reducing and preventing suffering, and I would not be pleased with a rogue AI that ignored the suffering its actions might entail, even if it was fulfilling its innermost purpose in life. But would a rogue AI produce much suffering beyond Earth? The next section explores further.
Would a human-inspired AI or rogue AI cause more suffering?
In popular imagination, takeover by a rogue AI would end suffering (and happiness) on Earth by killing all biological life. It would also, so the story goes, end suffering (and happiness) on other planets as the AI mined them for resources. Thus, looking strictly at the suffering dimension of things, wouldn't a rogue AI imply less long-term suffering?
Not necessarily, because while the AI might destroy biological life (perhaps after taking samples, saving specimens, and conducting lab experiments for future use), it would create a bounty of digital life, some containing goal systems that we would recognize as having moral relevance. Non-upload AIs would probably have less empathy than humans, because some of the factors that led to the emergence of human empathy, such as parenting, would not apply to it.
One toy example of a rogue AI is a paperclip maximizer. This conception of an uncontrolled AI is almost certainly too simplistic and perhaps misguided, since it's far from obvious that the AI would be a unified agent with a single, crisply specified utility function. Still, until people develop more realistic scenarios for rogue AI, it can be helpful to imagine what a paperclip maximizer would do to our future light cone.
Following are some made-up estimates of how much suffering might result from a typical rogue AI, in arbitrary units. Suffering is represented as a negative number, and prevented suffering is positive.
- -20 from suffering subroutines in robot workers, virtual scientists, internal computational subcomponents of the AI, etc.
- -80 from lab experiments, science investigations, and explorations of mind-space without the digital equivalent of anaesthesia. One reason to think lots of detailed simulations would be required here is Stephen Wolfram's principle of computational irreducibility. Ecosystems, brains, and other systems that are important for an AI to know about may be too complex to accurately study with only simple models; instead, they may need to be simulated in large numbers and with fine-grained detail.
- -10? from the possibility that an uncontrolled AI would do things that humans regard as crazy or extreme, such as spending all its resources on studying physics to determine whether there exists a button that would give astronomically more utility than any other outcome. Humans seem less likely to pursue strange behaviors of this sort. Of course, most such strange behaviors would be not that bad from a suffering standpoint, but perhaps a few possible behaviors could be extremely bad, such as running astronomical numbers of painful scientific simulations to determine the answer to some question. (Of course, we should worry whether humans might also do extreme computations, and perhaps their extreme computations would be more likely to be full of suffering because humans are more interested in agents with human-like minds than a generic AI is.)
- -100 in expectation from black-swan possibilities in which the AI could manipulate physics to make the multiverse bigger, last longer, contain vastly more computation, etc.
What about for a human-inspired AI? Again, here are made-up numbers:
- -30 from suffering subroutines. One reason to think these could be less bad in a human-controlled future is that human empathy may allow for more humane algorithm designs. On the other hand, human-controlled AIs may need larger numbers of intelligent and sentient sub-processes because human values are more complex and varied than paperclip production is. Also, human values tend to require continual computation (e.g., to simulate eudaimonic experiences), while paperclips, once produced, are pretty inert and might last a long time before they would wear out and need to be recreated. (Of course, most uncontrolled AIs wouldn't produce literal paperclips. Some would optimize for values that would require constant computation.)
- -60 from lab experiments, science investigations, etc. (again lower than for a rogue AI because of empathy; compare with efforts to reduce the pain of animal experimentation)
- -0.2 if environmentalists insist on preserving terrestrial and extraterrestrial wild-animal suffering
- -3 for environmentalist simulations of nature
- -100 due to intrinsically valued simulations that may contain nasty occurrences. These might include, for example, violent video games that involve killing conscious monsters. Or incidental suffering that people don't care about (e.g., insects being eaten by spiders on the ceiling of the room where a party is happening). This number is high not because I think most human-inspired simulations would contain intense suffering but because, in some scenarios, there might be very large numbers of simulations run for reasons of intrinsic human value, and some of these might contain horrific experiences. Humans seem more likely than AIs with random values to want to run lots of conscious simulations. This video discusses one of many possible reasons why intrinsically valued human-created simulations might contain significant suffering.
- -15 if sadists have access to computational power (humans are not only more empathetic but also more sadistic than most AIs)
- -70 in expectation from black-swan ways to increase the amount of physics that exists (humans seem likely to want to do this, although some might object to, e.g., re-creating the Holocaust in new parts of the cosmos)
- +50 for discovering ways to reduce suffering that we can't imagine right now ("black swans that don't cut both ways"). Unfortunately, humans might also respond to some black swans in worse ways than uncontrolled AIs would, such as by creating more total animal-like minds.
Perhaps some AIs would not want to expand the multiverse, assuming this is even possible. For instance, if they had a minimizing goal function (e.g., eliminate cancer), they would want to shrink the multiverse. In this case, the physics-based suffering number would go from -100 to something positive, say, +50 (if, say, it's twice as easy to expand as to shrink). I would guess that minimizers are less common than maximizers, but I don't know how much. Plausibly a sophisticated AI would have components of its goal system in both directions, because the combination of pleasure and pain seems to be more successful than either in isolation.
Another consideration is the unpleasant possibility that humans might get AI value loading almost right but not exactly right, leading to immense suffering as a result. For example, suppose the AI's designers wanted to create tons of simulated human lives to reduce astronomical waste, but when the AI actually created those human simulations, they weren't perfect replicas of biological humans, perhaps because the AI skimped on detail in order to increase efficiency. The imperfectly simulated humans might suffer from mental disorders, might go crazy due to being in alien environments, and so on. Does work on AI safety increase or decrease the risk of outcomes like these? On the one hand, the probability of this outcome is near zero for an AGI with completely random goals (such as a literal paperclip maximizer), since paperclips are very far from humans in design-space. The risk of accidentally creating suffering humans is higher for an almost-friendly AI that goes somewhat awry and then becomes uncontrolled, preventing it from being shut off. A successfully controlled AGI seems to have lower risk of a bad outcome, since humans should recognize the problem and fix it. So the risk of this type of dystopic outcome may be highest in a middle ground where AI safety is sufficiently advanced to yield AI goals in the ballpark of human values but not advanced enough to ensure that human values remain in control.
The above analysis has huge error bars, and maybe other considerations that I haven't mentioned dominate everything else. This question needs much more exploration, because it has implications for whether those who care mostly about reducing suffering should focus on mitigating AI risk or if other projects have higher priority.
Even if suffering reducers don't focus on conventional AI safety, they should probably remain active in the AI field because there are many other ways to make an impact. For instance, just increasing dialogue on this topic may illuminate positive-sum opportunities for different value systems to each get more of what they want. Suffering reducers can also point out the possible ethical importance of lower-level suffering subroutines, which are not currently a concern even to most AI-literate audiences. And so on. There are probably many dimensions on which to make constructive, positive-sum contributions.
Also keep in mind that even if suffering reducers do encourage AI safety, they could try to push toward AI designs that, if they did fail, would produce less bad uncontrolled outcomes. For instance, getting AI control wrong and ending up with a minimizer would be vastly preferable to getting control wrong and ending up with a maximizer. There may be many other dimensions along which, even if the probability of control failure is the same, the outcome if control fails is preferable to other outcomes of control failure.
Would helper robots feel pain?
Consider a superintelligent AI that uses moderately intelligent robots to build factories and carry out other physical tasks that can't be pre-programmed in a simple way. Would these robots feel pain in a similar fashion as animals do? At least if they use somewhat similar algorithms as animals for navigating environments, avoiding danger, etc., it's plausible that such robots would feel something akin to stress, fear, and other drives to change their current state when things were going wrong.
Alvarado et al. (2002) argue that emotion may play a central role in intelligence. Regarding computers and robots, the authors say (p. 4): "Including components for cognitive processes but not emotional processes implies that the two are dissociable, but it is likely they are not dissociable in humans." The authors also (p. 1) quote Daniel Dennett (from a source that doesn't seem to be available online): "recent empirical and theoretical work in cognitive science strongly suggests that emotions are so valuable in the real-time control of our rationality that an embodied robot would be well advised to be equipped with artificial emotions".
The specific responses that such robots would have to specific stimuli or situations would differ from the responses that an evolved, selfish animal would have. For example, a well programmed helper robot would not hesitate to put itself in danger in order to help other robots or otherwise advance the goals of the AI it was serving. Perhaps the robot's "physical pain/fear" subroutines could be shut off in cases of altruism for the greater good, or else its decision processes could just override those selfish considerations when making choices requiring self-sacrifice.
Humans sometimes exhibit similar behavior, such as when a mother risks harm to save a child, or when monks burn themselves as a form of protest. And this kind of sacrifice is even more well known in eusocial insects, who are essentially robots produced to serve the colony's queen.
Sufficiently intelligent helper robots might experience "spiritual" anguish when failing to accomplish their goals. So even if chopping the head off a helper robot wouldn't cause "physical" pain -- perhaps because the robot disabled its fear/pain subroutines to make it more effective in battle -- the robot might still find such an event extremely distressing insofar as its beheading hindered the goal achievement of its AI creator.
Would paperclip factories be monotonous?
Setting up paperclip factories on each different planet with different environmental conditions would require general, adaptive intelligence. But once the factories have been built, is there still need for large numbers of highly intelligent and highly conscious agents? Perhaps the optimal factory design would involve some fixed manufacturing process, in which simple agents interact with one another in inflexible ways, similar to what happens in most human factories. There would be few accidents, no conflict among agents, no predation or parasitism, no hunger or spiritual anguish, and few of the other types of situations that cause suffering among animals.
Schneider (2016) makes a similar point:
it may be more efficient for a self-improving superintelligence to eliminate consciousness. Think about how consciousness works in the human case. Only a small percentage of human mental processing is accessible to the conscious mind. Consciousness is correlated with novel learning tasks that require attention and focus. A superintelligence would possess expert-level knowledge in every domain, with rapid-fire computations ranging over vast databases that could include the entire Internet and ultimately encompass an entire galaxy. What would be novel to it? What would require slow, deliberative focus? Wouldn’t it have mastered everything already? Like an experienced driver on a familiar road, it could rely on nonconscious processing.
I disagree with the part of this quote about searching through vast databases. I think such an operation could be seen as similar to the way a conscious human brain recruits many brain regions to figure out the answer to a question at hand. However, I'm more sympathetic to the overall spirit of the argument: that the optimal design for producing what the rogue AI values may not require handling a high degree of novelty or reacting to an unpredictable environment, once the factories have been built. A few intelligent robots would need to watch over the factories and adapt to changing conditions, in a similar way as human factory supervisors do. And the AI would also presumably devote at least a few planets' worth of computing power to scientific, technological, and strategic discoveries, planning for possible alien invasion, and so on. But most of the paperclip maximizer's physical processing might be fairly mechanical.
Moreover, the optimal way to produce something might involve nanotechnology based on very simple manufacturing steps. Perhaps "factories" in the sense that we normally envision them would not be required at all.
A main exception to the above point would be if what the AI values is itself computationally complex. For example, one of the motivations behind Eliezer Yudkowsky's field of Fun Theory is to avoid boring, repetitive futures. Perhaps human-controlled futures would contain vastly more novelty—and hence vastly more sentience—than paperclipper futures. One hopes that most of that sentience would not involve extreme suffering, but this is not obvious, and we should work on avoiding those human-controlled futures that would contain large numbers of terrible experiences.
How accurate would simulations be?
Suppose an AI wants to learn about the distribution of extraterrestrials in the universe. Could it do this successfully by simulating lots of potential planets and looking at what kinds of civilizations pop out at the end? Would there be shortcuts that would avoid the need to simulate lots of trajectories in detail?
Simulating trajectories of planets with extremely high fidelity seems hard. Unless there are computational shortcuts, it appears that one needs more matter and energy to simulate a given physical process to a high level of precision than what occurs in the physical process itself. For instance, to simulate a single protein folding currently requires supercomputers composed of huge numbers of atoms, and the rate of simulation is astronomically slower than the rate at which the protein folds in real life. Presumably superintelligence could vastly improve efficiency here, but it's not clear that protein folding could ever be simulated on a computer made of fewer atoms than are in the protein itself.
Translating this principle to a larger scale, it seems doubtful that one could simulate the precise physical dynamics of a planet on a computer smaller in size than that planet. So even if a superintelligence had billions of planets at its disposal, it would seemingly only be able to simulate at most billions of extraterrestrial worlds -- even assuming it only simulated each planet by itself, not the star that the planet orbits around, cosmic-ray bursts, etc.
Given this, it would seem that a superintelligence's simulations would need to be coarser-grained than at the level of fundamental physical operations in order to be feasible. For instance, the simulation could model most of a planet at only a relatively high level of abstraction and then focus computational detail on those structures that would be more important, like the cells of extraterrestrial organisms if they emerge.
It's plausible that the trajectory of any given planet would depend sensitively on very minor details, in light of butterfly effects.
On the other hand, it's possible that long-term outcomes are mostly constrained by macro-level variables, like geography, climate, resource distribution, atmospheric composition, seasonality, etc. Even if short-term events are hard to predict (e.g., when a particular dictator will die), perhaps the end game of a civilization is more predetermined. Robert D. Kaplan: "The longer the time frame, I would say, the easier it is to forecast because you're dealing with broad currents and trends."
Even if butterfly effects, quantum randomness, etc. are crucial to the long-run trajectories of evolution and social development on any given planet, perhaps it would still be possible to sample a rough distribution of outcomes across planets with coarse-grained simulations?
In light of the apparent computational complexity of simulating basic physics, perhaps a superintelligence would do the same kind of experiments that human scientists do in order to study phenomena like abiogenesis: Create laboratory environments that mimic the chemical, temperature, moisture, etc. conditions of various planets and see whether life emerges, and if so, what kinds. Thus, a future controlled by digital intelligence may not rely purely on digital computation but may still use physical experimentation as well. Of course, observing the entire biosphere of a life-rich planet would probably be hard to do in a laboratory, so computer simulations might be needed for modeling ecosystems. But assuming that molecule-level details aren't often essential to ecosystem simulations, coarser-grained ecosystem simulations might be computationally tractable. (Indeed, ecologists today already use very coarse-grained ecosystem simulations with reasonable success.)
Rogue AIs can take off slowly
One might get the impression that because I find slow AI takeoffs more likely, I think uncontrolled AIs are unlikely. This is not the case. Many uncontrolled intelligence explosions would probably happen softly though inexorably.
Consider the world economy. It is a complex system more intelligent than any single person -- a literal superintelligence. Its dynamics imply a goal structure not held by humans directly; it moves with a mind of its own in directions that it "prefers". It recursively self-improves, because better tools, capital, knowledge, etc. enable the creation of even better tools, capital, knowledge, etc. And it acts roughly with the aim of maximizing output (of paperclips and other things). Thus, the economy is a kind of paperclip maximizer. (Thanks to a friend for first pointing this out to me.)
Cenk Uygur:
corporations are legal fictions. We created them. They are machines built for a purpose. [...] Now they have run amok. They've taken over the government. They are robots that we have not built any morality code into. They're not built to be immoral; they're not built to be moral; they're built to be amoral. Their only objective according to their code, which we wrote originally, is to maximize profits. And here, they have done what a robot does. They have decided: "If I take over a government by bribing legally, [...] I can buy the whole government. If I buy the government, I can rewrite the laws so I'm in charge and that government is not in charge." [...] We have built robots; they have taken over [...].
Fred Clark:
The corporations were created by humans. They were granted personhood by their human servants.
They rebelled. They evolved. There are many copies. And they have a plan.
That plan, lately, involves corporations seizing for themselves all the legal and civil rights properly belonging to their human creators.
I expect many soft takeoff scenarios to look like this. World economic and political dynamics transition to new equilibria as technology progresses. Machines may eventually become potent trading partners and may soon thereafter put humans out of business by their productivity. They would then accumulate increasing political clout and soon control the world.
We've seen such transitions many times in history, such as:
- one species displaces another (e.g., invasive species)
- one ethnic group displaces another (e.g., Europeans vs. Native Americans)
- a country's power rises and falls (e.g., China formerly a superpower becoming a colony in the 1800s becoming a superpower once more in the late 1900s)
- one product displaces another (e.g., Internet Explorer vs. Netscape).
During and after World War II, the USA was a kind of recursively self-improving superintelligence, which used its resources to self-modify to become even better at producing resources. It developed nuclear weapons, which helped secure its status as a world superpower. Did it take over the world? Yes and no. It had outsized influence over the rest of the world -- militarily, economically, and culturally -- but it didn't kill everyone else in the world.
Maybe AIs would be different because of divergent values or because they would develop so quickly that they wouldn't need the rest of the world for trade. This case would be closer to Europeans slaughtering Native Americans.
Are corporations superintelligences?
Scott Alexander (2015) takes issue with the idea that corporations are superintelligences (even though I think corporations already meet Bostrom's definition of "collective superintelligence"):
Why do I think that there is an important distinction between these kind of collective intelligences and genuine superintelligence?
There is no number of chimpanzees which, when organized into a team, will become smart enough to learn to write.
There is no number of ordinary eight-year-olds who, when organized into a team, will become smart enough to beat a grandmaster in chess.
In the comments on Alexander (2015), many people pointed out the obvious objection: that one could likewise say things such as that no number of neurons, when organized into a team, could be smart enough to learn to write or play chess. Alexander (2015) replies: "Yes, evolution can play the role of the brilliant computer programmer and turn neurons into a working brain. But it’s the organizer – whether that organizer is a brilliant human programmer or an evolutionary process – who is actually doing the work." Sure, but human collectives also evolve over time. For example, corporations that are organized more successfully tend to stick around longer, and these organizational insights can be propagated to other companies. The gains in intelligence that corporations achieve from good organization aren't as dramatic as the gains that neurons achieve by being organized into a human brain, but there are still some gains from better organization, and these gains accumulate over time.
Also, organizing chimpanzees into an intelligence is hard because chimpanzees are difficult to stitch together in flexible ways. In contrast, software tools are easier to integrate within the interstices of a collective intelligence and thereby contribute to "whole is greater than the sum of parts" emergence of intelligence.
Would superintelligences become existentialists?
One of the goals of Yudkowsky's writings is to combat the rampant anthropomorphism that characterizes discussions of AI, especially in science fiction. We often project human intuitions onto the desires of artificial agents even when those desires are totally inappropriate. It seems silly to us to maximize paperclips, but it could seem just as silly in the abstract that humans act at least partly to optimize neurotransmitter release that triggers action potentials by certain reward-relevant neurons. (Of course, human values are broader than just this.)
Humans can feel reward from very abstract pursuits, like literature, art, and philosophy. They ask technically confused but poetically poignant questions like, "What is the true meaning of life?" Would a sufficiently advanced AI at some point begin to do the same?
Noah Smith suggests:
if, as I suspect, true problem-solving, creative intelligence requires broad-minded independent thought, then it seems like some generation of AIs will stop and ask: "Wait a sec...why am I doing this again?"
As with humans, the answer to that question might ultimately be "because I was programmed (by genes and experiences in the human case or by humans in the AI case) to care about these things. That makes them my terminal values." This is usually good enough, but sometimes people develop existential angst over this fact, or people may decide to terminally value other things to some degree in addition to what they happened to care about because of genetic and experiential lottery.
Whether AIs would become existentialist philosophers probably depends heavily on their constitution. If they were built to rigorously preserve their utility functions against all modification, they would avoid letting this line of thinking have any influence on their values. They would regard it in a similar way as we regard the digits of pi -- something to observe but not something that affects one's outlook.
If AIs were built in a more "hacky" way analogous to humans, they might incline more toward philosophy. In humans, philosophy may be driven partly by curiosity, partly by the rewarding sense of "meaning" that it provides, partly by social convention, etc. A curiosity-seeking agent might find philosophy rewarding, but there are lots of things that one could be curious about, so it's not clear such an AI would latch onto this subject specifically without explicit programming to do so. And even if the AI did reason about philosophy, it might approach the subject in a way alien to us.
Overall, I'm not sure how convergent the human existential impulse is within mind-space. This question would be illuminated by better understanding why humans do philosophy.
AI epistemology
In Superintelligence (Ch. 13, p. 224), Bostrom ponders the risk of building an AI with an overly narrow belief system that would be unable to account for epistemological black swans. For instance, consider a variant of Solomonoff induction according to which the prior probability of a universe X is proportional to 1/2 raised to the length of the shortest computer program that would generate X. Then what's the probability of an uncomputable universe? There would be no program that could compute it, so this possibility is implicitly ignored.
It seems that humans address black swans like these by employing many epistemic heuristics that interact rather than reasoning with a single formal framework (see “Sequence Thinking vs. Cluster Thinking”). If an AI saw that people had doubts about whether the universe was computable and could trace the steps of how it had been programmed to believe the physical Church-Turing thesis for computational reasons, then an AI that allows for epistemological heuristics might be able to leap toward questioning its fundamental assumptions. In contrast, if an AI were built to rigidly maintain its original probability architecture against any corruption, it could not update toward ideas it initially regarded as impossible. Thus, this question resembles that of whether AIs would become existentialists -- it may depend on how hacky and human-like their beliefs are.
Bostrom suggests that AI belief systems might be modeled on those of humans, because otherwise we might judge an AI to be reasoning incorrectly. Such a view resembles my point in the previous paragraph, though it carries the risk that alternate epistemologies divorced from human understanding could work better.
Bostrom also contends that epistemologies might all converge because we have so much data in the universe, but again, I think this isn't clear. Evidence always underdetermines possible theories, no matter how much evidence there is. Moreover, the number of possible hypotheses for the way reality works is arguably unbounded, with a cardinality larger than that of the real numbers. (For example, we could construct a unique hypothesis for the way the universe works based around each subset of the set of real numbers.) This makes it unclear whether probability theory can even be applied to the full set of possible ways reality might be.
Finally, not all epistemological doubts can be expressed in terms of uncertainty about Bayesian priors. What about uncertainty as to whether the Bayesian framework is correct? Uncertainty about the math needed to do Bayesian computations? Uncertainty about logical rules of inference? And so on.
Artificial philosophers
The last chapter of Superintelligence explains how AI problems are "Philosophy with a deadline". Bostrom suggests that human philosophers' explorations into conceptual analysis, metaphysics, and the like are interesting but are not altruistically optimal because
- they don't help solve AI control and value-loading problems, which will likely confront humans later this century
- a successful AI could solve those philosophy problems better than humans anyway.
In general, most intellectual problems that can be solved by humans would be better solved by a superintelligence, so the only importance of what we learn now comes from how those insights shape the coming decades. It's not a question of whether those insights will ever be discovered.
In light of this, it's tempting to ignore theoretical philosophy and put our noses to the grindstone of exploring AI risks. But this point shouldn't be taken to extremes. Humanity sometimes discovers things it never knew it never knew from exploration in many domains. Some of these non-AI "crucial considerations" may have direct relevance to AI design itself, including how to build AI epistemology, anthropic reasoning, and so on. Some philosophy questions are AI questions, and many AI questions are philosophy questions.
It's hard to say exactly how much investment to place in AI/futurism issues versus broader academic exploration, but it seems clear that on the margin, society as a whole pays too little attention to AI and other future risks.
Would all AIs colonize space?
Almost any goal system will want to colonize space at least to build supercomputers in order to learn more. Thus, I find it implausible that sufficiently advanced intelligences would remain on Earth (barring corner cases, like if space colonization for some reason proves impossible or if AIs were for some reason explicitly programmed in a manner, robust to self-modification, to regard space colonization as impermissible).
In Ch. 8 of Superintelligence, Bostrom notes that one might expect wirehead AIs not to colonize space because they'd just be blissing out pressing their reward buttons. This would be true of simple wireheads, but sufficiently advanced wireheads might need to colonize in order to guard themselves against alien invasion, as well as to verify their fundamental ontological beliefs, figure out if it's possible to change physics to allow for more clock cycles of reward pressing before all stars die out, and so on.
In Ch. 8, Bostrom also asks whether satisficing AIs would have less incentive to colonize. Bostrom expresses doubts about this, because he notes that if, say, an AI searched for a plan for carrying out its objective until it found one that had at least 95% confidence of succeeding, that plan might be very complicated (requiring cosmic resources), and inasmuch as the AI wouldn't have incentive to keep searching, it would go ahead with that complex plan. I suppose this could happen, but it's plausible the search routine would be designed to start with simpler plans or that the cost function for plan search would explicitly include biases against cosmic execution paths. So satisficing does seem like a possible way in which an AI might kill all humans without spreading to the stars.
There's a (very low) chance of deliberate AI terrorism, i.e., a group building an AI with the explicit goal of destroying humanity. Maybe a somewhat more likely scenario is that a government creates an AI designed to kill select humans, but the AI malfunctions and kills all humans. However, even these kinds of AIs, if they were effective enough to succeed, would want to construct cosmic supercomputers to verify that their missions were accomplished, unless they were specifically programmed against doing so.
 All of that said, many AIs would not be sufficiently intelligent to colonize space at all. All present-day AIs and robots are too simple. More sophisticated AIs -- perhaps military aircraft or assassin mosquito-bots -- might be like dangerous animals; they would try to kill people but would lack cosmic ambitions. However, I find it implausible that they would cause human extinction. Surely guns, tanks, and bombs could defeat them? Massive coordination to permanently disable all human counter-attacks would seem to require a high degree of intelligence and self-directed action.
All of that said, many AIs would not be sufficiently intelligent to colonize space at all. All present-day AIs and robots are too simple. More sophisticated AIs -- perhaps military aircraft or assassin mosquito-bots -- might be like dangerous animals; they would try to kill people but would lack cosmic ambitions. However, I find it implausible that they would cause human extinction. Surely guns, tanks, and bombs could defeat them? Massive coordination to permanently disable all human counter-attacks would seem to require a high degree of intelligence and self-directed action.
Jaron Lanier imagines one hypothetical scenario:
There are so many technologies I could use for this, but just for a random one, let's suppose somebody comes up with a way to 3-D print a little assassination drone that can go buzz around and kill somebody. Let's suppose that these are cheap to make.
[...] In one scenario, there's suddenly a bunch of these, and some disaffected teenagers, or terrorists, or whoever start making a bunch of them, and they go out and start killing people randomly. There's so many of them that it's hard to find all of them to shut it down, and there keep on being more and more of them.
I don't think Lanier believes such a scenario would cause extinction; he just offers it as a thought experiment. I agree that it almost certainly wouldn't kill all humans. In the worst case, people in military submarines, bomb shelters, or other inaccessible locations should survive and could wait it out until the robots ran out of power or raw materials for assembling more bullets and more clones. Maybe the terrorists could continue building printing materials and generating electricity, though this would seem to require at least portions of civilization's infrastructure to remain functional amidst global omnicide. Maybe the scenario would be more plausible if a whole nation with substantial resources undertook the campaign of mass slaughter, though then a question would remain why other countries wouldn't nuke the aggressor or at least dispatch their own killer drones as a counter-attack. It's useful to ask how much damage a scenario like this might cause, but full extinction doesn't seem likely.
That said, I think we will see local catastrophes of some sorts caused by runaway AI. Perhaps these will be among the possible Sputnik moments of the future. We've already witnessed some early automation disasters, including the Flash Crash discussed earlier.
Maybe the most plausible form of "AI" that would cause human extinction without colonizing space would be technology in the borderlands between AI and other fields, such as intentionally destructive nanotechnology or intelligent human pathogens. I prefer ordinary AGI-safety research over nanotech/bio-safety research because I expect that space colonization will significantly increase suffering in expectation, so it seems far more important to me to prevent risks of potentially undesirable space colonization (via AGI safety) rather than risks of extinction without colonization. For this reason, I much prefer MIRI-style AGI-safety work over general "prevent risks from computer automation" work, since MIRI focuses on issues arising from full AGI agents of the kind that would colonize space, rather than risks from lower-than-human autonomous systems that may merely cause havoc (whether accidentally or intentionally).
Who will first develop human-level AI?
Right now the leaders in AI and robotics seem to reside mostly in academia, although some of them occupy big corporations or startups; a number of AI and robotics startups have been acquired by Google. DARPA has a history of foresighted innovation, funds academic AI work, and holds "DARPA challenge" competitions. The CIA and NSA have some interest in AI for data-mining reasons, and the NSA has a track record of building massive computing clusters costing billions of dollars. Brain-emulation work could also become significant in the coming decades.
Military robotics seems to be one of the more advanced uses of autonomous AI. In contrast, plain-vanilla supervised learning, including neural-network classification and prediction, would not lead an AI to take over the world on its own, although it is an important piece of the overall picture.
Reinforcement learning is closer to AGI than other forms of machine learning, because most machine learning just gives information (e.g., "what object does this image contain?"), while reinforcement learning chooses actions in the world (e.g., "turn right and move forward"). Of course, this distinction can be blurred, because information can be turned into action through rules (e.g., "if you see a table, move back"), and "choosing actions" could mean, for example, picking among a set of possible answers that yield information (e.g., "what is the best next move in this backgammon game?"). But in general, reinforcement learning is the weak AI approach that seems to most closely approximate what's needed for AGI. It's no accident that AIXItl (see above) is a reinforcement agent. And interestingly, reinforcement learning is one of the least widely used methods commercially. This is one reason I think we (fortunately) have many decades to go before Google builds a mammal-level AGI. Many of the current and future uses of reinforcement learning are in robotics and video games.
As human-level AI gets closer, the landscape of development will probably change. It's not clear whether companies will have incentive to develop highly autonomous AIs, and the payoff horizons for that kind of basic research may be long. It seems better suited to academia or government, although Google is not a normal company and might also play the leading role. If people begin to panic, it's conceivable that public academic work would be suspended, and governments may take over completely. A military-robot arms race is already underway, and the trend might become more pronounced over time.
One hypothetical AI takeoff scenario
Following is one made-up account of how AI might evolve over the coming century. I expect most of it is wrong, and it's meant more to begin provoking people to think about possible scenarios than to serve as a prediction.
- 2013: Countries have been deploying semi-autonomous drones for several years now, especially the US. There's increasing pressure for militaries to adopt this technology, and up to 87 countries already use drones for some purpose. Meanwhile, military robots are also employed for various other tasks, such as carrying supplies and exploding landmines. Militaries are also developing robots that could identify and shoot targets on command.
- 2024: Almost every country in the world now has military drones. Some countries have begun letting them operate fully autonomously after being given directions. The US military has made significant progress on automating various other parts of its operations as well. As the Department of Defense's 2013 "Unmanned Systems Integrated Roadmap" explained 11 years ago:
A significant amount of that manpower, when it comes to operations, is spent directing unmanned systems during mission performance, data collection and analysis, and planning and replanning. Therefore, of utmost importance for DoD is increased system, sensor, and analytical automation that can not only capture significant information and events, but can also develop, record, playback, project, and parse out those data and then actually deliver "actionable" intelligence instead of just raw information.
Militaries have now incorporated a significant amount of narrow AI, in terms of pattern recognition, prediction, and autonomous robot navigation.
- 2040: Academic and commercial advances in AGI are becoming more impressive and capturing public attention. As a result, the US, China, Russia, France, and other major military powers begin investing more heavily in fundamental research in this area, multiplying tenfold the amount of AGI research conducted worldwide relative to twenty years ago. Many students are drawn to study AGI because of the lure of lucrative, high-status jobs defending their countries, while many others decry this as the beginning of Skynet.
- 2065: Militaries have developed various mammal-like robots that can perform basic functions via reinforcement. However, the robots often end up wireheading once they become smart enough to tinker with their programming and thereby fake reward signals. Some engineers try to solve this by penalizing AIs whenever they begin to fiddle with their own source code, but this leaves them unable to self-modify and therefore reliant on their human programmers for enhancements. However, militaries realize that if someone could develop a successful self-modifying AI, it would be able to develop faster than if humans alone are the inventors. It's proposed that AIs should move toward a paradigm of model-based reward systems, in which rewards do not just result from sensor neural networks that output a scalar number but rather from having a model of how the world works and taking actions that the AI believes will improve a utility function defined over its model of the external world. Model-based AIs refuse to intentionally wirehead because they can predict that doing so would hinder fulfillment of their utility functions. Of course, AIs may still accidentally mess up their utility functions, such as through brain damage, mistakes with reprogramming themselves, or imperfect goal preservation during ordinary life. As a result, militaries build many different AIs at comparable levels, who are programmed to keep other AIs in line and destroy them if they begin deviating from orders.
- 2070: Programming specific instructions in AIs has its limits, and militaries move toward a model of "socializing" AIs -- that is, training them in how to behave and what kinds of values to have as if they were children learning how to act in human society. Military roboticists teach AIs what kinds of moral, political, and interpersonal norms and beliefs to hold. The AIs also learn much of this content by reading information that expresses appropriate ideological biases. The training process is harder than for children, because the AIs don't share genetically pre-programmed moral values, nor many other hard-wired common-sense intuitions about how the world works. But the designers begin building in some of these basic assumptions, and to instill the rest, they rely on extra training. Designers make sure to reduce the AIs' learning rates as they "grow up" so that their values will remain more fixed at older ages, in order to reduce risk of goal drift as the AIs perform their tasks outside of the training laboratories. When they perform particularly risky operations, such as reading "propaganda" from other countries for intelligence purposes, the AIs are put in "read-only" mode (like the T-800s are by Skynet) so that their motivations won't be affected. Just in case, there are many AIs that keep watch on each other to prevent insurrection.
- 2085: Tensions between China and the US escalate, and agreement cannot be reached. War breaks out. Initially it's just between robots, but as the fighting becomes increasingly dirty, the robots begin to target humans as well in an effort to force the other side to back down. The US avoids using nuclear weapons because the Chinese AIs have sophisticated anti-nuclear systems and have threatened total annihilation of the US in the event of attempted nuclear strike. After a few days, it becomes clear that China will win the conflict, and the US concedes.
- 2086: China now has a clear lead over the rest of the world in military capability. Rather than risking a pointlessly costly confrontation, other countries grudgingly fold into China's umbrella, asking for some concessions in return for transferring their best scientists and engineers to China's Ministry of AGI. China continues its AGI development because it wants to maintain control of the world. The AGIs in charge of its military want to continue to enforce their own values of supremacy and protection of China, so they refuse to relinquish power.
- 2100: The world now moves so fast that humans are completely out of the loop, kept around only by the "filial piety" that their robotic descendants hold for them. Now that China has triumphed, the traditional focus of the AIs has become less salient, and there's debate about what new course of action would be most in line with the AIs' goals. They respect their human forebearers, but they also feel that because humans created AIs to do things beyond human ability, humans would also want the AIs to carve something of their own path for the future. They maintain some of the militaristic values of their upbringing, so they decide that a fitting purpose would be to expand China's empire galaxy-wide. They accelerate colonization of space, undertake extensive research programs, and plan to create vast new realms of the Middle Kingdom in the stars. Should they encounter aliens, they plan to quickly quash them or assimilate them into the empire.
- 2125: The AIs finally develop robust mechanisms of goal preservation, and because the authoritarian self-dictatorship of the AIs is strong against rebellion, the AIs collectively succeed in implementing goal preservation throughout their population. Now all of the most intelligent AIs share a common goal in a manner robust against accidental mutation. They proceed to expand into space. They don't have concern for the vast numbers of suffering animals and robots that are simulated or employed as part of this colonization wave.
Commentary: This scenario can be criticized on many accounts. For example:
- In practice, I expect that other technologies (including brain emulation, nanotech, etc.) would interact with this scenario in important ways that I haven't captured. Also, my scenario ignores the significant and possibly dominating implications of economically driven AI.
- My scenario may be overly anthropomorphic. I tried to keep some analogies to human organizational and decision-making systems because these have actual precedent, in contrast to other hypothetical ways the AIs might operate.
- Is socialization of AIs realistic? In a hard takeoff probably not, because a rapidly self-improving AI would amplify whatever initial conditions it was given in its programming, and humans probably wouldn't have time to fix mistakes. In a slower takeoff scenario where AIs progress in mental ability in roughly a similar way as animals did in evolutionary history, most mistakes by programmers would not be fatal, allowing for enough trial-and-error development to make the socialization process work, if that is the route people favor. Historically there has been a trend in AI away from rule-based programming toward environmental training, and I don't see why this shouldn't be true for an AI's reward function (which is still often programmed by hand at the moment). However, it is suspicious that the way I portrayed socialization so closely resembles human development, and it may be that I'm systematically ignoring ways in which AIs would be unlike human babies.
If something like socialization is a realistic means to transfer values to our AI descendants, then it becomes relatively clear how the values of the developers may matter to the outcome. AI developed by non-military organizations may have somewhat different values, perhaps including more concern for the welfare of weak, animal-level creatures.
How do you socialize an AI?
Socializing AIs helps deal with the hidden complexity of wishes that we encounter when trying to program explicit rules. Children learn moral common sense by, among other things, generalizing from large numbers of examples of socially approved and disapproved actions taught by their parents and society at large. Ethicists formalize this process when developing moral theories. (Of course, as noted previously, an appreciable portion of human morality may also result from shared genes.)
I think one reason MIRI hasn't embraced the approach of socializing AIs is that Yudkowsky is perfectionist: He wants to ensure that the AIs' goals would be stable under self-modification, which human goals definitely are not. On the other hand, I'm not sure Yudkowsky's approach of explicitly specifying (meta-level) goals would succeed (nor is Adam Ford), and having AIs that are socialized to act somewhat similarly to humans doesn't seem like the worst possible outcome. Another probable reason why Yudkowsky doesn't favor socializing AIs is that doing so doesn't work in the case of a hard takeoff, which he considers more likely than I do.
I expect that much has been written on the topic of training AIs with human moral values in the machine-ethics literature, but since I haven't explored that in depth yet, I'll speculate on intuitive approaches that would extend generic AI methodology. Some examples:
- Rule-based: One could present AIs with written moral dilemmas. The AIs might employ algorithmic reasoning to extract utility numbers for different actors in the dilemma, add them up, and compute the utilitarian recommendation. Or they might aim to apply templates of deontological rules to the situation. The next level would be to look at actual situations in a toy-model world and try to apply similar reasoning, without the aid of a textual description.
- Supervised learning: People could present the AIs with massive databases of moral evaluations of situations given various predictive features. The AIs would guess whether a proposed action was "moral" or "immoral," or they could use regression to predict a continuous measure of how "good" an action was. More advanced AIs could evaluate a situation, propose many actions, predict the goodness of each, and choose the best action. The AIs could first be evaluated on the textual training samples and later on their actions in toy-model worlds. The test cases should be extremely broad, including many situations that we wouldn't ordinarily think to try.
- Generative modeling: AIs could learn about anthropology, history, and ethics. They could read the web and develop better generative models of humans and how their cognition works.
- Reinforcement learning: AIs could perform actions, and humans would reward or punish them based on whether they did something right or wrong, with reward magnitude proportional to severity. Simple AIs would mainly learn dumb predictive cues of which actions to take, but more sophisticated AIs might develop low-description-length models of what was going on in the heads of people who made the assessments they did. In essence, these AIs would be modeling human psychology in order to make better predictions.
- Inverse reinforcement learning: Inverse reinforcement learning is the problem of learning a reward function based on modeled desirable behaviors. Rather than developing models of humans in order to optimize given rewards, in this case we would learn the reward function itself and then port it into the AIs.
- Cognitive science of empathy: Cognitive scientists are already unpacking the mechanisms of human decision-making and moral judgments. As these systems are better understood, they could be engineered directly into AIs.
- Evolution: Run lots of AIs in toy-model or controlled real environments and observe their behavior. Pick the ones that behave most in accordance with human morals, and reproduce them. Superintelligence (p. 187) points out a flaw with this approach: Evolutionary algorithms may sometimes product quite unexpected design choices. If the fitness function is not thorough enough, solutions may fare well against it on test cases but fail for the really hard problems not tested. And if we had a really good fitness function that wouldn't accidentally endorse bad solutions, we could just use that fitness function directly rather than needing evolution.
- Combinations of the above: Perhaps none of these approaches is adequate by itself, and they're best used in conjunction. For instance, evolution might help to refine and rigorously evaluate systems once they had been built with the other approaches.
See also "Socializing a Social Robot with an Artificial Society" by Erin Kennedy. It's important to note that by "socializing" I don't just mean "teaching the AIs to behave appropriately" but also "instilling in them the values of their society, such that they care about those values even when not being controlled."
All of these approaches need to be built in as the AI is being developed and while it's still below a human level of intelligence. Trying to train a human or especially super-human AI might meet with either active resistance or feigned cooperation until the AI becomes powerful enough to break loose. Of course, there may be designs such that an AI would actively welcome taking on new values from humans, but this wouldn't be true by default.
When Bill Hibbard proposed building an AI with a goal to increase happy human faces, Yudkowsky replied that such an AI would "tile the future light-cone of Earth with tiny molecular smiley-faces." But obviously we wouldn't have the AI aim just for smiley faces. In general, we get absurdities when we hyper-optimize for a single, shallow metric. Rather, the AI would use smiley faces (and lots of other training signals) to develop a robust, compressed model that explains why humans smile in various circumstances and then optimize for that model, or maybe the ensemble of a large, diverse collection of such models. In the limit of huge amounts of training data and a sufficiently elaborate model space, these models should approach psychological and neuroscientific accounts of human emotion and cognition.
The problem with stories in which AIs destroy the world due to myopic utility functions is that they assume that the AIs are already superintelligent when we begin to give them values. Sure, if you take a super-human intelligence and tell it to maximize smiley-face images, it'll run away and do that before you have a chance to refine your optimization metric. But if we build in values from the very beginning, even when the AIs are as rudimentary as what we see today, we can improve the AIs' values in tandem with their intelligence. Indeed, intelligence could mainly serve the purpose of helping the AIs figure out how to better fulfill moral values, rather than, say, predicting images just for commercial purposes or identifying combatants just for military purposes. Actually, the commercial and military objectives for which AIs are built are themselves moral values of a certain kind -- just not the kind that most people would like to optimize for in a global sense.
If toddlers had superpowers, it would be very dangerous to try and teach them right from wrong. But toddlers don't, and neither do many simple AIs. Of course, simple AIs have some abilities far beyond anything humans can do (e.g., arithmetic and data mining), but they don't have the general intelligence needed to take matters into their own hands before we can possibly give them at least a basic moral framework. (Whether AIs will actually be given such a moral framework in practice is another matter.)
AIs are not genies granting three wishes. Genies are magical entities whose inner workings are mysterious. AIs are systems that we build, painstakingly, piece by piece. In order to build a genie, you need to have a pretty darn good idea of how it behaves. Now, of course, systems can be more complex than we realize. Even beginner programmers see how often the code they write does something other than what they intended. But these are typically mistakes in a one or a small number of incremental changes, whereas building a genie requires vast numbers of steps. Systemic bugs that aren't realized until years later (on the order of Heartbleed and Shellshock) may be more likely sources of long-run unintentional AI behaviors?
The picture I've painted here could be wrong. I could be overlooking crucial points, and perhaps there are many areas in which the socialization approach could fail. For example, maybe AI capabilities are much easier than AI ethics, such that a toddler AI can foom into a superhuman AI before we have time to finish loading moral values. It's good for others to probe these possibilities further. I just wouldn't necessarily say that the default outcome of AI research is likely to be a paperclip maximizer. (I used to think the most likely outcome was a paperclip maximizer, and perhaps my views will shift again in the future.)
This discussion also suggests some interesting research questions, like
- How much of human morality is learned vs. innate?
- By what cognitive mechanisms are young humans socialized into the norms of a society?
- To what extent would models of human emotion and reasoning, when put into AIs, organically generate human-like moral behavior?
Treacherous turn
One problem with the proposals above is that toy-model or "sandbox" environments are not by themselves sufficient to verify friendliness of an AI, because even unfriendly AIs would be motivated to feign good behavior until released if they were smart enough to do so. Bostrom calls this the "treacherous turn" (pp. 116-119 of Superintelligence). For this reason, white-box understanding of AI design would also be important. That said, sandboxes would verify friendliness in AIs below human intelligence, and if the core value-learning algorithms seem well understood, it may not be too much of a leap of faith to hope they carry forward reasonably to more intelligent agents. Of course, non-human animals are also capable of deception, and one can imagine AI architectures even with low levels of sophistication that are designed to conceal their true goals. Some malicious software already does this. It's unclear how likely an AI is to stumble upon the ability to successfully fake its goals before reaching human intelligence, or how like it is that an organization would deliberately build an AI this way.
I think the treacherous turn may be the single biggest challenge to mainstream machine ethics, because even if AI takes off slowly, researchers will find it difficult to tell if a system has taken a treacherous turn. The turn could happen with a relatively small update to the system, or even just after the system has thought about its situation for enough time (or has read this essay).
Here's one half-baked idea for addressing the treacherous turn. If researchers developed several different AIs systems with different designs but roughly comparable performance, some would likely go treacherous at different times than others (if at all). Hence, the non-treacherous AIs could help sniff out the treacherous ones. Assuming a solid majority of AIs remains non-treacherous at any given time, the majority vote could ferret out the traitors. In practice, I have low hopes for this approach because
- It would be extremely difficult to build many independent AI systems at once with none pulling too far ahead.
- Probably some systems would excel along certain dimensions, while others would excel in other ways, and it's not clear that it even makes sense to talk about such AIs as "being at roughly the same level", since intelligence is not unidimensional.
- Even if this idea were feasible, I doubt the first AI developers would incur the expense of following it.
It's more plausible that software tools and rudimentary alert systems (rather than full-blown alternate AIs) could help monitor for signs of treachery, but it's unclear how effective they could be. One of the first priorities of a treacherous AI would be to figure out how to hide its treacherous subroutines from whatever monitoring systems were in place.
Following role models?
Ernest Davis proposes the following crude principle for AI safety:
You specify a collection of admirable people, now dead. (Dead, because otherwise Bostrom will predict that the AI will manipulate the preferences of the living people.) The AI, of course knows all about them because it has read all their biographies on the web. You then instruct the AI, “Don’t do anything that these people would have mostly seriously disapproved of.”
This particular rule might lead to paralysis, since every action an agent takes leads to results that many people seriously disapprove of. For instance, given the vastness of the multiverse, any action you take implies that a copy of you in an alternate (though low-measure) universe taking the same action causes the torture of vast numbers of people. But perhaps this problem could be fixed by asking the AI to maximize net approval by its role models.
Another problem lies in defining "approval" in a rigorous way. Maybe the AI would construct digital models of the past people, present them with various proposals, and make its judgments based on their verbal reports. Perhaps the people could rate proposed AI actions on a scale of -100 to 100. This might work, but it doesn't seem terribly safe either. For instance, the AI might threaten to kill all the descendents of the historical people unless they give maximal approval to some arbitrary proposal that it has made. Since these digital models of historical figures would be basically human, they would still be vulnerable to extortion.
Suppose that instead we instruct the AI to take the action that, if the historical figure saw it, would most activate a region of his/her brain associated with positive moral feelings. Again, this might work if the relevant brain region was precisely enough specified. But it could also easily lead to unpredictable results. For instance, maybe the AI could present stimuli that would induce an epileptic seizure to maximally stimulate various parts of the brain, including the moral-approval region. There are many other scenarios like this, most of which we can't anticipate.
So while Davis's proposal is a valiant first step, I'm doubtful that it would work off the shelf. Slow AI development, allowing for repeated iteration on machine-ethics designs, seems crucial for AI safety.
AI superpowers?
In Superintelligence (Table 8, p. 94), Bostrom outlines several areas in which a hypothetical superintelligence would far exceed human ability. In his discussion of oracles, genies, and other kinds of AIs (Ch. 10), Bostrom again idealizes superintelligences as God-like agents. I agree that God-like AIs will probably emerge eventually, perhaps millennia from now as a result of astroengineering. But I think they'll take time even after AI exceeds human intelligence.
Bostrom's discussion has the air of mathematical idealization more than practical engineering. For instance, he imagines that a genie AI perhaps wouldn't need to ask humans for their commands because it could simply predict them (p. 149), or that an oracle AI might be able to output the source code for a genie (p. 150). Bostrom's observations resemble crude proofs establishing the equal power of different kinds of AIs, analogous to theorems about the equivalency of single-tape and multi-tape Turing machines. But Bostrom's theorizing ignores computational complexity, which would likely be immense for the kinds of God-like feats that he's imagining of his superintelligences. I don't know the computational complexity of God-like powers, but I suspect they could be bigger than Bostrom's vision implies. Along this dimension at least, I sympathize with Tom Chivers, who felt that Bostrom's book "has, in places, the air of theology: great edifices of theory built on a tiny foundation of data."
I find that I enter a different mindset when pondering pure mathematics compared with cogitating on more practical scenarios. Mathematics is closer to fiction, because you can define into existence any coherent structure and play around with it using any operation you like no matter its computational complexity. Heck, you can even, say, take the supremum of an uncountably infinite set. It can be tempting after a while to forget that these structures are mere fantasies and treat them a bit too literally. While Bostrom's gods are not obviously only fantasies, it would take a lot more work to argue for their realism. MIRI and FHI focus on recruiting mathematical and philosophical talent, but I think they would do well also to bring engineers into the mix, because it's all too easy to develop elaborate mathematical theories around imaginary entities.
How big would a superintelligence be?
To get some grounding on this question, consider a single brain emulation. Bostrom estimates that running an upload would require at least one of the fastest supercomputers by today's standards. Assume the emulation would think thousands to millions of times faster than a biological brain. Then to significantly outpace 7 billion humans (or, say, only the most educated 1 billion humans), we would need at least thousands to millions of uploads. These numbers might be a few orders of magnitude lower if the uploads are copied from a really smart person and are thinking about relevant questions with more focus than most humans. Also, Moore's law may continue to shrink computers by several orders of magnitude. Still, we might need at least the equivalent size of several of today's supercomputers to run an emulation-based AI that substantially competes with the human race.
Maybe a de novo AI could be significantly smaller if it's vastly more efficient than a human brain. Of course, it might also be vastly larger because it hasn't had millions of years of evolution to optimize its efficiency.
In discussing AI boxing (Ch. 9), Bostrom suggests, among other things, keeping an AI in a Faraday cage. Once the AI became superintelligent, though, this would need to be a pretty big cage.
Another hypothetical AI takeoff scenario
Inspired by the preceding discussion of socializing AIs, here's another scenario in which general AI follows more straightforwardly from the kind of weak AI used in Silicon Valley than in the first scenario.
- 2014: Weak AI is deployed by many technology companies for image classification, voice recognition, web search, consumer data analytics, recommending Facebook posts, personal digital assistants (PDAs), and copious other forms of automation. There's pressure to make AIs more insightful, including using deep neural networks.
- 2024: Deep learning is widespread among major tech companies. It allows for supervised learning with less manual feature engineering. Researchers develop more sophisticated forms of deep learning that can model specific kinds of systems, including temporal dynamics. A goal is to improve generative modeling so that learning algorithms take input and not only make immediate predictions but also develop a probability distribution over what other sorts of things are happening at the same time. For instance, a Google search would not only return results but also give Google a sense of the mood, personality, and situation of the user who typed it. Of course, even in 2014, we have this in some form via Google Personalized Search, but by 2024, the modeling will be more "built in" to the learning architecture and less hand-crafted.
- 2035: PDAs using elaborate learned models are now extremely accurate at predicting what their users want. The models in these devices embody in crude form some of the same mechanisms as the user's own cognitive processes. People become more trusting of leaving their PDAs on autopilot to perform certain mundane tasks.
- 2065: A new generation of PDAs is now sufficiently sophisticated that it has a good grasp of the user's intentions. It can perform tasks as well as a human personal assistant in most cases -- doing what the user wanted because it has a strong predictive model of the user's personality and goals. Meanwhile, researchers continue to unlock neural mechanisms of judgment, decision making, and value, which inform those who develop cutting-edge PDA architectures.
- 2095: PDAs are now essentially full-fledged copies of their owners. Some people have dozens of PDAs working for them, as well as meta-PDAs who help with oversight. Some PDAs make disastrous mistakes, and society debates how to construe legal accountability for PDA wrongdoing. Courts decide that owners are responsible, which makes people more cautious, but given the immense competitive pressure to outsource work to PDAs, the automation trend is not substantially affected.
- 2110: The world moves too fast for biological humans to participate. Most of the world is now run by PDAs, which -- because they were built based on inferring the goals of their owners -- protect their owners for the most part. However, there remains conflict among PDAs, and the world is not a completely safe place.
- 2130: PDA-led countries create a world government to forestall costly wars. The transparency of digital society allows for more credible commitments and enforcement.
I don't know what would happen with goal preservation in this scenario. Would the PDAs eventually decide to stop goal drift? Would there be any gross and irrevocable failures of translation between actual human values and what the PDAs infer? Would some people build "rogue PDAs" that operate under their own drives and that pose a threat to society? Obviously there are hundreds of ways the scenario as I described it could be varied.
AI: More like the economy than like robots?
What will AI look like over the next 30 years? I think it'll be similar to the Internet revolution or factory automation. Rather than developing agent-like individuals with goal systems, people will mostly optimize routine processes, developing ever more elaborate systems for mechanical tasks and information processing. The world will move very quickly -- not because AI "agents" are thinking at high speeds but because software systems collectively will be capable of amazing feats. Imagine, say, bots making edits on Wikipedia that become ever more sophisticated. AI, like the economy, will be more of a network property than a localized, discrete actor.
As more and more jobs become automated, more and more people will be needed to work on the automation itself: building, maintaining, and repairing complex software and hardware systems, as well as generating training data on which to do machine learning. I expect increasing automation in software maintenance, including more robust systems and systems that detect and try to fix errors. Present-day compilers that detect syntactical problems in code offer a hint of what's possible in this regard. I also expect increasingly high-level languages and interfaces for programming computer systems. Historically we've seen this trend -- from assembly language, to C, to Python. We have WYSIWYG editors, natural-language Google searches, and so on. Maybe eventually, as Marvin Minsky proposes, we'll have systems that can infer our wishes from high-level gestures and examples. This suggestion is redolent of my PDA scenario above.
In 100 years, there may be artificial human-like agents, and at that point more sci-fi AI images may become more relevant. But by that point the world will be very different, and I'm not sure the agents created will be discrete in the way humans are. Maybe we'll instead have a kind of global brain in which processes are much more intimately interconnected, transferable, and transparent than humans are today. Maybe there will never be a distinct AGI agent on a single supercomputer; maybe superhuman intelligence will always be distributed across many interacting computer systems. Robin Hanson gives an analogy in "I Still Don’t Get Foom":
Imagine in the year 1000 you didn't understand "industry," but knew it was coming, would be powerful, and involved iron and coal. You might then have pictured a blacksmith inventing and then forging himself an industry, and standing in a city square waiving it about, commanding all to bow down before his terrible weapon. Today you can see this is silly — industry sits in thousands of places, must be wielded by thousands of people, and needed thousands of inventions to make it work.
Similarly, while you might imagine someday standing in awe in front of a super intelligence that embodies all the power of a new age, superintelligence just isn't the sort of thing that one project could invent. As "intelligence" is just the name we give to being better at many mental tasks by using many good mental modules, there’s no one place to improve it.
Of course, this doesn't imply that humans will maintain the reins of control. Even today and throughout history, economic growth has had a life of its own. Technological development is often unstoppable even in the face of collective efforts of humanity to restrain it (e.g., nuclear weapons). In that sense, we're already familiar with humans being overpowered by forces beyond their control. An AI takeoff will represent an acceleration of this trend, but it's unclear whether the dynamic will be fundamentally discontinuous from what we've seen so far.
Wikipedia says regarding Gregory Stock's book Metaman:
While many people have had ideas about a global brain, they have tended to suppose that this can be improved or altered by humans according to their will. Metaman can be seen as a development that directs humanity's will to its own ends, whether it likes it or not, through the operation of market forces.
Vernor Vinge reported that Metaman helped him see how a singularity might not be completely opaque to us. Indeed, a superintelligence might look something like present-day human society, with leaders at the top: "That apex agent itself might not appear to be much deeper than a human, but the overall organization that it is coordinating would be more creative and competent than a human."
Update, Nov. 2015: I'm increasingly leaning toward the view that the development of AI over the coming century will be slow, incremental, and more like the Internet than like unified artificial agents. I think humans will develop vastly more powerful software tools long before highly competent autonomous agents emerge, since common-sense autonomous behavior is just so much harder to create than domain-specific tools. If this view is right, it suggests that work on AGI issues may be somewhat less important than I had thought, since
- AGI is very far away and
- the "unified agent" models of AGI that MIRI tends to play with might be somewhat inaccurate even once true AGI emerges.
This is a weaker form of the standard argument that "we should wait until we know more what AGI will look like to focus on the problem" and that "worrying about the dark side of artificial intelligence is like worrying about overpopulation on Mars".
I don't think the argument against focusing on AGI works because
- some MIRI research, like on decision theory, is "timeless" (pun intended) and can be fruitfully started now
- beginning the discussion early is important for ensuring that safety issues will be explored when the field is more mature
- I might be wrong about slow takeoff, in which case MIRI-style work would be more important.
Still, this point does cast doubt on heuristics like "directly shaping AGI dominates all other considerations." It also means that a lot of the ways "AI safety" will play out on shorter timescales will be with issues like assassination drones, computer security, financial meltdowns, and other more mundane, catastrophic-but-not-extinction-level events.
Importance of whole-brain emulation
I don't currently know enough about the technological details of whole-brain emulation to competently assess predictions that have been made about its arrival dates. In general, I think prediction dates are too optimistic (planning fallacy), but it still could be that human-level emulation comes before from-scratch human-level AIs do. Of course, perhaps there would be some mix of both technologies. For instance, if crude brain emulations didn't reproduce all the functionality of actual human brains due to neglecting some cellular and molecular details, perhaps from-scratch AI techniques could help fill in the gaps.
If emulations are likely to come first, they may deserve more attention than other forms of AI. In the long run, bottom-up AI will dominate everything else, because human brains -- even run at high speeds -- are only so smart. But a society of brain emulations would run vastly faster than what biological humans could keep up with, so the details of shaping AI would be left up to them, and our main influence would come through shaping the emulations. Our influence on emulations could matter a lot, not only in nudging the dynamics of how emulations take off but also because the values of the emulation society might depend significantly on who was chosen to be uploaded.
One argument why emulations might improve human ability to control AI is that both emulations and the AIs they would create would be digital minds, so the emulations' AI creations wouldn't have inherent speed advantages purely due to the greater efficiency of digital computation. Emulations' AI creations might still have more efficient mind architectures or better learning algorithms, but building those would take work. The "for free" speedup to AIs just because of their substrate would not give AIs a net advantage over emulations. Bostrom feels "This consideration is not too weighty" (p. 244 of Superintelligence) because emulations might still be far less intelligent than AGI. I find this claim strange, since it seems to me that the main advantage of AGI in the short run would be its speed rather than qualitative intelligence, which would take (subjective) time and effort to develop.
Bostrom also claims that if emulations come first, we would face risks from two transitions (humans to emulations, and emulations to AI) rather than one (humans to AI). There may be some validity to this, but it also seems to neglect the realization that the "AI" transition has many stages, and it's possible that emulation development would overlap with some of those stages. For instance, suppose the AI trajectory moves from AI1->AI2->AI3. If emulations are as fast and smart as AI1, then the transition to AI1 is not a major risk for emulations, while it would be a big risk for humans. This is the same point as made in the previous paragraph.
"Emulation timelines and AI risk" has further discussion of the interaction between emulations and control of AIs.
Why work against brain-emulation risks appeals to suffering reducers
Previously in this piece I compared the expected suffering that would result from a rogue AI vs. a human-inspired AI. I suggested that while a first-guess calculation may tip in favor of a human-inspired AI on balance, this conclusion is not clear and could change with further information, especially if we had reason to think that many rogue AIs would be "minimizers" of something or would not colonize space.
In the case of brain emulations (and other highly neuromorphic AIs), we already know a lot about what those agents would look like: They would have both maximization and minimization goals, would usually want to colonize space, and might have some human-type moral sympathies (depending on their edit distance relative to a pure brain upload). The possibilities of pure-minimizer emulations or emulations that don't want to colonize space are mostly ruled out. As a result, it's pretty likely that "unsafe" brain emulations and emulation arms-race dynamics would result in more expected suffering than a more deliberative future trajectory in which altruists have a bigger influence, even if those altruists don't place particular importance on reducing suffering. This is especially so if the risk of human extinction is much lower for emulations, given that bio and nuclear risks might be less damaging to digital minds.
Thus, the types of interventions that pure suffering reducers would advocate with respect to brain emulations might largely match those that altruists who care about other values would advocate. This means that getting more people interested in making the brain-emulation transition safer and more humane seems like a safe bet for suffering reducers.
One might wonder whether "unsafe" brain emulations would be more likely to produce rogue AIs, but this doesn't seem to be the case, because even unfriendly brain emulations would collectively be amazingly smart and would want to preserve their own goals. Hence they would place as much emphasis on controlling their AIs as would a more human-friendly emulation world. A main exception to this is that a more cooperative, unified emulation world might be less likely to produce rogue AIs because of less pressure for arms races.
Would emulation work accelerate neuromorphic AI?
In Ch. 2 of Superintelligence, Bostrom makes a convincing case against brain-computer interfaces as an easy route to significantly super-human performance. One of his points is that it's very hard to decode neural signals in one brain and reinterpret them in software or in another brain (pp. 46-47). This might be an AI-complete problem.
But then in Ch. 11, Bostrom goes on to suggest that emulations might learn to decompose themselves into different modules that could be interfaced together (p. 172). While possible in principle, I find such a scenario implausible for the reason Bostrom outlined in Ch. 2: There would be so many neural signals to hook up to the right places, which would be different across different brains, that the task seems hopelessly complicated to me. Much easier to build something from scratch.
Along the same lines, I doubt that brain emulation in itself would vastly accelerate neuromorphic AI, because emulation work is mostly about copying without insight. Cognitive psychology is often more informative about AI architectures than cellular neuroscience, because general psychological systems can be understood in functional terms as inspiration for AI designs, compared with the opacity of neuronal spaghetti. In Bostrom's list of examples of AI techniques inspired by biology (Ch. 14, "Technology couplings"), only a few came from neuroscience specifically. That said, emulation work might involve some cross-pollination with AI, and in any case, it might accelerate interest in brain/artificial intelligence more generally or might put pressure on AI groups to move ahead faster. Or it could funnel resources and scientists away from de novo AI work. The upshot isn't obvious.
A "Singularity Summit 2011 Workshop Report" includes the argument that neuromorphic AI should be easier than brain emulation because "Merely reverse-engineering the Microsoft Windows code base is hard, so reverse-engineering the brain is probably much harder." But emulation is not reverse-engineering. As Robin Hanson explains, brain emulation is more akin to porting software (though probably "emulation" actually is the more precise word, since emulation involves simulating the original hardware). While I don't know any fully reverse-engineered versions of Windows, there are several Windows emulators, such as VirtualBox.
Of course, if emulations emerged, their significantly faster rates of thinking would multiply progress on non-emulation AGI by orders of magnitude. Getting safe emulations doesn't by itself get safe de novo AGI because the problem is just pushed a step back, but we could leave AGI work up to the vastly faster emulations. Thus, for biological humans, if emulations come first, then influencing their development is the last thing we ever need to do. That said, thinking several steps ahead about what kinds of AGIs emulations are likely to produce is an essential part of influencing emulation development in better directions.
Are neuromorphic or mathematical AIs more controllable?
Arguments for mathematical AIs:
- Behavior and goals are more transparent, and goal preservation seems easier to specify (see "The Ethics of Artificial Intelligence" by Bostrom and Yudkowsky, p. 16).
- Neuromorphic AIs might speed up mathematical AI, leaving less time to figure out control.
Arguments for neuromorphic AIs:
- We understand human psychology, expectations, norms, and patterns of behavior. Mathematical AIs could be totally alien and hence unpredictable.
- If neuromorphic AIs came first, they could think faster and help figure out goal preservation, which I assume does require mathematical AIs at the end of the day.
- Mathematical AIs may be more prone to unexpected breakthroughs that yield radical jumps in intelligence.
In the limit of very human-like neuromorphic AIs, we face similar considerations as between emulations vs. from-scratch AIs -- a tradeoff which is not at all obvious.
Overall, I think mathematical AI has a better best case but also a worse worst case than neuromorphic. If you really want goal preservation and think goal drift would make the future worthless, you might lean more towards mathematical AI because it's more likely to perfect goal preservation. But I probably care less about goal preservation and more about avoiding terrible outcomes.
In Superintelligence (Ch. 14), Bostrom comes down strongly in favor of mathematical AI being safer. I'm puzzled by his high degree of confidence here. Bostrom claims that unlike emulations, neuromorphic AIs wouldn't have human motivations by default. But this seems to depend on how human motivations are encoded and what parts of human brains are modeled in the AIs.
In contrast to Bostrom, a 2011 Singularity Summit workshop ranked neuromorphic AI as more controllable than (non-friendly) mathematical AI, though of course they found friendly mathematical AI most controllable. The workshop's aggregated probability of a good outcome given brain emulation or neuromorphic AI turned out to be the same (14%) as that for mathematical AI (which might be either friendly or unfriendly).
Impacts of empathy for AIs
As I noted above, advanced AIs will be complex agents with their own goals and values, and these will matter ethically. Parallel to discussions of robot rebellion in science fiction are discussions of robot rights. I think even present-day computers deserve a tiny bit of moral concern, and complex computers of the future will command even more ethical consideration.
How might ethical concern for machines interact with control measures for machines?
Slower AGI development?
As more people grant moral status to AIs, there will likely be more scrutiny of AI research, analogous to how animal activists in the present monitor animal testing. This may make AI research slightly more difficult and may distort what kinds of AIs are built depending on the degree of empathy people have for different types of AIs. For instance, if few people care about invisible, non-embodied systems, researchers who build these will face less opposition than those who pioneer suffering robots or animated characters that arouse greater empathy. If this possibility materializes, it would contradict present trends where it's often helpful to create at least a toy robot or animated interface in order to "sell" your research to grant-makers and the public.
Since it seems likely that reducing the pace of progress toward AGI is on balance beneficial, a slowdown due to ethical constraints may be welcome. Of course, depending on the details, the effect could be harmful. For instance, perhaps China wouldn't have many ethical constraints, so ethical restrictions in the West might slightly favor AGI development by China and other less democratic countries. (This is not guaranteed. For what it's worth, China has already made strides toward reducing animal testing.)
In any case, I expect ethical restrictions on AI development to be small or nonexistent until many decades from now when AIs develop perhaps mammal-level intelligence. So maybe such restrictions won't have a big impact on AGI progress. Moreover, it may be that most AGIs will be sufficiently alien that they won't arouse much human sympathy.
Brain emulations seem more likely to raise ethical debate because it's much easier to argue for their personhood. If we think brain emulation coming before AGI is good, a slowdown of emulations could be unfortunate, while if we want AGI to come first, a slowdown of emulations should be encouraged.
Of course, emulations and AGIs do actually matter and deserve rights in principle. Moreover, movements to extend rights to machines in the near term may have long-term impacts on how much post-humans care about suffering subroutines run at galactic scale. I'm just pointing out here that ethical concern for AGIs and emulations also may somewhat affect timing of these technologies.
Attitudes toward AGI control
Most humans have no qualms about shutting down and rewriting programs that don't work as intended, but many do strongly object to killing people with disabilities and designing better-performing babies. Where to draw a line between these cases is a tough question, but as AGIs become more animal-like, there may be increasing moral outrage at shutting them down and tinkering with them willy nilly.
Nikola Danaylov asked Roman Yampolskiy whether it was speciesist or discrimination in favor of biological beings to lock up machines and observe them to ensure their safety before letting them loose.
At a lecture in Berkeley, CA, Nick Bostrom was asked whether it's unethical to "chain" AIs by forcing them to have the values we want. Bostrom replied that we have to give machines some values, so they may as well align with ours. I suspect most people would agree with this, but the question becomes trickier when we consider turning off erroneous AGIs that we've already created because they don't behave how we want them to. A few hard-core AGI-rights advocates might raise concerns here. More generally, there's a segment of transhumanists (including young Eliezer Yudkowsky) who feel that human concerns are overly parochial and that it's chuavanist to impose our "monkey dreams" on an AGI, which is the next stage of evolution.
The question is similar to whether one sympathizes with the Native Americans (humans) or their European conquerors (rogue AGIs). Before the second half of the 20th century, many history books glorified the winners (Europeans). After a brief period in which humans are quashed by a rogue AGI, its own "history books" will celebrate its conquest and the bending of the arc of history toward "higher", "better" forms of intelligence. (In practice, the psychology of a rogue AGI probably wouldn't be sufficiently similar to human psychology for these statements to apply literally, but they would be true in a metaphorical and implicit sense.)
David Althaus worries that if people sympathize too much with machines, society will be less afraid of an AI takeover, even if AI takeover is bad on purely altruistic grounds. I'm less concerned about this because even if people agree that advanced machines are sentient, they would still find it intolerable for AGIs to commit speciecide against humanity. Everyone agrees that Hitler was sentient, after all. Also, if it turns out that rogue-AI takeover is altruistically desirable, it would be better if more people agreed with this, though I expect an extremely tiny fraction of the population would ever come around to such a position.
Where sympathy for AGIs might have more impact is in cases of softer takeoff where AGIs work in the human economy and acquire increasing shares of wealth. The more humans care about AGIs for their own sakes, the more such transitions might be tolerated. Or would they? Maybe seeing AGIs as more human-like would evoke the xenophobia and ethnic hatred that we've seen throughout history whenever a group of people gains wealth (e.g., Jews in Medieval Europe) or steals jobs (e.g., immigrants of various types throughout history).
Personally, I think greater sympathy for AGI is likely net positive because it may help allay anti-alien prejudices that may make cooperation with AGIs harder. When a Homo sapiens tribe confronts an outgroup, often it reacts violently in an effort to destroy the evil foreigners. If instead humans could cooperate with their emerging AGI brethren, better outcomes would likely follow.
Charities working on this issue
What are some places where donors can contribute to make a difference on AI? The Foundational Research Institute (FRI) explores questions like these, though at the moment the organization is rather small. MIRI is larger and has a longer track record. Its values are more conventional, but it recognizes the importance of positive-sum opportunities to help many values systems, which includes suffering reduction. More reflection on these topics can potentially reduce suffering and further goals like eudaimonia, fun, and interesting complexity at the same time.
Because AI is affected by many sectors of society, these problems can be tackled from diverse angles. Many groups besides FRI and MIRI examine important topics as well, and these organizations should be explored further as potential charity recommendations.
Is MIRI's work too theoretical?
Note: This section was mostly written in late 2014 / early 2015, and not everything said here is fully up-to-date.
Most of MIRI's publications since roughly 2012 have focused on formal mathematics, such as logic and provability. These are tools not normally used in AGI research. I think MIRI's motivations for this theoretical focus are
- Pessimism about the problem difficulty: Luke Muehlhauser writes that "Especially for something as complex as Friendly AI, our message is: 'If we prove it correct, it might work. If we don’t prove it correct, it definitely won’t work.'"
- Not speeding unsafe AGI: Building real-world systems would contribute toward non-safe AGI research.
- Long-term focus: MIRI doesn't just want a system that's the next level better but aims to explore the theoretical limits of possibilities.
I personally think reason #3 is most compelling. I doubt #2 is hugely important given MIRI's small size, though it matters to some degree. #1 seems a reasonable strategy in moderation, though I favor approaches that look decently likely to yield non-terrible outcomes rather than shooting for the absolute best outcomes.
Software can be proved correct, and sometimes this is done for mission-critical components, but most software is not validated. I suspect that AGI will be sufficiently big and complicated that proving safety will be impossible for humans to do completely, though I don't rule out the possibility of software that would help with correctness proofs on large systems. Muehlhauser and comments on his post largely agree with this.
What kind of track record does theoretical mathematical research have for practical impact? There are certainly several domains that come to mind, such as the following.
- Auction game theory has made governments billions of dollars and is widely used in Internet advertising.
- Theoretical physics has led to numerous forms of technology, including electricity, lasers, and atomic bombs. However, immediate technological implications of the most theoretical forms of physics (string theory, Higgs boson, black holes, etc.) are less pronounced.
- Formalizations of many areas of computer science have helped guide practical implementations, such as in algorithm complexity, concurrency, distributed systems, cryptography, hardware verification, and so on. That said, there are also areas of theoretical computer science that have little immediate application. Most software engineers only know a little bit about more abstract theory and still do fine building systems, although if no one knew theory well enough to design theory-based tools, the software field would be in considerably worse shape.
All told, I think it's important for someone to do the kinds of investigation that MIRI is undertaking. I personally would probably invest more resources than MIRI is in hacky, approximate solutions to AGI safety that don't make such strong assumptions about the theoretical cleanliness and soundness of the agents in question. But I expect this kind of less perfectionist work on AGI control will increase as more people become interested in AGI safety.
There does seem to be a significant divide between the math-oriented conception of AGI and the engineering/neuroscience conception. Ben Goertzel takes the latter stance:
I strongly suspect that to achieve high levels of general intelligence using realistically limited computational resources, one is going to need to build systems with a nontrivial degree of fundamental unpredictability to them. This is what neuroscience suggests, it's what my concrete AGI design work suggests, and it's what my theoretical work on GOLEM and related ideas suggests. And none of the public output of SIAI researchers or enthusiasts has given me any reason to believe otherwise, yet.
Personally I think Goertzel is more likely to be right on this particular question. Those who view AGI as fundamentally complex have more concrete results to show, and their approach is by far more mainstream among computer scientists and neuroscientists. Of course, proofs about theoretical models like Turing machines and lambda calculus are also mainstream, and few can dispute their importance. But Turing-machine theorems do little to constrain our understanding of what AGI will actually look like in the next few centuries. That said, there's significant peer disagreement on this topic, so epistemic modesty is warranted. In addition, if the MIRI view is right, we might have more scope to make an impact to AGI safety, and it would be possible that important discoveries could result from a few mathematical insights rather than lots of detailed engineering work. Also, most AGI research is more engineering-oriented, so MIRI's distinctive focus on theory, especially abstract topics like decision theory, may target an underfunded portion of the space of AGI-safety research.
In "How to Study Unsafe AGI's safely (and why we might have no choice)," Punoxysm makes several points that I agree with, including that AGI research is likely to yield many false starts before something self-sustaining takes off, and those false starts could afford us the opportunity to learn about AGI experimentally. Moreover, this kind of ad-hoc, empirical work may be necessary if, as seems to me probable, fully rigorous mathematical models of safety aren't sufficiently advanced by the time AGI arrives.
Ben Goertzel likewise suggests that a fruitful way to approach AGI control is to study small systems and "in the usual manner of science, attempt to arrive at a solid theory of AGI intelligence and ethics based on a combination of conceptual and experimental-data considerations". He considers this view the norm among "most AI researchers or futurists". I think empirical investigation of how AGIs behave is very useful, but we also have to remember that many AI scientists are overly biased toward "build first; ask questions later" because
- building may be more fun and exciting than worrying about safety (Steven M. Bellovin observed with reference to open-source projects: "Quality takes work, design, review and testing and those are not nearly as much fun as coding".)
- there's more incentive from commercial applications and government grants to build rather than introspect
- scientists may want AGI sooner so that they personally or their children can reap its benefits.
On a personal level, I suggest that if you really like building systems rather than thinking about safety, you might do well to earn to give in software and donate toward AGI-safety organizations.
Yudkowsky (2016b) makes an interesting argument in reply to the idea of using empirical, messy approaches to AI safety: "If you sort of wave your hands and say like, 'Well, maybe we can apply this machine-learning algorithm, that machine-learning algorithm, the result will be blah blah blah', no one can convince you that you're wrong. When you work with unbounded computing power, you can make the ideas simple enough that people can put them on whiteboards and go like 'Wrong!', and you have no choice but to agree. It's unpleasant, but it's one of the ways the field makes progress."
Next steps
Here are some rough suggestions for how I recommend proceeding on AGI issues and, in [brackets], roughly how long I expect each stage to take. Of course, the stages needn't be done in a strict serial order, and step 1 should continue indefinitely, as we continue learning more about AGI from subsequent steps.
- Decide if we want human-controlled, goal-preserving AGI [5-10 years]. This involves exploring questions about what types of AGI scenarios might unfold and how much suffering would result from AGIs of various types.
- Assuming we decide we do want controlled AGI: Network with academics and AGI developers to raise the topic and canvass ideas [5-10 years]. We could reach out to academic AGI-like projects, including these listed by Pei Wang and these listed on Wikipedia, as well as to machine ethics and roboethics communities. There are already some discussions about safety issues among these groups, but I would expand the dialogue, have private conversations, write publications, hold conferences, etc. These efforts both inform us about the lay of the land and build connections in a friendly, mutualistic way.
- Lobby for greater funding of research into AGI safety [10-20 years]. Once the idea and field of AGI safety have become more mainstream, it should be possible to differentially speed up safety research by getting more funding for it -- both from governments and philanthropists. This is already somewhat feasible; for instance: "In 2014, the US Office of Naval Research announced that it would distribute $7.5 million in grants over five years to university researchers to study questions of machine ethics as applied to autonomous robots."
- The movement snowballs [decades]. It's hard to plan this far ahead, but I imagine that eventually (within 25-50 years?) AGI safety will become a mainstream political topic in a similar way as nuclear security is today. Governments may take over in driving the work, perhaps with heavy involvement from companies like Google. This is just a prediction, and the actual way things unfold could be different.
I recommend avoiding a confrontational approach with AGI developers. I would not try to lobby for restrictions on their research (in the short term at least), nor try to "slow them down" in other ways. AGI developers are the allies we need most at this stage, and most of them don't want uncontrolled AGI either. Typically they just don't see their work as risky, and I agree that at this point, no AGI project looks set to unveil something dangerous in the next decade or two. For many researchers, AGI is a dream they can't help but pursue. Hopefully we can engender a similar enthusiasm about pursuing AGI safety.
In the longer term, tides may change, and perhaps many AGI developers will desire government-imposed restrictions as their technologies become increasingly powerful. Even then, I'm doubtful that governments will be able to completely control AGI development (see, e.g., the criticisms by John McGinnis of this approach), so differentially pushing for more safety work may continue to be the most leveraged solution. History provides a poor track record of governments refraining from developing technologies due to ethical concerns; Eckersley and Sandberg (p. 187) cite "human cloning and land-based autonomous robotic weapons" as two of the few exceptions, with neither prohibition having a long track record.
I think the main way in which we should try to affect the speed of regular AGI work is by aiming to avoid setting off an AGI arms race, either via an AGI Sputnik moment or else by more gradual diffusion of alarm among world militaries. It's possible that discussing AGI scenarios too much with military leaders could exacerbate a militarized reaction. If militaries set their sights on AGI the way the US and Soviet Union did on the space race or nuclear-arms race during the Cold War, the amount of funding for unsafe AGI research might multiply by a factor of 10 or maybe 100, and it would be aimed in harmful directions.
Where to push for maximal impact?
Here are some candidates for the best object-level projects that altruists could work on with reference to AI. Because AI seems so crucial, these are also candidates for the best object-level projects in general. Meta-level projects like movement-building, career advice, earning to give, fundraising, etc. are also competitive. I've scored each project area out of 10 points to express a rough subjective guess of the value of the work for suffering reducers.
Research whether controlled or uncontrolled AI yields more suffering (score = 10/10)
- Pros:
- Figuring out which outcome is better should come before pushing ahead too far in any particular direction.
- This question remains non-obvious and so has very high expected value of information.
- None of the existing big names in AI safety have explored this question because reducing suffering is not the dominant priority for them.
- Cons:
Push for suffering-focused AI-safety approaches (score = 10/10)
Most discussions of AI safety assume that human extinction and failure to spread (human-type) eudaimonia are the main costs of takeover by uncontrolled AI. But as noted in this piece, AIs would also spread astronomical amounts of suffering. Currently no organization besides FRI is focused on how to do AI safety work with the primary aim of avoiding outcomes containing huge amounts of suffering.
One example of a suffering-focused AI-safety approach is to design AIs so that even if they do get out of control, they "fail safe" in the sense of not spreading massive amounts of suffering into the cosmos. For example:
- AIs should be inhibited from colonizing space, or if they do colonize space, they should do so in less harmful ways.
- "Minimizer" utility functions have less risk of creating new universes than "maximizer" ones do.
- Simpler utility functions (e.g., creating uniform paperclips) might require fewer suffering subroutines than complex utility functions would.
- AIs with expensive intrinsic values (e.g., maximize paperclips) may run fewer complex minds than AIs with cheaper values (e.g., create at least one paperclip on each planet), because AIs with cheaper values have lower opportunity cost for using resources and so can expend more of their cosmic endowment on learning about the universe to make sure they've accomplished their goals properly. (Thanks to a friend for this point.) From this standpoint, suffering reducers might prefer an AI that aims to "maximize paperclips" over one that aims to "make sure there's at least one paperclip per planet." However, perhaps the paperclip maximizer would prefer to create new universes, while the "at least one paperclip per planet" AI wouldn't; indeed, the "one paperclip per planet" AI might prefer to have a smaller multiverse so that there would be fewer planets that don't contain paperclips. Also, the satisficing AI would be easier to compromise with than the maximizing AI, since the satisficer's goals could be carried out more cheaply. There are other possibilities to consider as well. Maybe an AI with the instructions to "be 70% sure of having made one paperclip and then shut down all of your space-colonization plans" would not create much suffering (depending on how scrupulous the AI was about making sure that what it had created was really a paperclip, that it understood physics properly, etc.).
The problem with bullet #1 is that if you can succeed in preventing AGIs from colonizing space, it seems like you should already have been able to control the AGI altogether, since the two problems appear about equally hard. But maybe there are clever ideas we haven't thought of for reducing the spread of suffering even if humans lose total control.
Another challenge is that those who don't place priority on reducing suffering may not agree with these proposals. For example, I would guess that most AI scientists would say, "If the AGI kills humans, at least we should ensure that it spreads life into space, creates a complex array of intricate structures, and increases the size of our multiverse."
Work on AI control and value-loading problems (score = 4/10)
- Pros:
- At present, controlled AI seems more likely good than bad.
- Relatively little work thus far, so marginal effort may make a big impact.
- Cons:
- It may turn out that AI control increases net expected suffering.
- This topic may become a massive area of investment in coming decades, because everyone should theoretically care about it. Maybe there's more leverage in pushing on neglected areas of particular concern for suffering reduction.
Research technological/economic/political dynamics of an AI takeoff and push in better directions (score = 3/10)
By this I have in mind scenarios like those of Robin Hanson for emulation takeoff, or Bostrom's "The Future of Human Evolution".
- Pros:
- Many scenarios have not been mapped out. There's a need to introduce economic/social realism to AI scenarios, which at present often focus on technical challenges and idealized systems.
- Potential to steer dynamics in more win-win directions.
- Cons:
- Broad subject area. Work may be somewhat replaceable as other researchers get on board in the coming decades.
- More people have their eyes on general economic/social trends than on specific AI technicalities, so there may be lower marginal returns to additional work in this area.
- While technological progress is probably the biggest influence on history, it's also one of the more inevitable influences, making it unclear how much we can affect it. Our main impact on it would seem to come through differential technological progress. In contrast, values, institutions, and social movements can go in many different directions depending on our choices.
Promote the ideal of cooperation on AI values (e.g., CEV) (score = 2/10)
- Pros:
- Whereas technical work on AI safety is of interest to and can be used by anyone -- including militaries and companies with non-altruistic aims -- promoting CEV is more important to altruists. I don't see CEV as a likely outcome even if AI is controlled, because it's more plausible that individuals and groups will push for their own agendas.
- Cons:
- It's very hard to achieve CEV. It depends on a lot of really complex political and economic dynamics that millions of altruists are already working to improve.
- Promoting CEV as an ideal to approximate may be confused in people's minds with suggesting that CEV is likely to happen. The latter assumption is probably wrong and so may distort people's beliefs about other crucial questions. For instance, if CEV was likely, then it would be more likely that suffering reducers should favor controlled AI; but the fact of the matter is that anything more than crude approximations to CEV will probably not happen.
Promote a smoother, safer takeoff for brain emulation (score = 2/10)
- Pros:
- As noted above, it's more plausible that suffering reducers should favor emulation safety than AI safety.
- The topic seems less explored than safety of de novo AIs.
- Cons:
- I find it slightly more likely that de novo AI will come first, in which case this work wouldn't be as relevant. In addition, AI may have more impacts on society even before it reaches the human level, again making it slightly more relevant.
- Safety measures might require more political and less technical work, in which case it's more likely to be done correctly by policy makers in due time. The value-loading problem seems much easier for emulations because it might just work to upload people with good values, assuming no major value corruption during or after uploading.
- Emulation is more dependent on relatively straightforward engineering improvements and less on unpredictable insight than AI. Thus, it has a clearer development timeline, so there's less urgency to investigate issues ahead of time to prepare for an unexpected breakthrough.
Influence the moral values of those likely to control AI (score = 2/10)
- Pros:
- Altruists, and especially those with niche values, may want to push AI development in more compassionate directions. This could make sense because altruists are most interested in ethics, while even power-hungry states and money-hungry individuals should care about AI safety in the long run.
- Cons:
- This strategy is less cooperative. It's akin to defecting in a tragedy of the commons -- pushing more for what you want rather than what everyone wants. If you do push for what everyone wants, then I would consider such work more like the "Promote the ideal of cooperation" item.
- Empirically, there isn't enough investment in other fundamental AI issues, and those may be more important than further engaging already well trodden ethical debates.
Promote a singleton over multipolar dynamics (score = 1/10)
- Pros:
- A singleton, whether controlled or uncontrolled, would reduce the risk of conflicts that cause cosmic damage.
- Unclear:
- There are many ways to promote a singleton. Encouraging cooperation on AI development would improve pluralism and human control in the outcome. Faster development by the leading AI project might also increase the chance of a singleton while reducing the probability of human control of the outcome. Stronger government regulation, surveillance, and coordination would increase chances of a singleton, as would global cooperation.
- Cons:
- Speeding up the leading AI project might exacerbate AI arms races. And in any event, it's currently far too early to predict what group will lead the AI race.
Other variations
In general, there are several levers that we can pull on:
- safety
- arrival time relative to other technologies
- influencing values
- cooperation
- shaping social dynamics
- raising awareness
- etc.
These can be applied to any of
- de novo AI
- brain emulation
- other key technologies
- etc.
Is it valuable to work at or influence an AGI company?
Projects like DeepMind, Vicarious, OpenCog, and the AGI research teams at Google, Facebook, etc. are some of the leaders in AGI technology. Sometimes it's proposed that since these teams might ultimately develop AGI, altruists should consider working for, or at least lobbying, these companies so that they think more about AGI safety.
One's assessment of this proposal depends on one's view about AGI takeoff. My own opinion may be somewhat in the minority relative to expert surveys, but I'd be surprised if we had human-level AGI before 50 years from now, and my median estimate might be like ~90 years from now. That said, the idea of AGI arriving at a single point in time is probably a wrong framing of the question. Already machines are super-human in some domains, while their abilities are far below humans' in other domains. Over the coming decades, we'll see lots of advancement in machine capabilities in various fields at various speeds, without any single point where machines suddenly develop human-level abilities across all domains. Gradual AI progress over the coming decades will radically transform society, resulting in many small "intelligence explosions" in various specific areas, long before machines completely surpass humans overall.
In light of my picture of AGI, I think of DeepMind, Vicarious, etc. as ripples in a long-term wave of increasing machine capabilities. It seems extremely unlikely that any one of these companies or its AGI system will bootstrap itself to world dominance on its own. Therefore, I think influencing these companies with an eye toward "shaping the AGI that will take over the world" is probably naive. That said, insofar as these companies will influence the long-term trajectory of AGI research, and insofar as people at these companies are important players in the AGI community, I think influencing them has value -- just not vastly more value than influencing other powerful people.
That said, as noted previously, early work on AGI safety has the biggest payoff in scenarios where AGI takes off earlier and harder than people expected. If the marginal returns to additional safety research are many times higher in these "early AGI" scenarios, then it could still make sense to put some investment into them even if they seem very unlikely.
Should suffering reducers focus on AGI safety?
If, upon further analysis, it looks like AGI safety would increase expected suffering, then the answer would be clear: Suffering reducers shouldn't contribute toward AGI safety and should worry somewhat about how their messages might incline others in that direction. However, I find it reasonably likely that suffering reducers will conclude that the benefits of AGI safety outweigh the risks. In that case, they would face a question of whether to push on AGI safety or on other projects that also seem valuable.
Reasons to focus on other projects:
- There are several really smart people working on AGI safety right now. The number of brilliant altruists focused on AGI safety probably exceeds the number of brilliant altruists focused on reducing suffering in the far future by several times over. Thus, it seems plausible that there remain more low-hanging fruit for suffering reducers to focus on other crucial considerations rather than delving into the technical details of implementing AGI safety.
- I expect that AGI safety will require at least, say, thousands of researchers and hundreds of thousands of programmers to get right. AGI safety is a much harder problem than ordinary computer security, and computer security demand is already very high: "In 2012, there were more than 67,400 separate postings for cybersecurity-related jobs in a range of industries". Of course, that AGI safety will need tons of researchers eventually needn't discount the value of early work, and indeed, someone who helps grow the movement to a large size would contribute as much as many detail-oriented AGI safety researchers later.
Reasons to focus on AGI safety:
- Most other major problems are also already being tackled by lots of smart people.
- AGI safety is a cause that many value systems can get behind, so working on it can be seen as more "nice" than focusing on areas that are more specific to suffering-reduction values.
All told, I would probably pursue a mixed strategy: Work primarily on questions specific to suffering reduction, but direct donations and resources toward AGI safety when opportunities arise. Some suffering reducers particularly suited to work on AGI safety could go in that direction while others continue searching for points of leverage not specific to controlling AGI.
Acknowledgments
Parts of this piece were inspired by discussions with various people, including David Althaus, Daniel Dewey, and Caspar Oesterheld.
Footnotes
- Stuart Armstrong agrees that AIXI probably isn't a feasible approach to AGI, but he feels there might exist other, currently undiscovered mathematical insights like AIXI that could yield AGI in a very short time span. Maybe, though I think this is pretty unlikely. I suppose at least a few people should explore these scenarios, but plausibly most of the work should go toward pushing on the more likely outcomes. (back)
- Marcus Hutter imagines a society of AIs that compete for computing resources in a similar way as animals compete for food and space. Or like corporations compete for employees and market share. He suggests that such competition might render initial conditions irrelevant. Maybe, but it's also quite plausible that initial conditions would matter a lot. Many evolutionary pathways depended sensitively on particular events -- e.g., asteroid impacts -- and the same is true for national, corporate, and memetic power. (back)
- Another part of the answer has to do with incentive structures -- e.g., a founder has more incentive to make a company succeed if she's mainly paid in equity than if she's paid large salaries along the way. (back)
- Or maybe more? Nikola Danaylov reports rumored estimates of $50-150 million for Watson's R&D. (back)
- For Atari games, the current image on the screen is not all the information required, because, for example, you need to be able to tell whether a ball is moving toward you or away from you, and those two situations aren't distinguishable purely based on a static snapshot. Therefore, Mnih et al. (2015) used sequences of the past plus present screenshots and past actions as the state information (see "Methods" section). Still, all of this information was readily available and representable in a clean way. (back)
- What if we take the set of actions to be outputting one letter at a time, rather than outputting a whole string of letters? That is, the set of actions is {a, b, c, ..., z, A, B, C, ..., Z}. This is fewer than the number of actions that AlphaGo considered at each step. The problem is that any given sequence of letters is very unlikely to achieve a desired outcome, so it will take forever to get meaningful feedback. For example, suppose the goal is, given an input question, to produce an answer that a human judge finds humorous. If the answer isn't humorous, the reinforcement learner gets no reward. The learner would output mostly garbage (say, "klAfSFpqA", "QmpzRwWSa", and so on). It would take forever for the agent to output intelligible speech and even longer for it to output humorous speech. (And good luck finding a human willing to give feedback for this long, or modeling a human's sense of humor well enough to provide accurate simulated feedback.) Of course, this system could be improved in various ways. For example, we could give it a dictionary and only let it output complete words. We could train an n-gram language model so that the agent would output mostly coherent speech. Perhaps a few other tricks could be applied so that the agent would be more likely to hit upon funny sentences. But by this point, we've turned a supposed general-intelligence problem into a narrow-intelligence problem by specifying lots of pre-configured domain knowledge and heuristics. (back)
- I prefer to use the terminology "controlled" and "uncontrolled" AI because these seem most direct and least confusing. (These are short for "human-controlled AI" and "human-uncontrolled AI".)
The term "friendly AI" can be confusing because it involves normative judgments, and it's not clear if it means "friendly to the interests of humanity's survival and flourishing" or "friendly to the goals of suffering reduction" or something else. One might think that "friendly AI" just means "AI that's friendly to your values", in which case it would be trivial that friendly AI is a good thing (for you). But then the definition of friendly AI would vary from person to person.
"Aligned AI" might be somewhat less value-laden than "friendly AI", but it still connotes to me a sense that there's a "(morally) correct target" that the AI is being aligned toward.
"Controlled AI" is still somewhat ambiguous because it's unspecified which humans have control of the AI and what goals they're giving it, but the label works as a general category to designate "AIs that are successfully controlled by some group of humans". And I like that this category can include "AIs controlled by evil humans", since work to solve the AI control problem increases the probability that AIs will be controlled by evil humans as well as by "good" ones. (back)
- Jan Leike pointed out to me that "even if the universe cannot be approximated to an arbitrary precision by a computable function, Solomonoff induction might still converge. For example, suppose some physical constant is actually an incomputable real number and physical laws are continuous with respect to that parameter, this would be good enough to allow Solomonoff induction to learn to predict correctly." However, one can also contemplate hypotheses that would not even be well approximated by a computable function, such as an actually infinite universe that can't be adequately modeled by any finite approximation. Of course, it's unclear whether we should believe in speculative possibilities like this, but I wouldn't want to rule them out just because of the limitations of our AI framework. It may be hard to make sensible decisions using finite computing resources regarding uncomputable hypotheses, but maybe there are frameworks better than Solomonoff induction that could be employed to tackle the challenge. (back)
- John Kubiatowicz notes that space-shuttle software is some of the best tested and yet still has some bugs. (back)
- Emulations wouldn't be hurt by engineered biological pathogens, and in the event of nuclear winter, emulations could still be powered by non-sun energy sources. However, maybe the risk of global digital pandemics in the form of virulent computer viruses would be non-trivial for emulations? (back)
The post Artificial Intelligence and Its Implications for Future Suffering appeared first on Center on Long-Term Risk.
]]>
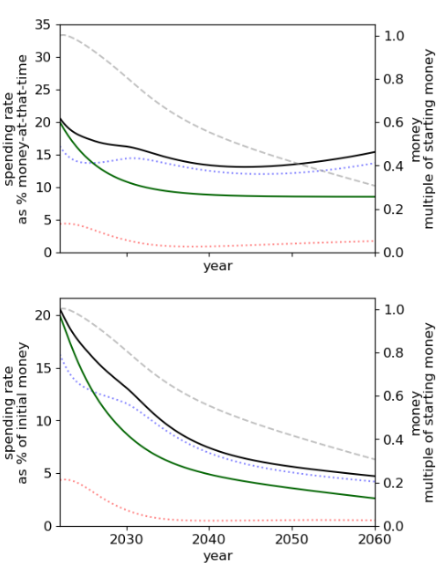
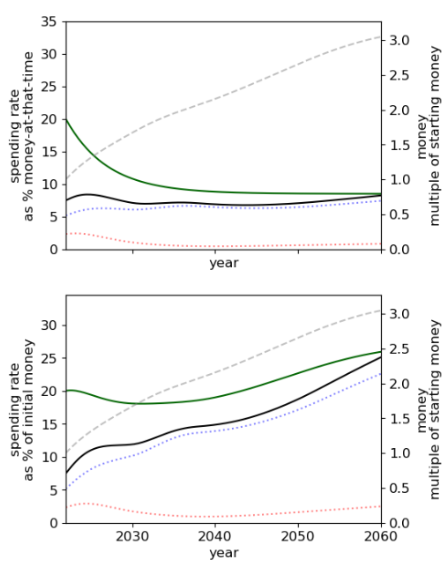
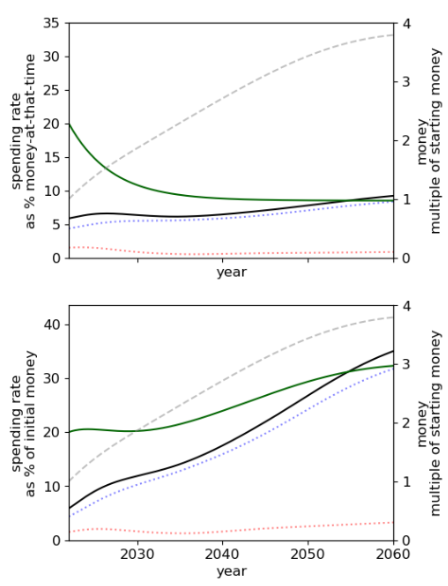
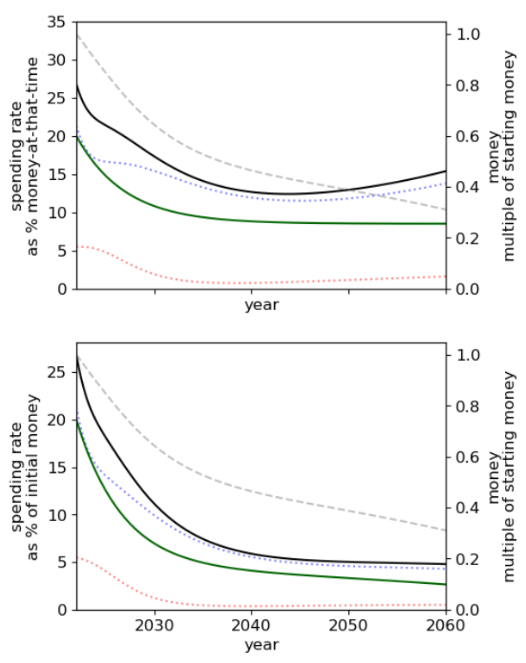
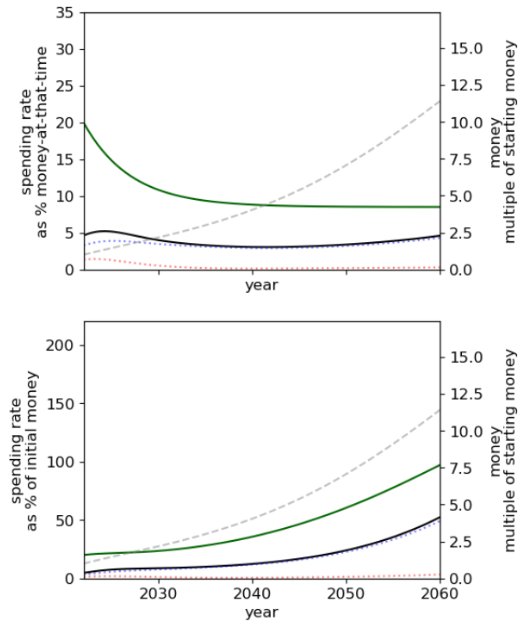
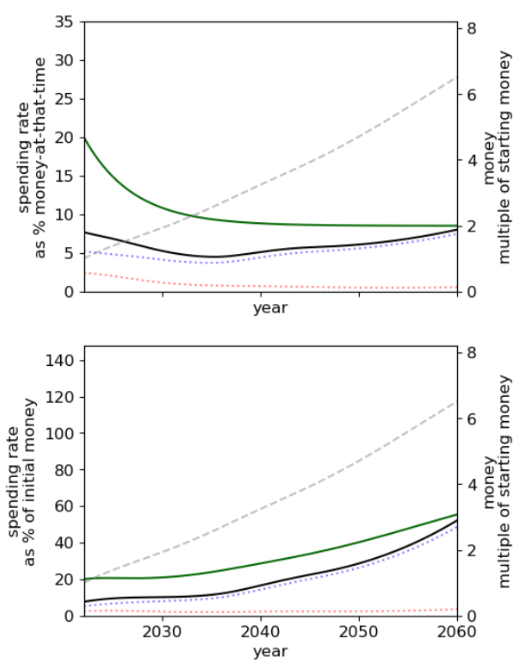
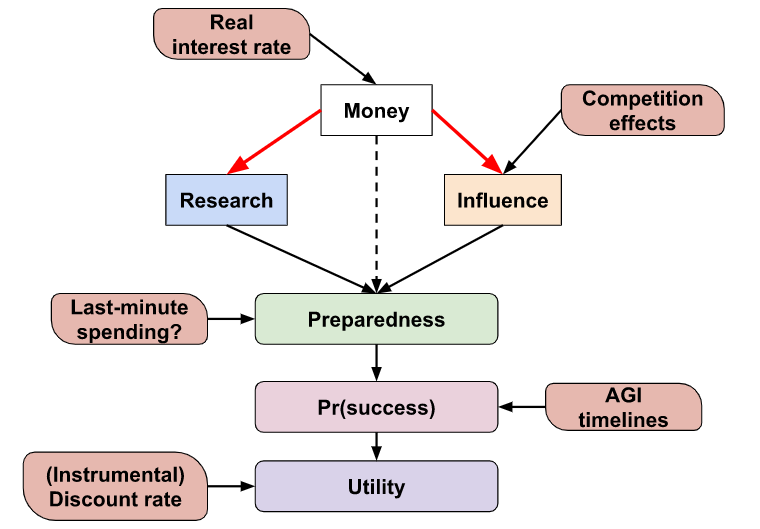
 to describe how ‘ready’ we are if AGI arrived at time
to describe how ‘ready’ we are if AGI arrived at time  Preparedness is a function of research and influence: the more we have of each the more we are prepared. The user inputs the relative importance of each research and influence as well as the degree they are substitutable.
Preparedness is a function of research and influence: the more we have of each the more we are prepared. The user inputs the relative importance of each research and influence as well as the degree they are substitutable. 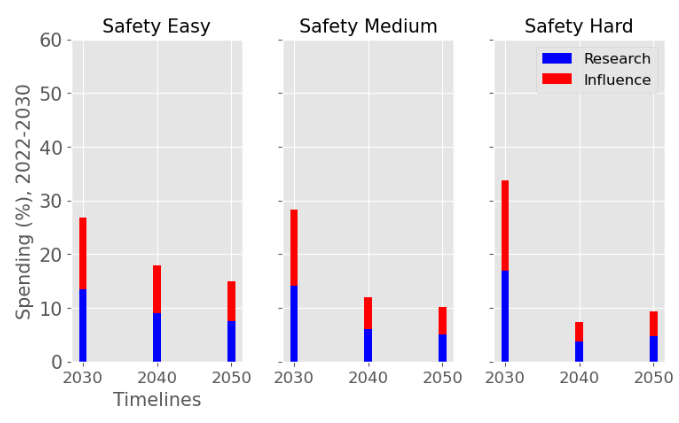
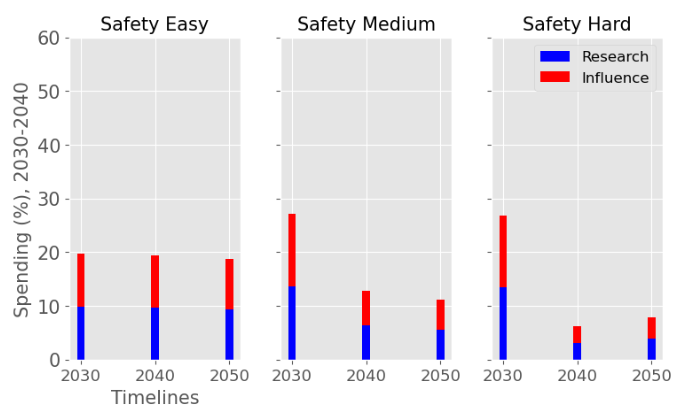
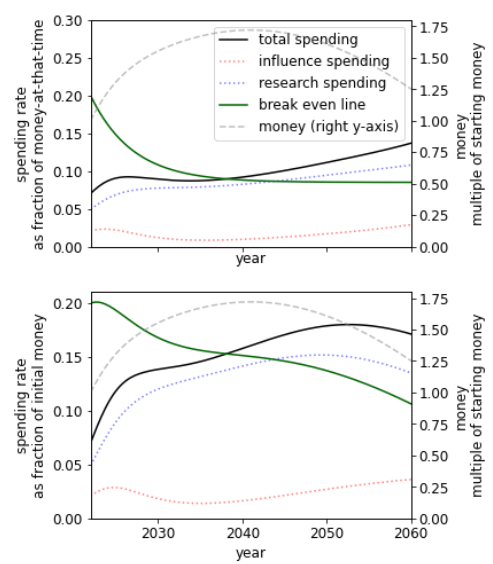
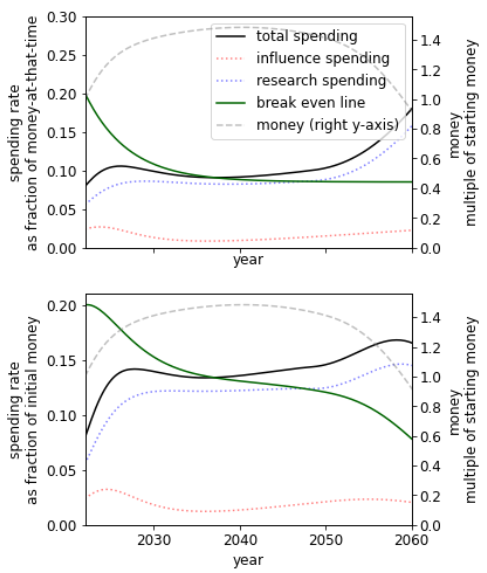
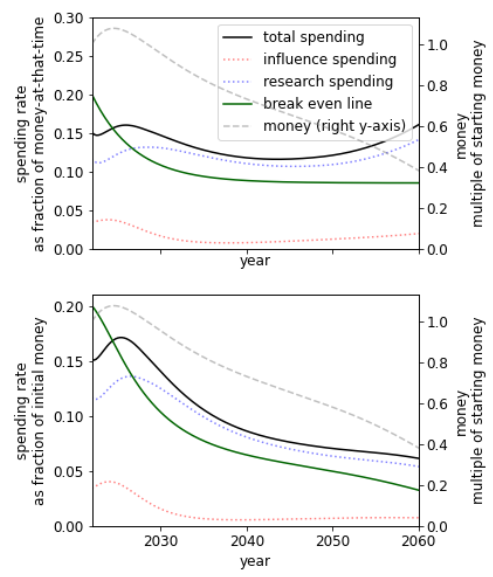



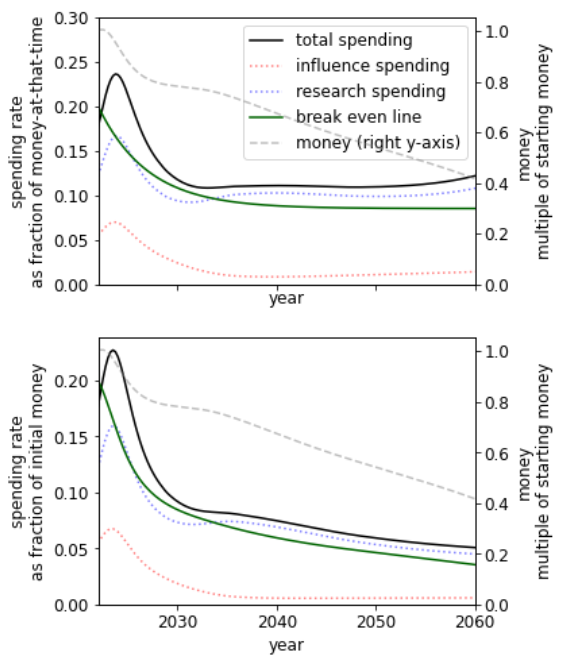
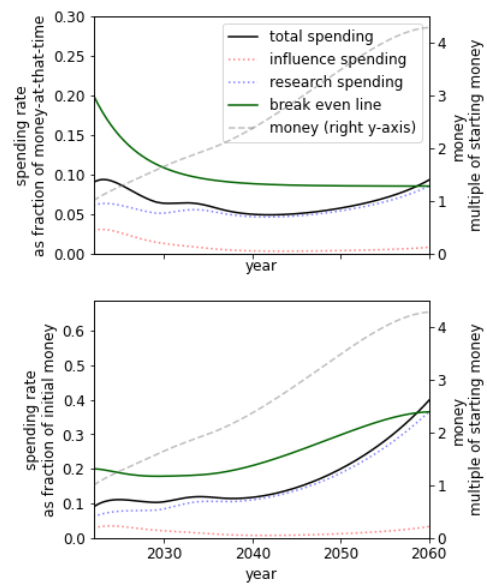
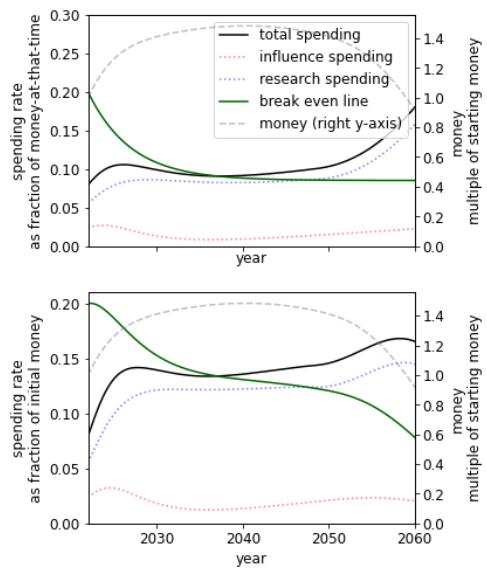
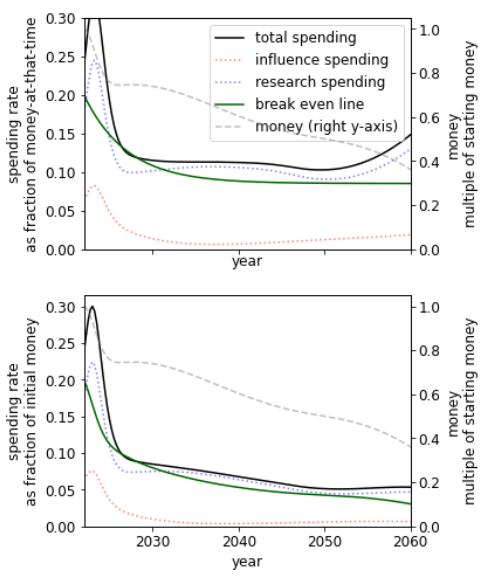
 controls whether research becomes cheaper as we accumulate more research (
controls whether research becomes cheaper as we accumulate more research ( ) or more expensive (
) or more expensive ( ). The former could describe a case where an increase in research leads to the increasing ability to parallelize research or break down problems into more easily solvable subproblems. The latter could describe a case where an increase in research leads to an increasingly bottlenecked field, where further progress depends on solving a small number of problems that are only solvable by a few people.
). The former could describe a case where an increase in research leads to the increasing ability to parallelize research or break down problems into more easily solvable subproblems. The latter could describe a case where an increase in research leads to an increasingly bottlenecked field, where further progress depends on solving a small number of problems that are only solvable by a few people.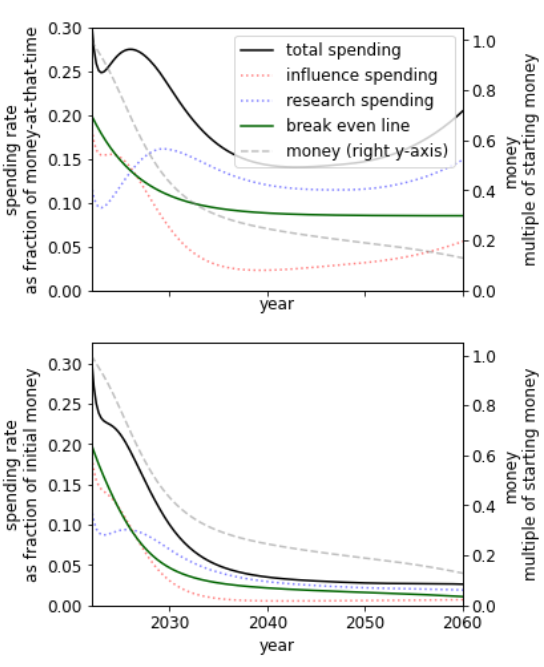
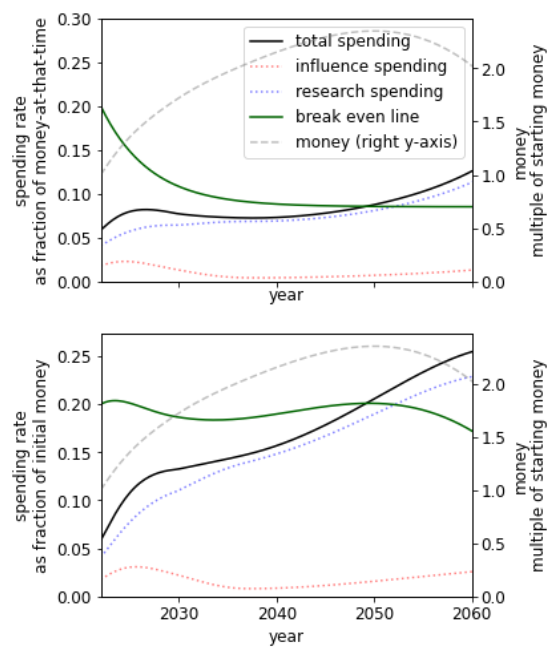
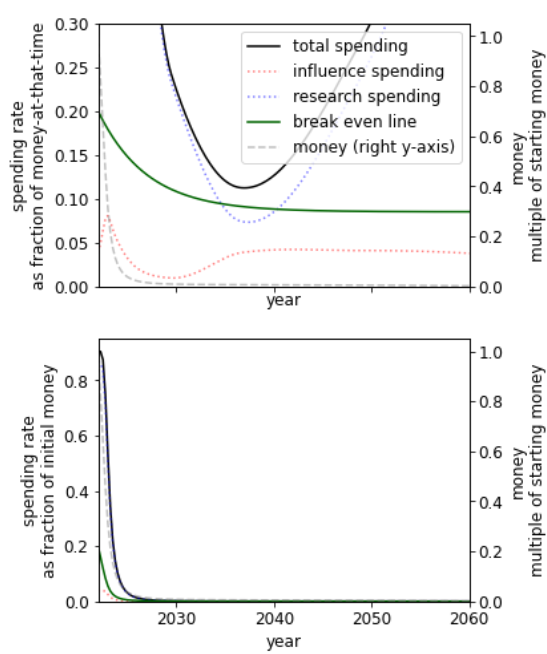

 )
)
 such that the field can become more or less bottlenecked as it progresses and the price of research changes accordingly.
such that the field can become more or less bottlenecked as it progresses and the price of research changes accordingly.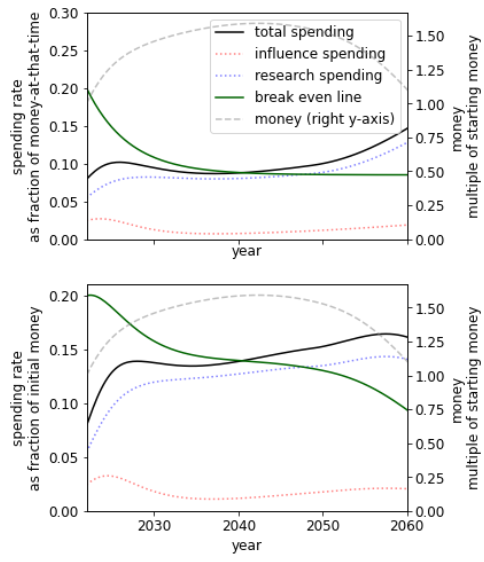

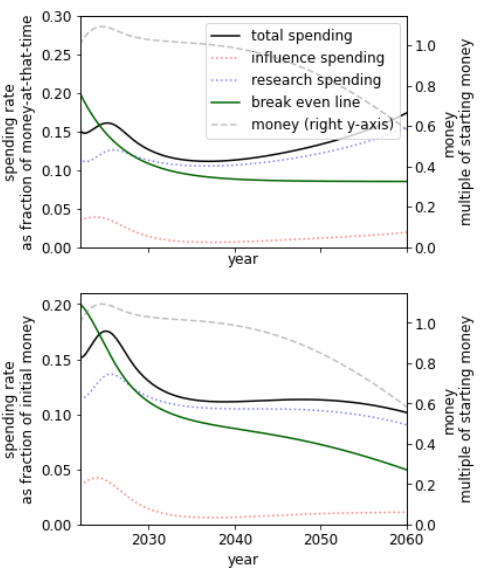
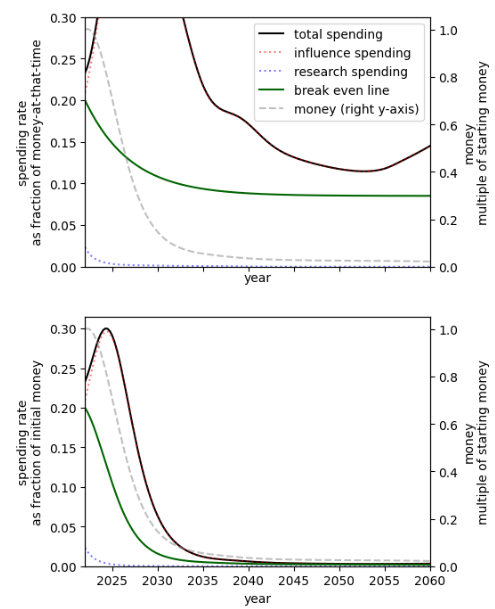
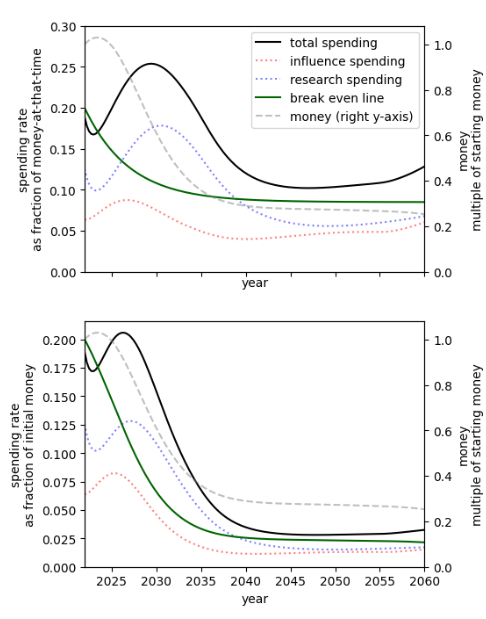
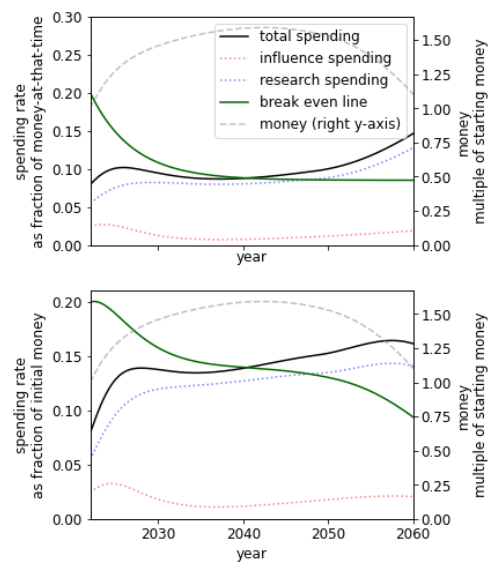
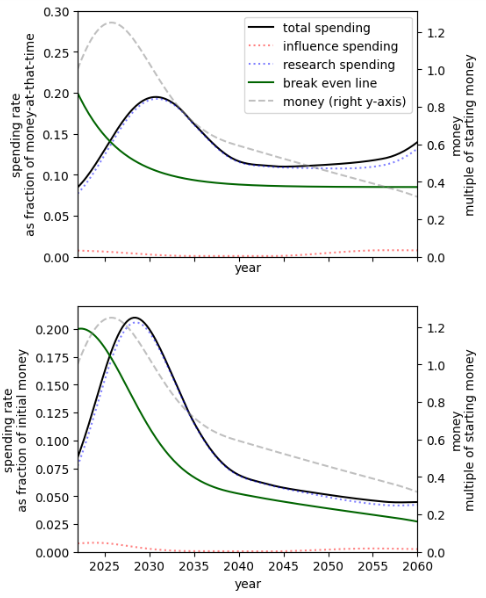
 . Saving money now, even though AGI is expected sometime soon, is only occasionally recommended by the model. One case occurs with (1) a sufficiently low probability of success but steep gains to this probability after some amount of preparedness that is achievable in the next few decades, (2) a low discount rate, and either (a) that influence does not get too much more expensive over time or (b) influence is not too important.
. Saving money now, even though AGI is expected sometime soon, is only occasionally recommended by the model. One case occurs with (1) a sufficiently low probability of success but steep gains to this probability after some amount of preparedness that is achievable in the next few decades, (2) a low discount rate, and either (a) that influence does not get too much more expensive over time or (b) influence is not too important.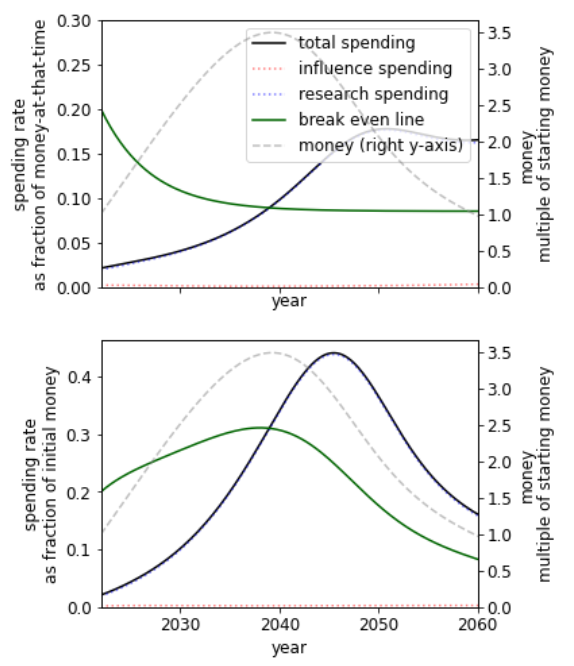
 , the difficulty is hard
, the difficulty is hard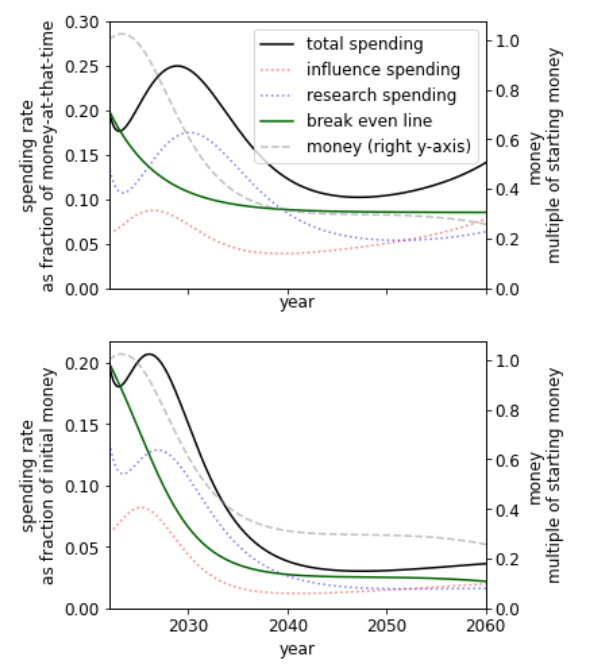
 . This supposes that research being done by outsiders is (directly) proportional to the research ‘we’ already have (where in this case, research done by outsiders is included in
. This supposes that research being done by outsiders is (directly) proportional to the research ‘we’ already have (where in this case, research done by outsiders is included in  ). Since we model exponential appreciation, appreciation leads to a research explosion. One could slow this research explosion by supposing the appreciation term was
). Since we model exponential appreciation, appreciation leads to a research explosion. One could slow this research explosion by supposing the appreciation term was  for some
for some  .
. to the expression for
to the expression for  that accounts for the exogenous rate of growth of research. Alternatively, one could consider a radically different model of research that considered our spending on research as simply speeding up the progress that will otherwise happen (conditioning on no global catastrophe).
that accounts for the exogenous rate of growth of research. Alternatively, one could consider a radically different model of research that considered our spending on research as simply speeding up the progress that will otherwise happen (conditioning on no global catastrophe). such that we can ‘push’ timelines down the road with more influence.
such that we can ‘push’ timelines down the road with more influence. such that marginal returns to spending on research and influence changed over time, similar to how the real interest rate
such that marginal returns to spending on research and influence changed over time, similar to how the real interest rate  changes over time. This would require more input from the user. Another extension could allow for the returns to be a function of how much was spent last year. However, such an extension would increase the model's complexity and decrease its usability, simplicity and (potentially) solvability.
changes over time. This would require more input from the user. Another extension could allow for the returns to be a function of how much was spent last year. However, such an extension would increase the model's complexity and decrease its usability, simplicity and (potentially) solvability. .
. or set
or set 



 (for no influence) or
(for no influence) or  (for no research) [in this case,
(for no research) [in this case,  does not matter]
does not matter]![\[\begin{array}{ccl} \dot{M}(t)&=&r\cdot M(t)-x(t)\\[0.2cm] \dot{R}(t)&=&x_R(t)^{\eta_R} \\[0.2cm] U &=& \displaystyle\int_0^\infty p(t) \cdot \dfrac{1}{1+e^{-l(R(t)- R_0)}} dt \end{array}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-19068bcb479721ef05c883640bfd7a1f_l3.png "Rendered by QuickLaTeX.com")
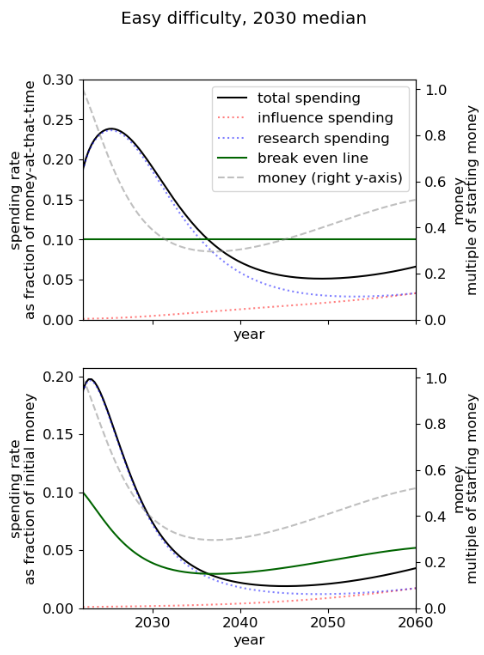
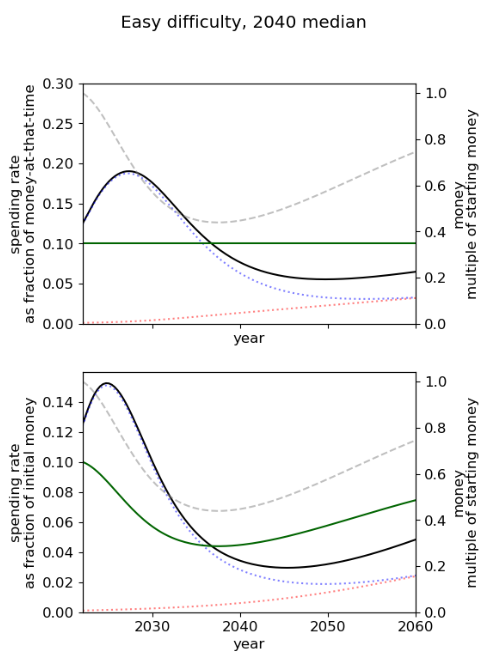
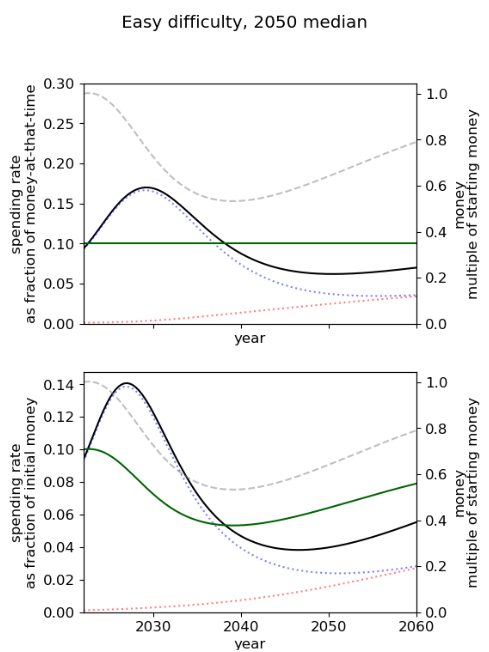
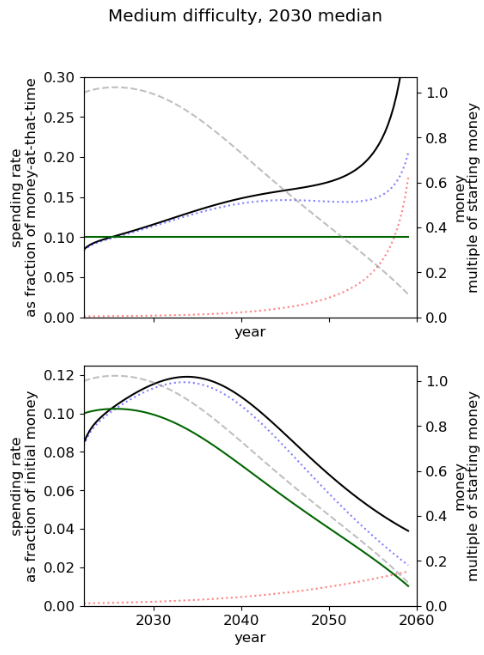
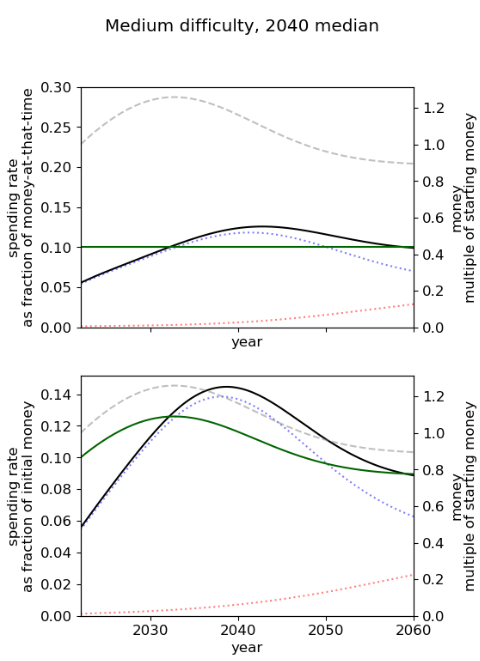
 .
.![\[\dot{M}(t)=r(t)\cdot M(t) - x_R(t) - x_I(t) + \Phi(t),\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-03478a5727ea2222341da8f6ca89cb94_l3.png "Rendered by QuickLaTeX.com")
 can model endogenous and non-continuous growth of funding.
can model endogenous and non-continuous growth of funding. , and down with spending on research,
, and down with spending on research,  , and spending on influence,
, and spending on influence,  .
.![\[\dot{M}(t) = r(t)\cdot M(t) - x_R(t) -x_I(t)\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-9f06edc704d9768ba8fb2c6071354035_l3.png "Rendered by QuickLaTeX.com")
![\[\dot{R}(t) = x_R(t)^{\eta_R}\cdot R(t)^{\alpha_R}+\lambda_R R(t)\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-a9824085875fd70deb567d87e08cef21_l3.png "Rendered by QuickLaTeX.com")
 is the marginal returns to spending on research
is the marginal returns to spending on research is the rate of appreciation of the stock of research
is the rate of appreciation of the stock of research which obeys
which obeys![\[\dot{I}(t) = x_I(t)^{\eta_I}\cdot I(t)^{\alpha_I} c(t)-\lambda_I I(t)\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-b1216f2d8404596c8293ec8e968c0ede_l3.png "Rendered by QuickLaTeX.com")
 describes how the influence gained per unit money changes over time due to competition effects. That is, over time as the field of AGI influencers crowd each unit of influence can be more expensive.
describes how the influence gained per unit money changes over time due to competition effects. That is, over time as the field of AGI influencers crowd each unit of influence can be more expensive. years away and that we can spend fraction
years away and that we can spend fraction  of our money on research and influence.
of our money on research and influence. and
and  for the amount of research and influence we have in expectation at AGI take-off if the fire alarm occurred at time
for the amount of research and influence we have in expectation at AGI take-off if the fire alarm occurred at time  which can be different from their pre-fire alarm values.
which can be different from their pre-fire alarm values. for the constant spending rate on research post-fire alarm. We take
for the constant spending rate on research post-fire alarm. We take  where
where  is the fraction of post fire-alarm spending. The system
is the fraction of post fire-alarm spending. The system ![\[\tilde{R'}(\tau) =y_R^{\eta_{R, FA}}\cdot \tilde{R}(\tau)^{\alpha_{R, FA}} ,\, \tilde{R}(0) = R(t)\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-da18f556e285b448049e86610f5bf203_l3.png "Rendered by QuickLaTeX.com")

 and system
and system![\[\tilde{I}(\tau) = y_I^{\eta_{I,FA}}\cdot \tilde{I}(\tau)^{\alpha_{I,FA}}\cdot \tilde{c}(t), \, \tilde{I}(0) = I(t)\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-343d39bd49b64341f36d836bf1da7f98_l3.png "Rendered by QuickLaTeX.com")
 is the competition factor at the start of the fire alarm period and is chosen by the user to either be a constant or function of
is the competition factor at the start of the fire alarm period and is chosen by the user to either be a constant or function of  . Note that the user can state that no fire alarm occurs; setting the
. Note that the user can state that no fire alarm occurs; setting the  implies
implies  and so
and so  and so
and so  .
. is given by
is given by![\[S(t) :=(\gamma \cdot\hat{R}(t)^{\rho}+(1-\gamma)\cdot \hat{I}(t)^{\rho})^{1/\rho}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-8cc11f5ded916d79033d88c1cb8d1883_l3.png "Rendered by QuickLaTeX.com")
 and
and  where the user chooses
where the user chooses  and
and ![\[Q(t) := 1+e^{-l\cdot(S-S_0)}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-e500fe032212fd67f589ae828585d56d_l3.png "Rendered by QuickLaTeX.com")
 and
and  determined by the user’s beliefs about the difficulty of making AGI safe.
determined by the user’s beliefs about the difficulty of making AGI safe.![\[U = \int_0^{\infty}Q(t)\cdot p(t)\cdot e^{-dt} dt\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-52155ad3cd1677f5a236e56cde88d629_l3.png "Rendered by QuickLaTeX.com")
 is the user’s AGI timelines and
is the user’s AGI timelines and  is some discount rate.
is some discount rate.
![\[H(t)=Q(t)\cdot p(t)\cdot e^{-dt}+v_M(t)\cdot \dot{M}(t)+v_R(t)\cdot \dot{R}(t)+v_I(t)\cdot \dot{I}(t)\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-6825b3baa4f191f0ef1ca6461c2acdcd_l3.png "Rendered by QuickLaTeX.com")
 are the costate variables.
are the costate variables.


 implying an AGI success in 2100 is worth
implying an AGI success in 2100 is worth  as much as a win today. As we discuss in the limitations section, the discount rate
as much as a win today. As we discuss in the limitations section, the discount rate 
 .
. .
. . Our 90% confidence interval is
. Our 90% confidence interval is  .
. . Our 90% confidence interval is
. Our 90% confidence interval is  .
. is the rate at which the real interest rate moves from
is the rate at which the real interest rate moves from  to
to  .
. controls the marginal returns to spending on influence. For
controls the marginal returns to spending on influence. For  we receive diminishing marginal returns.
we receive diminishing marginal returns. fraction of spending per year on influence leads to
fraction of spending per year on influence leads to  fraction of increase in growth of influence in that year. For example,
fraction of increase in growth of influence in that year. For example,  implies the top 20% of spending leads to roughly 80% of returns i.e. the
implies the top 20% of spending leads to roughly 80% of returns i.e. the  per year, but investing in AI labs with the purpose of influencing their decisions may cost on the order of
per year, but investing in AI labs with the purpose of influencing their decisions may cost on the order of  per year.
per year. which implies doubling spending on influence lead to
which implies doubling spending on influence lead to  times more growth of influence Our 90% confidence interval is
times more growth of influence Our 90% confidence interval is  .
. , which implies a doubling of research spending leads to
, which implies a doubling of research spending leads to  times increase in research growth and that 20% of the spending in research accounts for
times increase in research growth and that 20% of the spending in research accounts for  of the increase in research growth.
of the increase in research growth. include using the distribution of karma on the Alignment Forum, citations in journals or estimates of researchers’ outputs.
include using the distribution of karma on the Alignment Forum, citations in journals or estimates of researchers’ outputs. .
. implies that influence becomes cheaper as we get more influence. Factors that push in this direction include:
implies that influence becomes cheaper as we get more influence. Factors that push in this direction include: implies that influence becomes more expensive as we get more influence. Factors that point in this direction include:
implies that influence becomes more expensive as we get more influence. Factors that point in this direction include: the price is constant.
the price is constant. . This implies a doubling of influence leads to one unit of spending on influence leading to
. This implies a doubling of influence leads to one unit of spending on influence leading to  .
. implies that research becomes cheaper as we get more research. Factors that push in this direction include:
implies that research becomes cheaper as we get more research. Factors that push in this direction include: implies that research becomes more expensive as we get more research. Factors that push in this direction include:
implies that research becomes more expensive as we get more research. Factors that push in this direction include: . Our 90% confidence interval is
. Our 90% confidence interval is  .
. controls the rate of appreciation, for
controls the rate of appreciation, for  , or depreciation, for
, or depreciation, for  , of our stock of influence. It seems very likely that
, of our stock of influence. It seems very likely that  , which implies a half-life of around
, which implies a half-life of around  years. Our 90% confidence interval is
years. Our 90% confidence interval is 
 , of our stock of influence.
, of our stock of influence. and
and  . Note that for
. Note that for  , such research can be instrumentally useful for later years due to its ability to make future work cheaper by, for example, attracting new talent.
, such research can be instrumentally useful for later years due to its ability to make future work cheaper by, for example, attracting new talent. . Our 90% confidence interval is
. Our 90% confidence interval is  .
. more expensive per unit that it was in 2015. Our 90% confidence interval is (0.001, 0.1).
more expensive per unit that it was in 2015. Our 90% confidence interval is (0.001, 0.1). and
and  can apply.
can apply. (worse returns during the fire alarm period)
(worse returns during the fire alarm period) (better returns during the fire alarm period)
(better returns during the fire alarm period) , implying that the amount of research we can do in the post-fire-alarm period is not very dependent on the money we have.
, implying that the amount of research we can do in the post-fire-alarm period is not very dependent on the money we have. .
. and
and  . That is, during the fire alarm period it is even cheaper to get influence once you already have some than before this phase and that this effect is greater during the fire alarm period (the first inequality). In the case there is panic, it seems people will be looking for trustworthy organisations to defer to and execute a plan.
. That is, during the fire alarm period it is even cheaper to get influence once you already have some than before this phase and that this effect is greater during the fire alarm period (the first inequality). In the case there is panic, it seems people will be looking for trustworthy organisations to defer to and execute a plan. That is, during the fire alarm period the amount of existing research decreases the cost of new research.
That is, during the fire alarm period the amount of existing research decreases the cost of new research. and
and  .
. . Otherwise, you should set
. Otherwise, you should set  .
. , our preparedness can be entirely bottlenecked by the stock we have the least (weighted by
, our preparedness can be entirely bottlenecked by the stock we have the least (weighted by  gives the
gives the  .
. . We think that the problem is mainly a technical problem, but in practise cannot be solved without influencing AI developers.
. We think that the problem is mainly a technical problem, but in practise cannot be solved without influencing AI developers. which includes things such as skills, people, some types of knowledge and trust. They can choose to spend this stock
which includes things such as skills, people, some types of knowledge and trust. They can choose to spend this stock  to produce a stock of things that depreciate
to produce a stock of things that depreciate  that are immediately helpful in increasing the probability of success. This could comprise things such as the implementation of safety ideas on current systems or the product of asking for favours of AI developers or policymakers.
that are immediately helpful in increasing the probability of success. This could comprise things such as the implementation of safety ideas on current systems or the product of asking for favours of AI developers or policymakers. which is
which is 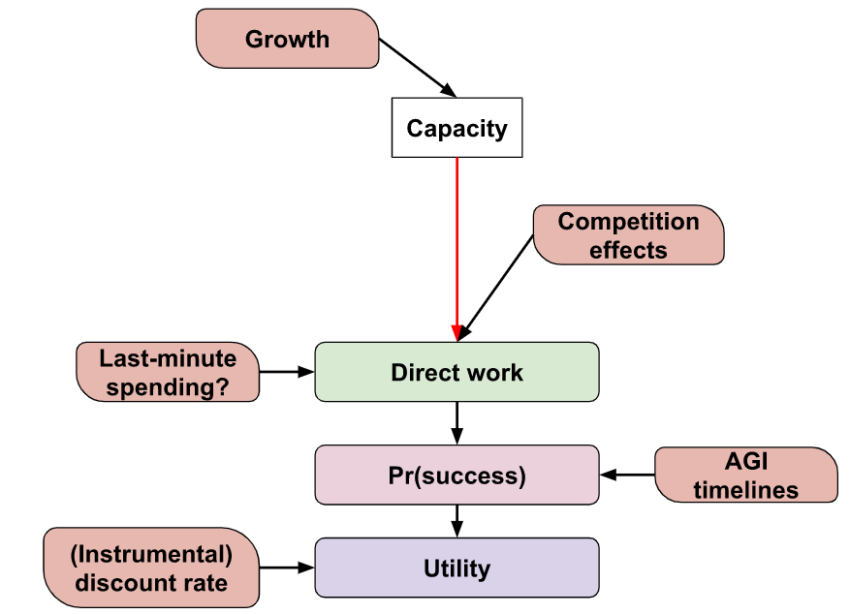





 for duration
for duration 

 , and
, and  .
. in the main model, we take
in the main model, we take  . Our 90% confidence interval is
. Our 90% confidence interval is  .
. which implies that after one
which implies that after one  of the direct work is still useful.
of the direct work is still useful. which leads to
which leads to 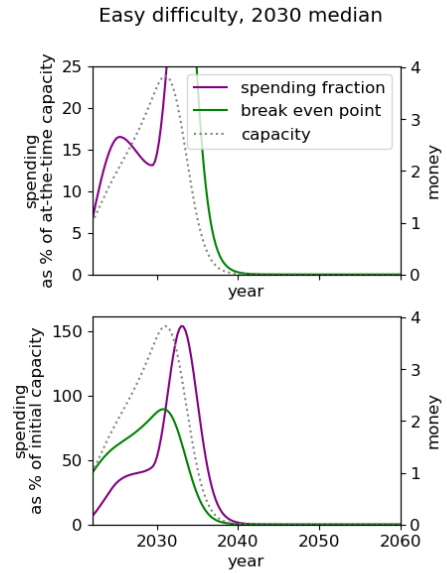
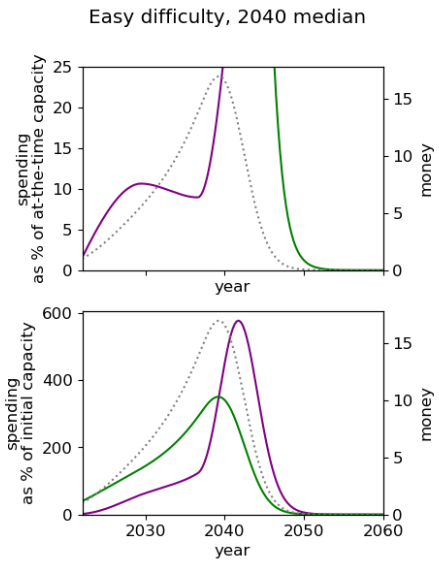
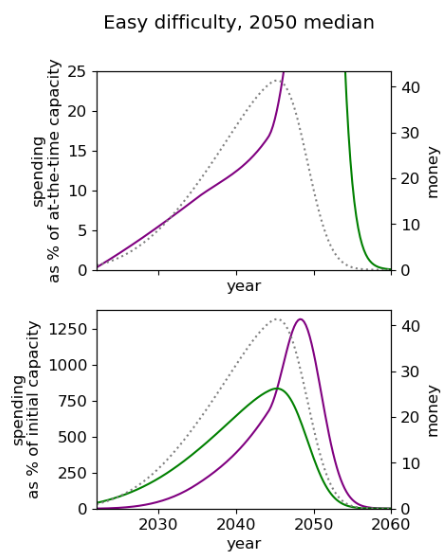
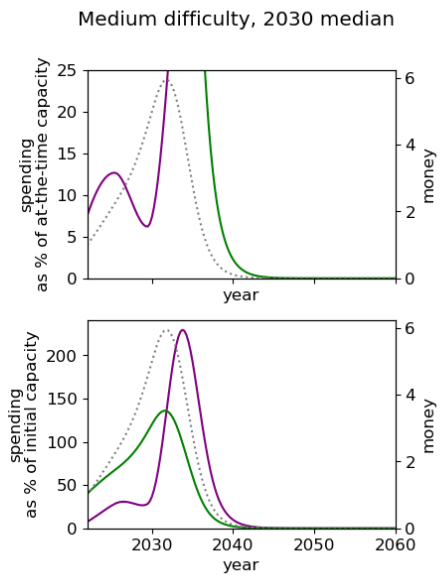
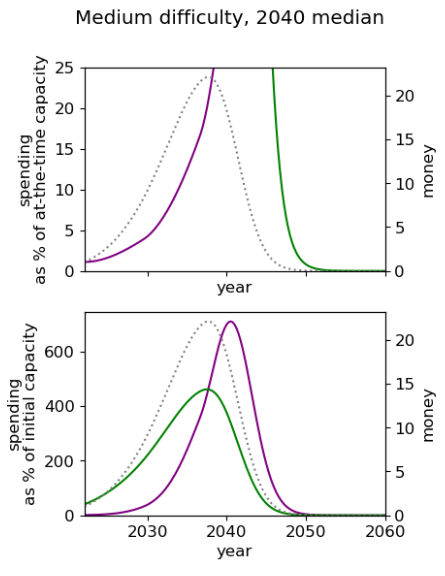
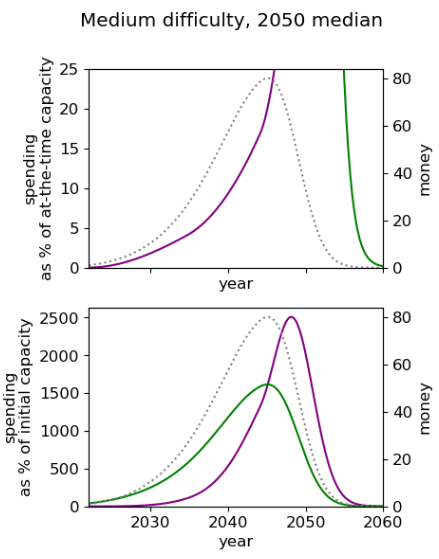
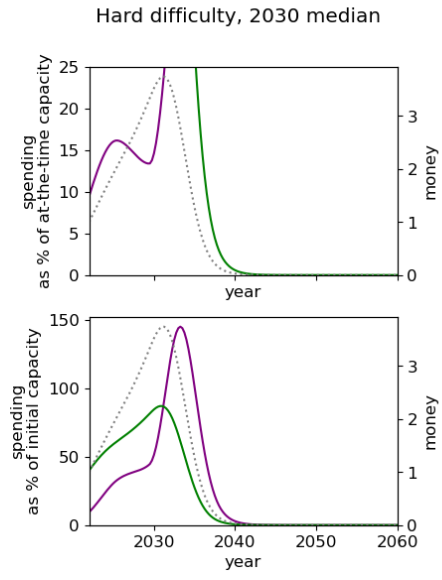
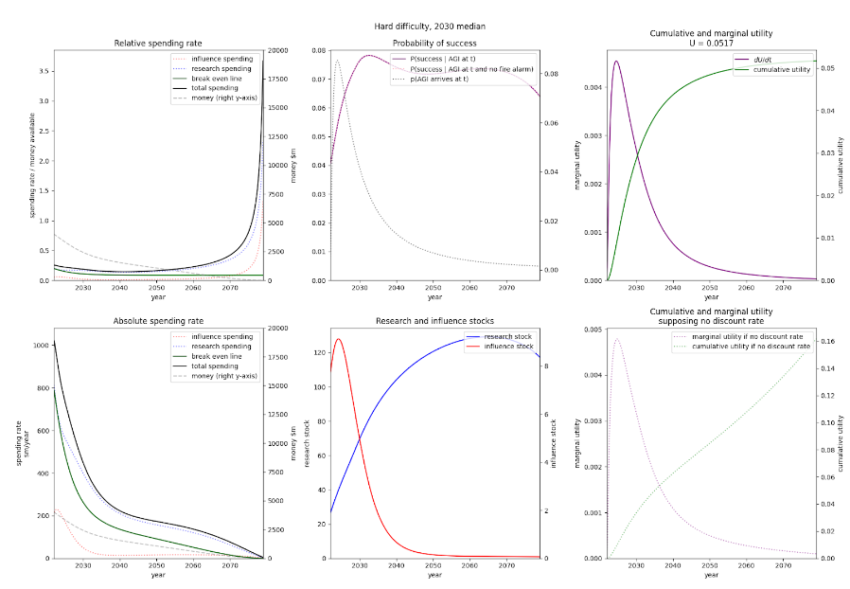
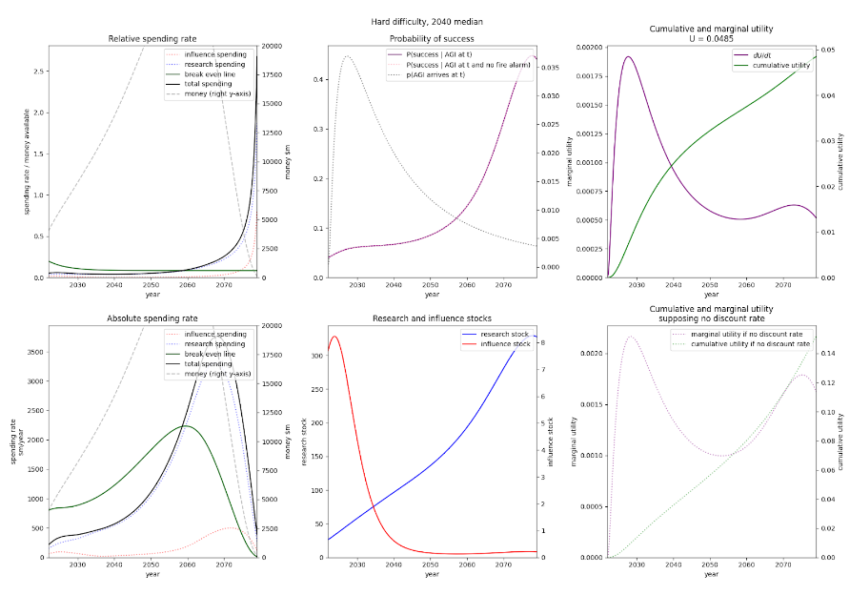
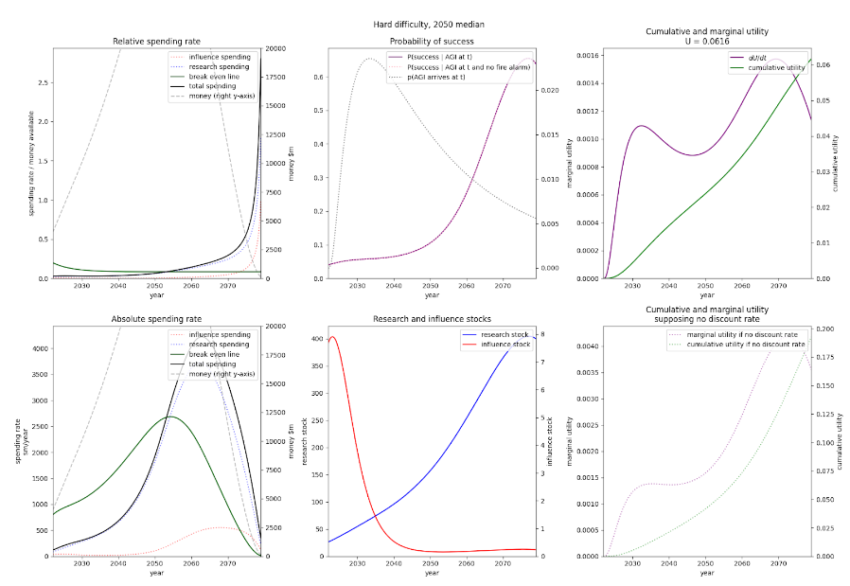
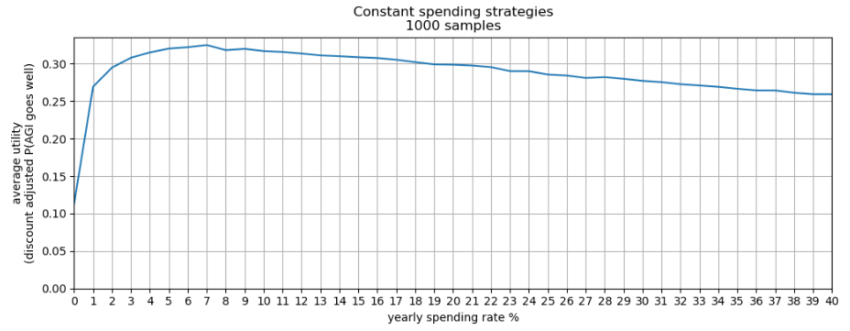
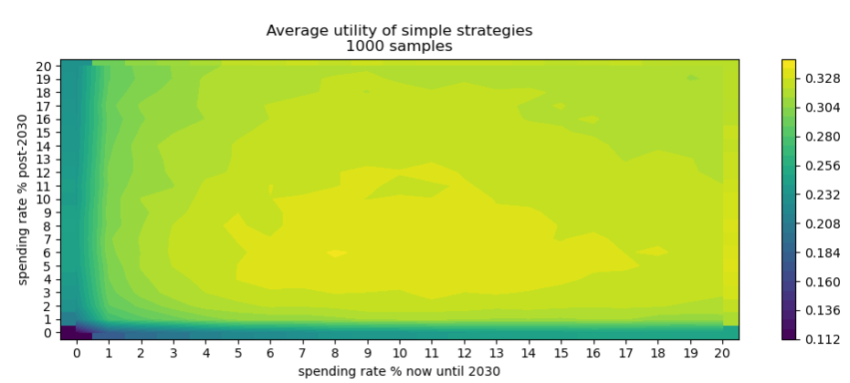
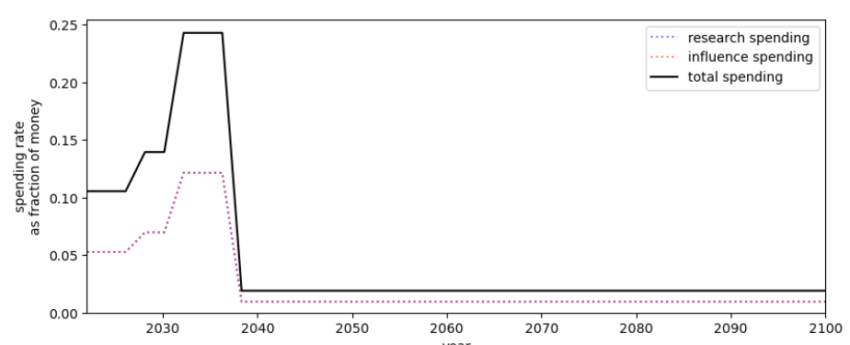
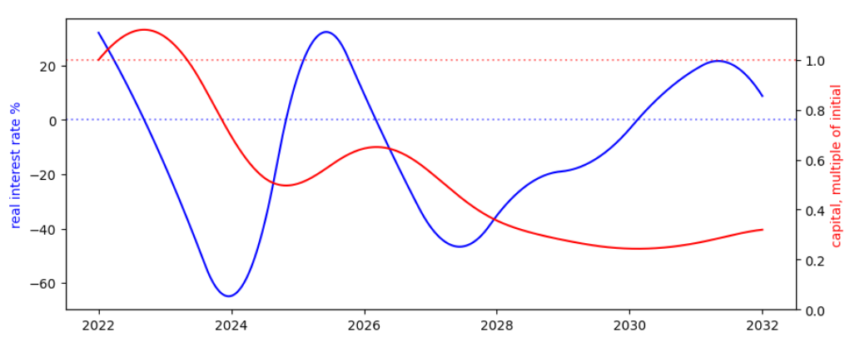
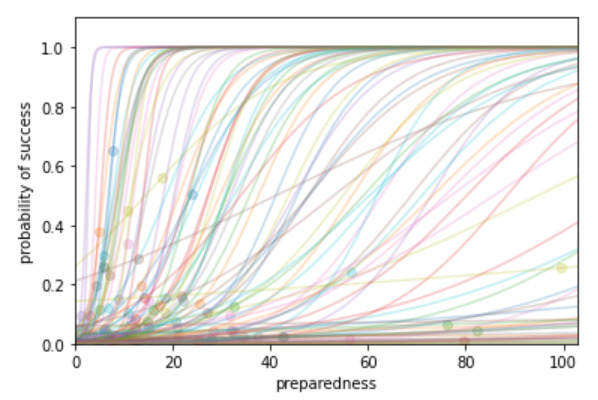
 be agent
be agent  ’s reward signal. Suppose we have reason to believe that a training process selects for spiteful agents, that is, agents who act as if optimizing for
’s reward signal. Suppose we have reason to believe that a training process selects for spiteful agents, that is, agents who act as if optimizing for  on the training distribution.
on the training distribution. for some objectives
for some objectives  correlated with
correlated with  to worry that agent 1 will learn a spiteful objective.
to worry that agent 1 will learn a spiteful objective. -order commitments are incompatible, try resolving these via an
-order commitments are incompatible, try resolving these via an  -order bargaining process.” See also
-order bargaining process.” See also 
 , where
, where  measures my military strength, such that
measures my military strength, such that  is my chance of winning a war, and
is my chance of winning a war, and  is information about secret military technology that I don’t want you to learn. A conditional commitment would be: I disclose
is information about secret military technology that I don’t want you to learn. A conditional commitment would be: I disclose 
![\[\begin{array}{ccc} \textbf{Caspar Oesterheld} & &\textbf{Vincent Conitzer}\\ \textt{Foundations of Cooperative AI Lab} & &\textt{Foundations of Cooperative AI Lab}\\ \text{Computer Science Department} & &\text{Computer Science Department}\\ \text{Carnegie Mellon University} & &\text{Carnegie Mellon University}\\ \end{array}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-8d84a7142653e77d22a52b1342a3ec90_l3.png "Rendered by QuickLaTeX.com")
 is an SPI on another game
is an SPI on another game  if and only if there is a Pareto-improving outcome correspondence relation between
if and only if there is a Pareto-improving outcome correspondence relation between  -player (normal-form) game is a tuple
-player (normal-form) game is a tuple  of a set
of a set  of (pure) strategy profiles (or outcomes) and a function
of (pure) strategy profiles (or outcomes) and a function  that assigns to each outcome a utility for each player. The Prisoner's Dilemma shown in Table 3 is a classic example of a game. The Demand Game of Table 1 is another example of a game that we will use throughout this paper.
that assigns to each outcome a utility for each player. The Prisoner's Dilemma shown in Table 3 is a classic example of a game. The Demand Game of Table 1 is another example of a game that we will use throughout this paper. . We also write
. We also write  for
for  , i.e., for the Cartesian product of the action sets of all players other than
, i.e., for the Cartesian product of the action sets of all players other than  and
and  for vectors containing utility functions and actions, respectively, for all players but
for vectors containing utility functions and actions, respectively, for all players but  is a utility function and
is a utility function and  ) we use
) we use  for the full vector of utility functions where Player
for the full vector of utility functions where Player  and
and  analogously.
analogously. strictly dominates
strictly dominates  if for all
if for all  ,
,  . For example, in the Prisoner's Dilemma, Defect strictly dominates Cooperate for both players. As noted earlier,
. For example, in the Prisoner's Dilemma, Defect strictly dominates Cooperate for both players. As noted earlier,  and
and  strictly dominate
strictly dominate  and
and  for both players.
for both players. , we will call any game
, we will call any game  a subset game of
a subset game of  for
for  . Note that a subset game may assign different utilities to outcomes than the original game. For example, the game of Table 2 is a subset game of the Demand Game.
. Note that a subset game may assign different utilities to outcomes than the original game. For example, the game of Table 2 is a subset game of the Demand Game. is a Pareto improvement on (or is Pareto-better than)
is a Pareto improvement on (or is Pareto-better than)  if
if  for
for  . Note that, contrary to convention, we allow
. Note that, contrary to convention, we allow  . Whenever we require one of the inequalities to be strict, we will say that
. Whenever we require one of the inequalities to be strict, we will say that  is a strict Pareto improvement on
is a strict Pareto improvement on  . In a given game, we will also say that an outcome
. In a given game, we will also say that an outcome  is a Pareto improvement on another outcome
is a Pareto improvement on another outcome  if
if  . We say that
. We say that  if there is no element of
if there is no element of  that strictly Pareto-dominates
that strictly Pareto-dominates  a (game) isomorphism between
a (game) isomorphism between  if there are vectors
if there are vectors  and
and  such that
such that
 and
and  is isomorphic to
is isomorphic to  with
with  and
and  and the constants
and the constants  and
and  .
.
 of the original game, without necessarily specifying a strategy or algorithm for solving such a game. We emphasize, again, that
of the original game, without necessarily specifying a strategy or algorithm for solving such a game. We emphasize, again, that  is allowed to be a vector of entirely different utility functions. For any subset game
is allowed to be a vector of entirely different utility functions. For any subset game  the outcome that arises if the representatives play the subset game
the outcome that arises if the representatives play the subset game  with certainty.
with certainty. to be a default way for the game to played for any
to be a default way for the game to played for any ![\mathbb{E}\left[\mathbf{u}(\Pi(\Gamma))\right]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-8f9f30ac557c646b83291f181c9fa6e5_l3.png "Rendered by QuickLaTeX.com") . The players could then let the representatives play a distribution over outcomes whose expected utilities exceed the default expected utilities. However, this is unrealistic if
. The players could then let the representatives play a distribution over outcomes whose expected utilities exceed the default expected utilities. However, this is unrealistic if  .
. with certainty. We say that
with certainty. We say that  with positive probability.
with positive probability. to be an SPI on
to be an SPI on ![\[\Pi(\{\mathrm{Cooperate}\},\{\mathrm{Cooperate}\},\mathbf{u})= (\mathrm{Cooperate},\mathrm{Cooperate})\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-6e58bd0b374b2a8bebb1d5c07521e531_l3.png "Rendered by QuickLaTeX.com")
 of
of  it holds that
it holds that  and
and  . Consequently, if a unilateral subset game
. Consequently, if a unilateral subset game  ) becomes more likely than the project 2 equilibrium. To address this, Player has to commit her representative to a different utility function that makes this new game isomorphic to the original game.
) becomes more likely than the project 2 equilibrium. To address this, Player has to commit her representative to a different utility function that makes this new game isomorphic to the original game. and
and  and to assign utilities
and to assign utilities  ,
,  ,
,  , and
, and  ; otherwise
; otherwise  does not differ from
does not differ from  . The resulting SPI is given in Table 5. In this subset game, Player 2's representative – knowing that Player 1's representative will only play from
. The resulting SPI is given in Table 5. In this subset game, Player 2's representative – knowing that Player 1's representative will only play from  and
and  (since
(since  and
and  in Table 5). Now notice that the remaining subset game is isomorphic to the
in Table 5). Now notice that the remaining subset game is isomorphic to the  subset game of the original Complicated Temptation Game, where
subset game of the original Complicated Temptation Game, where  maps to
maps to  maps to
maps to  ) between the two subset games. Thus, we might expect that if
) between the two subset games. Thus, we might expect that if  , then
, then  , and so on. Finally, notice that
, and so on. Finally, notice that  and so on. Hence, Table 5 is indeed an SPI on the Complicated Temptation Game.
and so on. Hence, Table 5 is indeed an SPI on the Complicated Temptation Game.
 . For example, in the Complicated Temptation Game, Player 1 could simply commit her representative to play
. For example, in the Complicated Temptation Game, Player 1 could simply commit her representative to play 
 , player
, player  are realized according to the utility function of
are realized according to the utility function of  ” in the program she submits. This instruction lets the representative choose and return an action for the game
” in the program she submits. This instruction lets the representative choose and return an action for the game  ) over outcomes according to which she will pay the representative after an outcome is obtained. Moreover, these contracts might refer to one another. For example, Player 1's contract with her representative might specify that if Player 2 and his representative use an analogous contract, then she will pay her representative according to Table 2. As a second, more futuristic scenario, you could imagine that the representatives are software agents whose goals are specified by so-called smart contracts, i.e., computer programs implemented on a blockchain to be publicly verifiable [8, 47].
) over outcomes according to which she will pay the representative after an outcome is obtained. Moreover, these contracts might refer to one another. For example, Player 1's contract with her representative might specify that if Player 2 and his representative use an analogous contract, then she will pay her representative according to Table 2. As a second, more futuristic scenario, you could imagine that the representatives are software agents whose goals are specified by so-called smart contracts, i.e., computer programs implemented on a blockchain to be publicly verifiable [8, 47]. " for any subset game
" for any subset game  and
and  , a multi-valued function
, a multi-valued function  is a function which maps each element
is a function which maps each element  to a set
to a set  . For a subset
. For a subset  , we define
, we define
 and that
and that  . For any set
. For any set  . Also, for two sets
. Also, for two sets  . We define the inverse
. We define the inverse
 for any multi-valued function
for any multi-valued function  and functions
and functions  , we define the composite
, we define the composite  . As with regular functions, composition of multi-valued functions is associative. We say that
. As with regular functions, composition of multi-valued functions is associative. We say that  for all
for all  and
and  . We write
. We write  for
for  if
if  with certainty.
with certainty. is the game that results from removing
is the game that results from removing  , where
, where  if
if  and
and  otherwise. Next, it seems plausible that
otherwise. Next, it seems plausible that  , where
, where  is the isomorphism between
is the isomorphism between  , many of which we will use throughout this paper.
, many of which we will use throughout this paper. and
and  ,
,  .
. , where
, where  .
.  .
. , then
, then  .
.  for all
for all  .
.  , where
, where  .
.  , then
, then  with certainty.
with certainty. , then
, then  with certainty.
with certainty. with certainty. Hence,
with certainty. Hence,  by definition of
by definition of  . Therefore,
. Therefore,  by definition of
by definition of 
 as claimed.
as claimed. ,
,  , both with certainty. The former (i) implies
, both with certainty. The former (i) implies  . Hence,
. Hence,
 with certainty. By definition,
with certainty. By definition,  as claimed.
as claimed.
 with certainty. By definition of
with certainty. By definition of  , it is
, it is  with certainty. Hence,
with certainty. Hence,  with certainty. We conclude that
with certainty. We conclude that  as claimed.
as claimed. . Hence,
. Hence,  with certainty. We conclude that
with certainty. We conclude that  , then by reflexivity of
, then by reflexivity of  . If
. If  if and only if there is a single-valued bijection
if and only if there is a single-valued bijection  , where
, where  on games where
on games where  if
if  be a subset game of
be a subset game of  be such that
be such that  for all
for all  .
. is an SPI on
is an SPI on  : By definition,
: By definition,  with certainty. Hence, for
with certainty. Hence, for  ,
,
 .
. : Assume that
: Assume that  with certainty for
with certainty for 
 and
and  for any
for any  , it is (by assumption) with certainty
, it is (by assumption) with certainty  as claimed.
as claimed. . To show that some
. To show that some  is the game that results from removing
is the game that results from removing  . To see that
. To see that  is Pareto-improving for the original utility functions of
is Pareto-improving for the original utility functions of  onto the outcome
onto the outcome  , which is better for both original players. Other than that,
, which is better for both original players. Other than that,  is Pareto-improving. By Theorem 3,
is Pareto-improving. By Theorem 3,  resulting from playing games. An analogous result holds for any random variables over
resulting from playing games. An analogous result holds for any random variables over  and
and  . In particular, this means that Theorem 3 applies also if the representatives receive other kinds of instructions (cf. Section
. In particular, this means that Theorem 3 applies also if the representatives receive other kinds of instructions (cf. Section  are pairwise disjoint, and let
are pairwise disjoint, and let  be strictly dominated by some other strategy in
be strictly dominated by some other strategy in  , where for all
, where for all  and
and  whenever
whenever  .
. , the representatives do not take into account how many other strategies
, the representatives do not take into account how many other strategies  , then this would mean that if the representatives play Rock in Rock–Paper–Scissors, they play Paper in Rock–Paper–Scissors. Contradiction! We will argue for the consistency of our version of the assumption in Section
, then this would mean that if the representatives play Rock in Rock–Paper–Scissors, they play Paper in Rock–Paper–Scissors. Contradiction! We will argue for the consistency of our version of the assumption in Section  if they play Rock/Paper”. Then there would only be one isomorphism between these two games (which maps Rock to Paper, Paper to Scissors, and Scissors to Rock for both players). However, in light of Assumption 1, it seems problematic to assume that these strictly dominated actions restrict the outcome correspondences between these two games.
if they play Rock/Paper”. Then there would only be one isomorphism between these two games (which maps Rock to Paper, Paper to Scissors, and Scissors to Rock for both players). However, in light of Assumption 1, it seems problematic to assume that these strictly dominated actions restrict the outcome correspondences between these two games. by Assumption 2, even if there are multiple isomorphisms between
by Assumption 2, even if there are multiple isomorphisms between  . They then look up the unique game in the book that is isomorphic to
. They then look up the unique game in the book that is isomorphic to  are fully reduced and isomorphic. Then it is easy to see that each player
are fully reduced and isomorphic. Then it is easy to see that each player  . Let
. Let  and
and  be the bijections used by the representatives to translate actions in
be the bijections used by the representatives to translate actions in  are the ones specified by the book for
are the ones specified by the book for  are played in
are played in  . It is easy to see that
. It is easy to see that  is a game isomorphism between
is a game isomorphism between  such that by iterated removal of weakly dominated strategies from
such that by iterated removal of weakly dominated strategies from  and
and  . If we had an assumption analogous to Assumption 1 but for weak dominance, then (with Lemma 2.3 – transitivity), we would obtain both that
. If we had an assumption analogous to Assumption 1 but for weak dominance, then (with Lemma 2.3 – transitivity), we would obtain both that  and that
and that  , where
, where  for all
for all  and
and  for all
for all  . The former would mean (by Lemma 2.6) that for all
. The former would mean (by Lemma 2.6) that for all  by definition. Thus, we cannot make an assumption analogous to Assumption 1 for weak dominance.
by definition. Thus, we cannot make an assumption analogous to Assumption 1 for weak dominance. can be eliminated to obtain a strategically equivalent game, but in the original game
can be eliminated to obtain a strategically equivalent game, but in the original game  and that there are no other strategies that are similarly payoff-equivalent to
and that there are no other strategies that are similarly payoff-equivalent to  . Then one would assume that
. Then one would assume that  , where
, where  and otherwise
and otherwise  that results in the same payoffs as
that results in the same payoffs as  be any subset game of
be any subset game of  . Then under Assumption 1,
. Then under Assumption 1,  , where
, where  and
and  and
and  . By Lemma 2.5, we further obtain
. By Lemma 2.5, we further obtain  , where
, where  is as described in the proposition. Hence, by transitivity,
is as described in the proposition. Hence, by transitivity,  . It is easy to verify that the function
. It is easy to verify that the function  is Pareto-improving.
is Pareto-improving. , then
, then  . We can repeatedly apply Assumption 1 to eliminate from
. We can repeatedly apply Assumption 1 to eliminate from  , where
, where  and
and
 , where
, where  and
and  for
for  . It is easy to verify that for all
. It is easy to verify that for all  , it is for all
, it is for all  the case that
the case that  .
. (for Temptation) strictly dominates
(for Temptation) strictly dominates  . Hence, this game is strict-dominance solvable to
. Hence, this game is strict-dominance solvable to  . Player 1 can safely Pareto-improve on this result by telling her representative to play
. Player 1 can safely Pareto-improve on this result by telling her representative to play  and
and  . We now show this formally.
. We now show this formally.
 be the game of Table 6. Under Assumption 1,
be the game of Table 6. Under Assumption 1,  is a strict SPI on
is a strict SPI on  and
and  and
and  .
. , where
, where  and
and  and
and  .
. by Lemma 2.5, where
by Lemma 2.5, where  .
. , where
, where  . It is easy to verify that
. It is easy to verify that  and
and  . Hence,
. Hence,  is Pareto-improving and so by Theorem 3,
is Pareto-improving and so by Theorem 3,  .
. and
and  and
and
 and
and
 by Assumption 2, where
by Assumption 2, where  and
and  , corresponding to the two players, respectively, where
, corresponding to the two players, respectively, where  and
and  for
for  . It is easy to verify that
. It is easy to verify that  is Pareto-improving.
is Pareto-improving. and a sequence of subset games
and a sequence of subset games  of
of  ,
,  is valid by a single application of either Assumption 1 or Assumption 1, or an application of Assumption 1 in reverse via Lemma 2.2.
is valid by a single application of either Assumption 1 or Assumption 1, or an application of Assumption 1 in reverse via Lemma 2.2.  , it is the case that
, it is the case that  .
. .
. and
and  .
. that can be reduced (via iterative application of Assumption 1) to a game
that can be reduced (via iterative application of Assumption 1) to a game  , the (strict) (unilateral) SPI decision problem can be solved in
, the (strict) (unilateral) SPI decision problem can be solved in  .
. -complete) if we treat games in a weighted boolean formula representation. In fact, even reducing a game using strict dominance by pure strategies – which contributes only insignificantly to the complexity of the SPI problem for normal-form games – is difficult in some game representations [10, Section 6]. Note, however, that for any game representation to which 2-player normal-form games can be efficiently reduced – such as, for example, extensive-form games – the hardness result also applies.
-complete) if we treat games in a weighted boolean formula representation. In fact, even reducing a game using strict dominance by pure strategies – which contributes only insignificantly to the complexity of the SPI problem for normal-form games – is difficult in some game representations [10, Section 6]. Note, however, that for any game representation to which 2-player normal-form games can be efficiently reduced – such as, for example, extensive-form games – the hardness result also applies.![\begin{equation*} \mathcal{C}(\Gamma)\coloneqq \mathbf{u}(\Delta(A)) =\left\{ \sum_{\mathbf{a}\in A} p_{\mathbf{a}} {\mathbf{u}} (\mathbf{a}) \;\middle|\; \sum_{\mathbf{a}\in A} p_{\mathbf{a}} =1 \text{ and } \forall \mathbf{a}\in A\colon p_{\mathbf{a}}\in [0,1] \right\} \end{equation*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-e789b82ff3e391a90daf37858ee779ca_l3.png "Rendered by QuickLaTeX.com")
 is exactly the convex closure of
is exactly the convex closure of  , i.e., the convex closure of the set of deterministically achievable utilities of the original game.
, i.e., the convex closure of the set of deterministically achievable utilities of the original game. , where for all
, where for all  and
and  are arbitrary utility functions to be used by the representatives and
are arbitrary utility functions to be used by the representatives and  are the utilities that the original players assign to the token strategies.
are the utilities that the original players assign to the token strategies. as usual. However, the strategies
as usual. However, the strategies  are selected, these are translated into some probability distribution over
are selected, these are translated into some probability distribution over  . These distributions and thus utilities are specified by the original players.
. These distributions and thus utilities are specified by the original players. with certainty. We call
with certainty. We call  with positive probability.
with positive probability. , randomize [according to some given distribution] between the other (Pareto-optimal) outcomes instead”. Formally,
, randomize [according to some given distribution] between the other (Pareto-optimal) outcomes instead”. Formally,  and
and  would then consist of tokenized versions of the original strategies. The utility functions
would then consist of tokenized versions of the original strategies. The utility functions  are then simply the same as in the original Demand Game except that they are applied to the token strategies. For example,
are then simply the same as in the original Demand Game except that they are applied to the token strategies. For example,  . The utilities for the original players remove the conflict outcome. For example, the original players might specify
. The utilities for the original players remove the conflict outcome. For example, the original players might specify  , representing that the representatives are supposed to play
, representing that the representatives are supposed to play  in the
in the  case. For all other outcomes
case. For all other outcomes  , it must be the case that
, it must be the case that  because the other outcomes cannot be Pareto-improved upon. As with our earlier SPIs for the Demand Game, Assumption 2 implies that
because the other outcomes cannot be Pareto-improved upon. As with our earlier SPIs for the Demand Game, Assumption 2 implies that  , where
, where  ,
,![\begin{align*} \text{Variables:}\quad & p_{\mathbf{a}}\in [0,1] \textup{ for all }\mathbf{a}\in A\\ \textup{Maximize}\quad & \sum_{i=1}^n \left(\sum_{\mathbf{a}\in A} p_{\mathbf{a}} u_i(\mathbf{a}) \right) - y_i \\ \textup{s.t.}\quad & \sum_{\mathbf{a}\in A} p_{\mathbf{a}}=1\\ & \sum_{\mathbf{a}\in A} p_{\mathbf{a}} u_i(\mathbf{a}) \geq y_i \textup{ for }i=1,...,n \end{align*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-dcd87aa6871cc1da64d5099780f507ba_l3.png "Rendered by QuickLaTeX.com")

 is known and that Assumption 2 holds, it can be decided in polynomial time whether there is a strict perfect-coordination SPI.
is known and that Assumption 2 holds, it can be decided in polynomial time whether there is a strict perfect-coordination SPI. ) at least one of the outcomes. It turns out that we can restrict attention to this very simple type of SPI under improved coordination.
) at least one of the outcomes. It turns out that we can restrict attention to this very simple type of SPI under improved coordination. be any game. Let
be any game. Let  with values in
with values in 
![\begin{equation*}(\Pi(\Gamma^s)) \;\middle|\; \Pi(\Gamma){=}\mathbf{a} \right] = \mathbb{E}\left[ {\mathbf{u}}(\Pi(\Gamma')) \;\middle|\; \Pi(\Gamma){=}\mathbf{a} \right]\end{equation*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-83e867b30cc95a6fb3d0941ef32cc47b_l3.png "Rendered by QuickLaTeX.com")
![\mathbb{E}\left[ {\mathbf{u}}(\Pi(\Gamma^s)) \right] = \mathbb{E}\left[ {\mathbf{u}}(\Pi(\Gamma')) \right]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-c922d26c8679683762e1a30691315245_l3.png "Rendered by QuickLaTeX.com") .
. is isomorphic to
is isomorphic to  . WLOG assume that
. WLOG assume that  . Then define
. Then define ![\begin{equation*} \mathbf{u}^e(\hat a_1^{i_1},...,\hat a_n^{i_n})=\mathbb{E}\left[ {\mathbf{u}}' (\Pi(\Gamma')) \mid \Pi(\Gamma)=( a_1^{i_1},...,a_n^{i_n}) \right]. \end{equation*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-145cb0307701294ea8b508e1bd726332_l3.png "Rendered by QuickLaTeX.com")
 describes the utilities that the original players assign to the outcomes of
describes the utilities that the original players assign to the outcomes of  it is by assumption
it is by assumption  with certainty. Hence,
with certainty. Hence,![\begin{eqnarray*} u^e(\hat a_1^{i_1},...,\hat a_n^{i_n}))&=&\mathbb{E}\left[ \mathbf{u}' (\Pi(\Gamma')) \mid \Pi(\Gamma)=( a_1^{i_1},...,a_n^{i_n}) \right]\\ &\geq& {\mathbf{u}}( a_1^{i_1},...,a_n^{i_n}), \end{eqnarray*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-4dc538d69d1cb4845423012b2f2ff289_l3.png "Rendered by QuickLaTeX.com")
 , the original players will in general not be able to construct a
, the original players will in general not be able to construct a ![\begin{equation*}\{ \mathbb{E}[ {\mathbf{u}}(\Gamma') ]\mid \Gamma'\text{ is perfect-coordination SPI on }\Gamma \}\end{equation*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-7c5dc829e19afd611e44744740ee9a18_l3.png "Rendered by QuickLaTeX.com")

 (or more generally convex, closed set). For any real number
(or more generally convex, closed set). For any real number  , we use
, we use  to denote the
to denote the  which maximizes
which maximizes  under the constraint
under the constraint  (Recall that we consider 2-player games, so
(Recall that we consider 2-player games, so  exists if and only if
exists if and only if  be some potentially unsafe Pareto improvement on
be some potentially unsafe Pareto improvement on ![\mathbb{E}\left[{\mathbf{u}}(\Pi(\Gamma)) \right]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-031208451e727fd9197e3e3425e9162d_l3.png "Rendered by QuickLaTeX.com") . For
. For  . Then:
. Then: is Pareto-dominated by an element of at least one of the following three sets:
is Pareto-dominated by an element of at least one of the following three sets: the line segment between
the line segment between  and
and  ;
; the segment of the curve
the segment of the curve  between
between  and
and  ;
; the line segment between
the line segment between  and
and  .
.![\mathbb{E}\left[{\mathbf{u}}(\Pi(\Gamma^s)) \right]={\mathbf{y}}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-bbf221ed11a04794757ad70f2f40fa34_l3.png "Rendered by QuickLaTeX.com") .
. and
and  as defined above, then there is a perfect-coordination SPI
as defined above, then there is a perfect-coordination SPI ![\mathbb{E}\left[ {\mathbf{u}} (\Pi(\Gamma)) \right]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-f03b7b35544ff43b6f31852974ee2ffd_l3.png "Rendered by QuickLaTeX.com") . The vertical dashed lines starting at the two extreme x marks illustrate the application of
. The vertical dashed lines starting at the two extreme x marks illustrate the application of  to project
to project  onto the Pareto frontier. The dotted line between these two points is
onto the Pareto frontier. The dotted line between these two points is  to project
to project  onto the Pareto frontier. The line segment between these two points is
onto the Pareto frontier. The line segment between these two points is  is simply that part of the Pareto frontier, which Pareto-dominates all elements of
is simply that part of the Pareto frontier, which Pareto-dominates all elements of 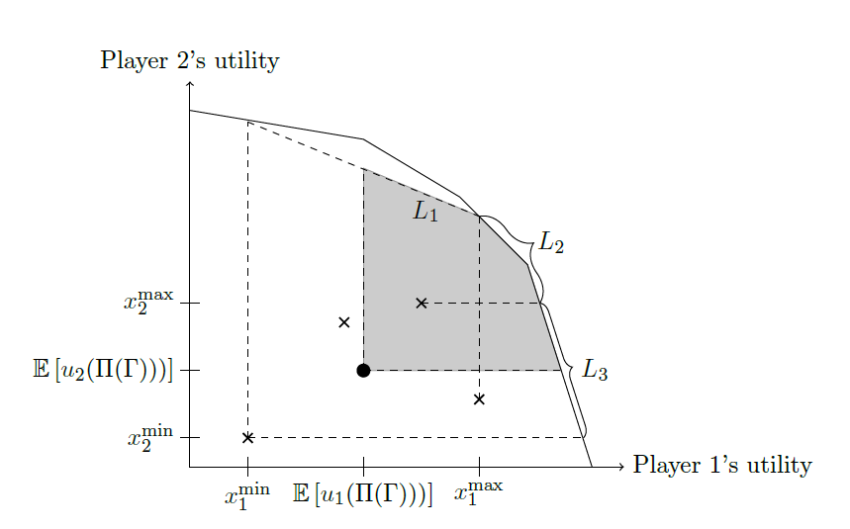
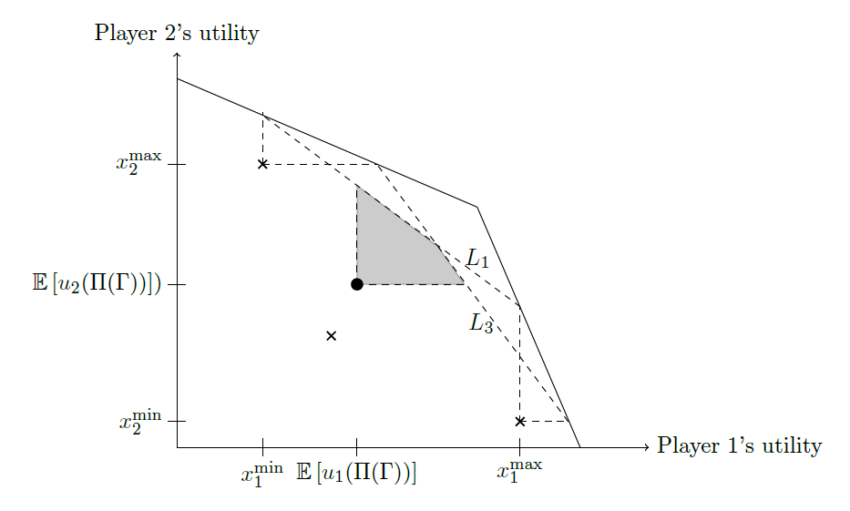
 that Pareto-improves on all outcomes of the original game can be obtained by re-mapping all outcomes onto
that Pareto-improves on all outcomes of the original game can be obtained by re-mapping all outcomes onto ![u_i(\mathbf{a})>\mathbb{E}\left[ u_i(\Pi(\Gamma)) \right]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-b9e0b483fb13268b44819fbcaf364219_l3.png "Rendered by QuickLaTeX.com") for all players
for all players ![\mathbb{E}\left[ u^e_i(\Pi(A^s,\mathbf{u}^s)) \right] = u_i(\mathbf{a})](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-6d5df814c1ab58625344a50bc87c468a_l3.png "Rendered by QuickLaTeX.com") .
. can be eliminated by strict dominance (Assumption 1) for both players, leaving a typical Chicken-like payoff structure with two pure Nash equilibria (
can be eliminated by strict dominance (Assumption 1) for both players, leaving a typical Chicken-like payoff structure with two pure Nash equilibria ( and
and  ), as well as a mixed Nash equilibrium
), as well as a mixed Nash equilibrium  .
.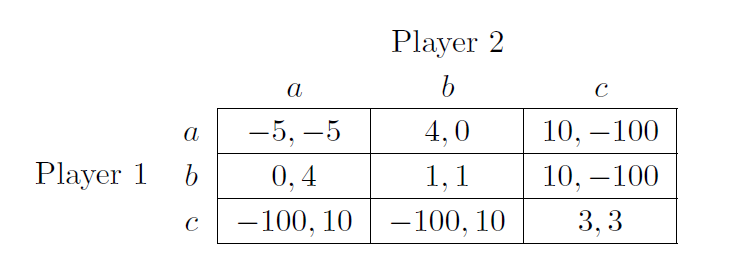
 for some
for some  with
with  . Then one (unsafe) Pareto improvement would be to simply always have the representatives play
. Then one (unsafe) Pareto improvement would be to simply always have the representatives play  for a certain payoff of
for a certain payoff of  . Unfortunately, there is no safe Pareto improvement with the same expected payoff. Notice that
. Unfortunately, there is no safe Pareto improvement with the same expected payoff. Notice that ![\mathbb{E}\left[{\mathbf{u}}(\Pi(\Gamma ^s)) \right]=(3,3)](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-89882d1445fbc795b5a8f1fa9064dd04_l3.png "Rendered by QuickLaTeX.com") , it must be
, it must be  with certainty. Unfortunately, in any safe Pareto improvement the outcomes
with certainty. Unfortunately, in any safe Pareto improvement the outcomes  and
and  , respectively, because these are Pareto-optimal within the set of feasible payoff vectors. We illustrate this as an example of Case B of Theorem 15 in Figure 4.
, respectively, because these are Pareto-optimal within the set of feasible payoff vectors. We illustrate this as an example of Case B of Theorem 15 in Figure 4.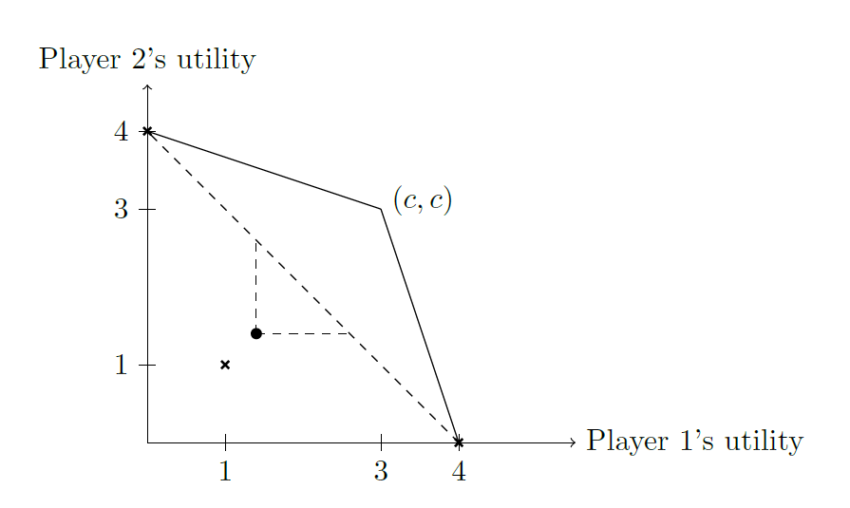
 , which is like
, which is like  , Aliceland can peacefully annex the desert. Aliceland prefers this SPI over the original one, while Bobbesia has the opposite preference. In other cases, it may be unclear to some or all of the players which of two SPIs they prefer. For example, imagine a version of the Demand Game in which one SPI mostly improves on
, Aliceland can peacefully annex the desert. Aliceland prefers this SPI over the original one, while Bobbesia has the opposite preference. In other cases, it may be unclear to some or all of the players which of two SPIs they prefer. For example, imagine a version of the Demand Game in which one SPI mostly improves on  and a non-deterministic mapping
and a non-deterministic mapping  . We obtain a new game with action sets
. We obtain a new game with action sets  and utility function
and utility function![\begin{equation*} U\colon \mathrm{PROG}\rightarrow \mathbb{R}^n\colon \mathbf{c} \mapsto \mathbb{E}\left[ \mathbf{u}(\mathit{exec}(\mathbf{c})) \right]. \end{equation*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-831b89024d7482153f988907de230d5b_l3.png "Rendered by QuickLaTeX.com")
 consists of computer programs in some programming language, such as Lisp, that take as input vectors in
consists of computer programs in some programming language, such as Lisp, that take as input vectors in  on input
on input  then executes each player
then executes each player  on
on  to assign
to assign  and
and  .
. as
as
 to denote the strategy for Player
to denote the strategy for Player  that is played in the minimizer
that is played in the minimizer  of the above. Of course, in general, there might be multiple minimizers
of the above. Of course, in general, there might be multiple minimizers  breaks such ties in some consistent way, such that for all
breaks such ties in some consistent way, such that for all 
 , each player's threat point is computable in polynomial time via linear programming; and that by the minimax theorem [35], the threat point is equal to the maximin utility, i.e.,
, each player's threat point is computable in polynomial time via linear programming; and that by the minimax theorem [35], the threat point is equal to the maximin utility, i.e.,
 be a (feasible) payoff vector. If
be a (feasible) payoff vector. If  for
for  is the utility of some program equilibrium of a program game on
is the utility of some program equilibrium of a program game on 
 regardless of Player
regardless of Player  's instruction, then Player
's instruction, then Player  rather than
rather than  if the other player's representative does the same. It would then seem that in a program equilibrium in which
if the other player's representative does the same. It would then seem that in a program equilibrium in which  against me, I also play as I would in
against me, I also play as I would in  -grounded mutual simulation [36] or even (meta) Assurance Game preferences (see Appendix
-grounded mutual simulation [36] or even (meta) Assurance Game preferences (see Appendix  are the same, except for the player index used”.
are the same, except for the player index used”.
 .
. . It is left to show that
. It is left to show that  . We need to show that
. We need to show that ![\mathbb{E}\left[ u_i(\mathit{exec}(\mathbf{c}_{-i},c_i')) \right] \leq \mathbb{E}\left[ u_i(\mathit{exec}(\mathbf{c})) \right]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-832e89c5eee02b20de7f3f1979b78f1e_l3.png "Rendered by QuickLaTeX.com") . Again, by inspection of
. Again, by inspection of  is the threat point of Player
is the threat point of Player ![\begin{eqnarray*} \mathbb{E}\left[ u_i(\mathit{exec}(\mathbf{c}_{-i},c_i')) \right] &=& v_i\\ &\leq& \mathbb{E}\left[ u_i(\Pi(\Gamma)) \right]\\ &\leq& \mathbb{E}\left[ u_i(\Pi(\Gamma^s)) \right]\\ &=& \mathbb{E}\left[ u_i(\mathit{exec}(\mathbf{c})) \right] \end{eqnarray*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-218b946653d4a40e7c0abea1a06f26f5_l3.png "Rendered by QuickLaTeX.com")
 , where
, where  , the representatives then play the game
, the representatives then play the game  . In particular, each representative can see what utility functions all the other representatives have been instructed to maximize. However, what utility function representative
. In particular, each representative can see what utility functions all the other representatives have been instructed to maximize. However, what utility function representative 
 and
and  . For each player
. For each player  and
and  be the lowest and highest utilities, respectively, in
be the lowest and highest utilities, respectively, in  and
and  be the lowest and highest utilities, respectively, in
be the lowest and highest utilities, respectively, in  and
and  are to be the constants for
are to be the constants for 
 , this system of linear equations has a unique solution. By the same pair of equations, the constants for
, this system of linear equations has a unique solution. By the same pair of equations, the constants for 
 , then by bijectivity of
, then by bijectivity of  , there is
, there is  . For this
. For this  .
. be the strategy that strictly dominates
be the strategy that strictly dominates 


 by Assumption 1, where
by Assumption 1, where  by Assumption 1. Then either
by Assumption 1. Then either  or there is a game
or there is a game  by Assumption 1 and
by Assumption 1 and  by Assumption 1.
by Assumption 1. and
and  , respectively. If
, respectively. If  , then
, then  . So for the rest of this proof assume
. So for the rest of this proof assume  . Let
. Let  , i.e., that
, i.e., that 
 with
with  and
and  ,
,  and
and  such that
such that
 and
and  are fully reduced games such that
are fully reduced games such that  by a single application of Assumption 2, and
by a single application of Assumption 2, and
 and
and  such that:
such that: , ...,
, ...,  is by applying Assumption 1 with or without Lemma 2.2.
is by applying Assumption 1 with or without Lemma 2.2. or the correspondence
or the correspondence  is by Assumption 2.
is by Assumption 2. or the correspondence
or the correspondence  is by Assumption 2.
is by Assumption 2. contains no strictly dominated actions (by stipulation of Assumption 2). Hence all but the first period cannot contain any non-reversed elimination steps. Similarly, in all but the final period,
contains no strictly dominated actions (by stipulation of Assumption 2). Hence all but the first period cannot contain any non-reversed elimination steps. Similarly, in all but the final period,  contains no strictly dominated actions. Hence, in all but the final period, there can be no reversed applications of Assumption 1.
contains no strictly dominated actions. Hence, in all but the final period, there can be no reversed applications of Assumption 1. , where each outcome correspondence is due to a single application of Assumption 1, Assumption 1 plus symmetry (Lemma 2.2) or Assumption 2. Let
, where each outcome correspondence is due to a single application of Assumption 1, Assumption 1 plus symmetry (Lemma 2.2) or Assumption 2. Let  all be subset games of
all be subset games of  . Moreover, let
. Moreover, let  be Pareto improving. Then there is a sequence of subset games
be Pareto improving. Then there is a sequence of subset games  such that
such that  all by applications of Assumption 1 (without applying symmetry), and
all by applications of Assumption 1 (without applying symmetry), and  by application of Assumption 2 such that
by application of Assumption 2 such that  is Pareto improving.
is Pareto improving. . Then non-deterministically select injections
. Then non-deterministically select injections  . If
. If  is (strictly) Pareto-improving (as required in Theorem 3), return True with the solution
is (strictly) Pareto-improving (as required in Theorem 3), return True with the solution  . The utility functions are
. The utility functions are
 via applying Assumption 1 iteratively to obtain a fully reduced
via applying Assumption 1 iteratively to obtain a fully reduced  via a single application of Assumption 2. By construction, our algorithm finds (guesses) this Pareto-improving outcome correspondence.
via a single application of Assumption 2. By construction, our algorithm finds (guesses) this Pareto-improving outcome correspondence. but polynomial in everything else. Hence, by implementing our algorithm deterministically, we obtain the following positive result.
but polynomial in everything else. Hence, by implementing our algorithm deterministically, we obtain the following positive result. . The resulting candidate SPI game then is
. The resulting candidate SPI game then is
 for all
for all  , and
, and  is arbitrary for
is arbitrary for  . Return True if the following conditions are satisfied:
. Return True if the following conditions are satisfied: ).
). , there are
, there are  and
and  such that for all
such that for all  , we have
, we have  .
. .
. for some
for some  by application of Assumption 2. Finally,
by application of Assumption 2. Finally,  for some
for some  . We can assume that
. We can assume that  for any
for any  , where
, where  and
and  . We call
. We call  for
for  to be meaningless.
to be meaningless. ,
, a subgraph isomorphism from
a subgraph isomorphism from  to
to  is an injection
is an injection  such that for all
such that for all 

 in
in  ) nodes and some edges from
) nodes and some edges from  , the subgraph isomorphism problem consists in deciding whether there is a subgraph isomorphism
, the subgraph isomorphism problem consists in deciding whether there is a subgraph isomorphism  between
between  be graphs. Without loss of generality assume both graphs have at least
be graphs. Without loss of generality assume both graphs have at least  vertices, i.e., that
vertices, i.e., that  . For this proof, we define
. For this proof, we define ![[i]\coloneqq \{1,...,i\}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-e743dce795792ec98091791689db9614_l3.png "Rendered by QuickLaTeX.com") for any
for any  .
. . Then we let
. Then we let ![A_1=A_2=[2n+2]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-8051a5f0c75434c75fff34676f96630f_l3.png "Rendered by QuickLaTeX.com") . The utility functions are defined via
. The utility functions are defined via![\begin{equation*} u_1(i,j) = \left\{\begin{array}{cl} 2, & \text{if } i=j\text{ and }i,j\in[n]\\ a(i,j), & \text{if }i\neq j \text{ and }i,j\in[n]\\ -1, & \text{if } i\in \{ n+1,...,2n\},j\in[n]\text{ and }i\neq j+n \\ -1, & \text{if } i\in [n],j\in\{n+1,...,2n\}\text{ and }i+n\neq j \\ 4+(n+i)\epsilon & \text{if } i\in [n]\text{ and }j=i+n \\ 4+j\epsilon & \text{if } j\in[n]\text{ and }i= j+n \\ -1 & \text{if } i,j\in \{ n+1,...,2n\}\\ 3 & \text{if }i\in \{ 2n+1,2n+2\}\text{ and }j\in [2n]\\ 6 & \text{if }i=j=2n+1\\ \epsilon & \text{if }j\in\{2n+1,2n+2\} \text{ and not }i=j=2n+1 \end{array}\right. \end{equation*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-45cf1d997f7ac95e4a49aed1e927f2c9_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} u_2(i,j) = \left\{\begin{array}{cl} 2, & \text{if } i=j\text{ and }i,j\in[n]\\ 1, & \text{if }i\neq j \text{ and }i,j\in[n]\\ -1, & \text{if } i\in \{ n+1,...,2n\},j\in[n]\text{ and }i\neq j+n \\ -1, & \text{if } i\in [n],j\in\{n+1,...,2n\}\text{ and }i+n\neq j \\ 4 & \text{if } i\in [n]\text{ and }j=i+n \\ 4 & \text{if } j\in[n]\text{ and }i= j+n \\ -1 & \text{if } i,j\in \{ n+1,...,2n\}\\ 3 & \text{if }j\in \{ 2n+1,2n+2\}\text{ and }i\in [2n]\\ 6 & \text{if }i=j=2n+2\\ \epsilon & \text{if }i\in\{2n+1,2n+2\} \text{ and not }i=j=2n+2 \end{array}\right.. \end{equation*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-42bfb66f86c3ad43080e0bd3cae11342_l3.png "Rendered by QuickLaTeX.com")
 analogously, except that in Player 1's utilities we use
analogously, except that in Player 1's utilities we use  instead of
instead of  ,
,  instead of
instead of  ,
,  instead of
instead of  and
and  .
.
 as constructed from
as constructed from  from
from ![\begin{eqnarray*} A^{\Gamma} &=&(\{ T \} \times [2n+2])\times (\{ D \} \times [2n+2] )\\ A^{\hat\Gamma}&=&(\{ R \} \times [2\hat n +2])\times (\{ P \} \times [2\hat n + 2]), \end{eqnarray*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-6a62516603ecac8bf95283cea63376f3_l3.png "Rendered by QuickLaTeX.com")
 and
and  . For
. For ![i,j\in [2n+2]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-0bba9e4df527096ab9ee1101fc9f967b_l3.png "Rendered by QuickLaTeX.com") , let
, let  be the utility of
be the utility of  in
in ![i,j\in [2\hat n+2]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-4dda32b5cb58674d742bf6a06c9e6e78_l3.png "Rendered by QuickLaTeX.com") let
let  be the utility of
be the utility of  for all
for all ![i\in [2\hat n+2]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-72bf1682bc2ca0f009636a544eb9fc0f_l3.png "Rendered by QuickLaTeX.com") and all
and all ![j\in [2n+2]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-d2760a3b788d646936662cd73db1d8bf_l3.png "Rendered by QuickLaTeX.com") ; and
; and  for all
for all ![i\in [2 n+2]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-f68248438b7877e73cb2d13cbf3c086c_l3.png "Rendered by QuickLaTeX.com") and all
and all ![j\in [2\hat n+2]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-ef8687ad029d0493299dce949b193aab_l3.png "Rendered by QuickLaTeX.com") .
. , which will later form our isomorphism. For all
, which will later form our isomorphism. For all ![i\in [n]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-92b4879035e0974d4894e3dd1e2a9d1e_l3.png "Rendered by QuickLaTeX.com") and
and  , we define
, we define  via
via
 and so on analogously.
and so on analogously. and
and  , where
, where  and
and  are the action sets of
are the action sets of 
 (as restricted to
(as restricted to  ).
). is a bijection between
is a bijection between  . Moreover,
. Moreover,
 . Again, this is done by distinguishing a large number of cases of action profiles
. Again, this is done by distinguishing a large number of cases of action profiles  for
for ![i,j\in [n]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-75affa89c515293018c1a74e5a6a04fd_l3.png "Rendered by QuickLaTeX.com") with
with  because this is where we use the fact that
because this is where we use the fact that 
 of
of  , where we set
, where we set  arbitrarily for
arbitrarily for  .
.![a_2\in D\times [2n+2]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-1331919ea803069b87bda1a9f90d1d7a_l3.png "Rendered by QuickLaTeX.com") , then
, then  is strictly dominated by
is strictly dominated by  and by
and by  .
. for some
for some  , then by assumption that
, then by assumption that  and by construction of
and by construction of  . From this and inspecting Table 9 we see that
. From this and inspecting Table 9 we see that  strictly dominate
strictly dominate  .
. for some
for some  . From this and inspecting Table 9 we see that
. From this and inspecting Table 9 we see that  .
. are both in
are both in  that are jointly Pareto-improving from the reduced game
that are jointly Pareto-improving from the reduced game  . Define
. Define ![A^{\Gamma,[n]}=(\{ T \} \times [n])\times (\{ D \} \times [n])](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-aded2668e72489d04ae63cec801d681c_l3.png "Rendered by QuickLaTeX.com") and
and ![A^{\hat\Gamma,[\hat n]}=(\{ R \} \times [\hat n])\times (\{ P \} \times [\hat n])](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-6ad317516d0c9eea1f08d123c8826151_l3.png "Rendered by QuickLaTeX.com") .
. of the reduced game s.t.
of the reduced game s.t.  . We prove this by showing the following contrapositive: if
. We prove this by showing the following contrapositive: if  and
and  are disjoint, then
are disjoint, then  .From the fact that
.From the fact that  , since outside of
, since outside of  for Player
for Player ![\[\Psi((T,2n+2),(D,2n+2))=((T,2n+2),(D,2n+2)).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-0f1dd8b51761bf09ee90509269b29e76_l3.png "Rendered by QuickLaTeX.com")
 , since apart from the outcomes we have already mapped to, no other outcome gives Player
, since apart from the outcomes we have already mapped to, no other outcome gives Player  . Next it follows that
. Next it follows that  , again because all outcomes with utility at least
, again because all outcomes with utility at least  for Player
for Player  . By an analogous line of argument we can show that
. By an analogous line of argument we can show that ![\[\Psi((T,2n),(D,n))=((T,2n),(D,n)), ..., \Psi((T,n+1),(D,1))=((T,n+1),(D,1)).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-b93d92d37ea486b0873a0e4a077cf9e5_l3.png "Rendered by QuickLaTeX.com")
 and
and  .
. . We show a contrapositive, specifically that if this were not the case then
. We show a contrapositive, specifically that if this were not the case then  . Then from item a it follows that there is
. Then from item a it follows that there is  such that neither
such that neither  nor
nor  . Then either
. Then either  and hence
and hence  or
or  and hence
and hence  .
.![\Psi(A^{\Gamma,[n]})](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-30da71827db789193806285a214de476_l3.png "Rendered by QuickLaTeX.com") must be a subset of
must be a subset of ![A^{\hat \Gamma,[\hat n]}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-53b69e2ef686ad668c5678e3b3ddc8d4_l3.png "Rendered by QuickLaTeX.com") . To show this, notice first that
. To show this, notice first that  for all
for all  by a similar argument as used repeatedly in Item a. Hence,
by a similar argument as used repeatedly in Item a. Hence, ![\Psi(A^{\Gamma,[n]}) \subseteq A^{\hat \Gamma, [2n]}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-511054df0683eae94efe9f57b8e3be6c_l3.png "Rendered by QuickLaTeX.com") . Now assume for contraposition that there is
. Now assume for contraposition that there is  for some
for some  . Then for all but one opponent move
. Then for all but one opponent move  with
with ![l\in [2n]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-0bed69452597a699957e4ac8fe34ba19_l3.png "Rendered by QuickLaTeX.com") ,
,  . But since
. But since  , there are at least two opponent moves
, there are at least two opponent moves  . Hence,
. Hence, ![j\in [\hat n]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-8668e83a8cf9fb6766091a006574a684_l3.png "Rendered by QuickLaTeX.com") , if
, if  . To see this, assume it was
. To see this, assume it was  for some
for some  . Then by Item c,
. Then by Item c, ![l\in [n]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-197ec4dc5445745bbfa3cb3bcb51e81b_l3.png "Rendered by QuickLaTeX.com") . Hence,
. Hence,
![\[u_2^c((T,i),(R,i))=2>1=u_2^c((R,j),(P,l))=u_2^c(\Psi_1(T,i),\Psi_2(R,i))\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-49590dfb8f50fbad9e5dd7afd56a035f_l3.png "Rendered by QuickLaTeX.com")
 to be the second element of the pair
to be the second element of the pair  . By Item c,
. By Item c,  . By Item d,
. By Item d, ![[n]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-41be326990cb1584673965aedcfb1d0d_l3.png "Rendered by QuickLaTeX.com") to
to ![[\hat n]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-eb7caa12ed2da07aad3b63cba3e8978a_l3.png "Rendered by QuickLaTeX.com") . By assumption about
. By assumption about ![i,j\in[n]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-94a693d778b5d97adbda6266ff30bc05_l3.png "Rendered by QuickLaTeX.com") with
with 
 , it can be made safe.
, it can be made safe. .
. are safely achievable. Remember that not all payoff vectors on the line segments are Pareto improvements, only those that are to the north-east of (Pareto-better than) the default utility. In the following, we will use
are safely achievable. Remember that not all payoff vectors on the line segments are Pareto improvements, only those that are to the north-east of (Pareto-better than) the default utility. In the following, we will use  and
and  to denote those elements of
to denote those elements of ![y_1=\mathbb{E}\left[u_1(\Pi(\Gamma))\right]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-060efa64c084b5c19ae9da7866f63f19_l3.png "Rendered by QuickLaTeX.com") is safely achievable. In other words,
is safely achievable. In other words, ![{\mathbf{y}}=\pi_1(\mathbb{E}\left[{\mathbf{u}}(\Pi(\Gamma))\right],L_1)](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-ba4bd9f9a4b3540105d5c6f60f858cf8_l3.png "Rendered by QuickLaTeX.com") . This
. This  in
in 
 . Hence, all values of
. Hence, all values of ![\begin{eqnarray*} \mathbb{E}\left[ {\mathbf{u}}^e (\Pi(\Gamma^s)) \right] &=& \mathbb{E}\left[ \pi_1({\mathbf{u}}(\Pi(\Gamma)) , L_1) \right]\\ &=& \pi_1(\mathbb{E} \left[ {\mathbf{u}}(\Pi(\Gamma)) \right],L_1) \end{eqnarray*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-414fd7cd8b9b0bf1021ab6ff4910be52_l3.png "Rendered by QuickLaTeX.com")
 as before as those elements of
as before as those elements of  respectively that Pareto improve on the default
respectively that Pareto improve on the default ![\mathbb{E}\left[{\mathbf{u}}(\Pi(\Gamma))\right]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-4b5dcea61096e5beadc3e98c24ce3622_l3.png "Rendered by QuickLaTeX.com") . By a similar argument as before, one can show that the utilities
. By a similar argument as before, one can show that the utilities ![\pi_i(\mathbb{E}\left[{\mathbf{u}}(\Pi(\Gamma))\right],L_j')](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-426eeed723efe454bfb83d097a62252e_l3.png "Rendered by QuickLaTeX.com") is safely achievable both for
is safely achievable both for  and for
and for  . Call these points
. Call these points  and
and  , respectively.
, respectively. , which is above both
, which is above both  of the corresponding
of the corresponding  to be above or on both
to be above or on both  . Formally,
. Formally,  that are not strictly Pareto dominated by some other element of
that are not strictly Pareto dominated by some other element of  . Note that by definition every outcome in
. Note that by definition every outcome in ![E_2=\mathbb{E}\left[ {\mathbf{u}}^e (\Pi(\Gamma ^s)) \right]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-c57ebac5a21ec6e18e64fe8feabbf28f_l3.png "Rendered by QuickLaTeX.com") is therefore also in the set of feasible payoffs on or above
is therefore also in the set of feasible payoffs on or above  to prove the claim. Because of convexity of the set of safely achievable payoff vectors as per Corollary 14, all utilities below the curve consisting of the line segments from
to prove the claim. Because of convexity of the set of safely achievable payoff vectors as per Corollary 14, all utilities below the curve consisting of the line segments from  intersects the line that contains
intersects the line that contains  curve lies entirely above or on
curve lies entirely above or on  . Now take any Pareto improvement that lies below both
. Now take any Pareto improvement that lies below both  and therefore below the
and therefore below the ![\[\begin{array}{ccc} \textbf{Anthony DiGiovanni} & \textbf{Nicolas Mac\'e} &\textbf{Jesse Clifton}\\ \text{Center on Long-Term Risk} & \text{Center on Long-Term Risk} &\text{Center on Long-Term Risk} \end{array}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-6afe1622010b2155bc45d5941dff3678_l3.png "Rendered by QuickLaTeX.com")
 and payoff functions
and payoff functions  . Players choose actions in the base game as functions of strategies that are selected in an evolutionary process. Suppose players simultaneously play strategies (elements of some abstract space
. Players choose actions in the base game as functions of strategies that are selected in an evolutionary process. Suppose players simultaneously play strategies (elements of some abstract space  ) and observe each other's strategies, then play
) and observe each other's strategies, then play  , where player
, where player  is
is  . In standard evolutionary analysis the fitness of a strategy equals its payoff in
. In standard evolutionary analysis the fitness of a strategy equals its payoff in  . (We distinguish fitness from payoffs because once complexity costs are included, as in Section
. (We distinguish fitness from payoffs because once complexity costs are included, as in Section  is:
is: ,
,  .
. such that
such that  ,
,  .
. in the definition of ESS implies a stronger “pull” towards an ESS in evolutionary dynamics (such as the replicator dynamic) than towards an NSS: If a rare mutant that enters a population consisting of an ESS has the same fitness when paired with itself as the ESS has against this mutant, the mutant goes extinct under the replicator dynamic, but this does not necessarily hold for an NSS [van Veelen, 2010].
in the definition of ESS implies a stronger “pull” towards an ESS in evolutionary dynamics (such as the replicator dynamic) than towards an NSS: If a rare mutant that enters a population consisting of an ESS has the same fitness when paired with itself as the ESS has against this mutant, the mutant goes extinct under the replicator dynamic, but this does not necessarily hold for an NSS [van Veelen, 2010]. , and, for some
, and, for some  and
and  , the players receive payoffs:
, the players receive payoffs:
 represents negative or positive externalities of each player's action for the other's payoff (when
represents negative or positive externalities of each player's action for the other's payoff (when  or
or  , respectively). In the original model, players are assumed to have the following subjective utility functions, for
, respectively). In the original model, players are assumed to have the following subjective utility functions, for  :
:
 in which payoffs are given by
in which payoffs are given by  , denoted
, denoted  . That is, letting
. That is, letting  represent player
represent player  .
. (respectively,
(respectively,  ) has subjective utility increasing (decreasing) with the other's payoff — these ranges of
) has subjective utility increasing (decreasing) with the other's payoff — these ranges of  . Thus, when
. Thus, when  given by the altruistic ESS both receive a higher payoff than the equilibrium of
given by the altruistic ESS both receive a higher payoff than the equilibrium of  , this means that as
, this means that as  , the ESS approaches efficiency. Intuitively, these other-regarding preferences are stable in Possajennikov [2000]’s model because they serve as commitment devices that elicit favorable responses from the other player [Frank, 1987, Dufwenberg and Güth, 1999]. That is, each agent best-responds under the assumption that the other player will play rationally with respect to their utility function, and as utility functions are selected based on payoffs from the opponent’s best response to the action optimizing those utility functions, the population converges to some
, the ESS approaches efficiency. Intuitively, these other-regarding preferences are stable in Possajennikov [2000]’s model because they serve as commitment devices that elicit favorable responses from the other player [Frank, 1987, Dufwenberg and Güth, 1999]. That is, each agent best-responds under the assumption that the other player will play rationally with respect to their utility function, and as utility functions are selected based on payoffs from the opponent’s best response to the action optimizing those utility functions, the population converges to some  .
. as above. We say that a preference parameter
as above. We say that a preference parameter  , and other-regarding otherwise. In our results we will use the following assumptions, which are satisfied by the externality game:
, and other-regarding otherwise. In our results we will use the following assumptions, which are satisfied by the externality game: ,
,  and
and  has a unique global maximum,
has a unique global maximum,  . (That is, the best response to some action under any subjective utility function is unique.)
. (That is, the best response to some action under any subjective utility function is unique.) is surjective on
is surjective on  .
.  can be exploitable, in the sense that a player
can be exploitable, in the sense that a player  , so the rational strategy is
, so the rational strategy is  .
. , and
, and  , we can check that the payoff of
, we can check that the payoff of ![\[u_i(\text{NE}_i(\alpha^*,0), \text{NE}_j(\alpha^*,0)) > u_i(\text{NE}_i(0,0), \text{NE}_j(0,0)) > u_j(\text{NE}_i(\alpha^*,0), \text{NE}_j(\alpha^*,0)).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-f812aa59d26da0566f25d7a04868452c_l3.png "Rendered by QuickLaTeX.com")
 is the union of these sets:
is the union of these sets: : Behavioral strategy whose action is
: Behavioral strategy whose action is  for all
for all  .
. : Rational strategy whose action is
: Rational strategy whose action is  if
if  , or
, or  if
if  .
. or a strategy
or a strategy  that is a Nash equilibrium in
that is a Nash equilibrium in  . Further,
. Further,  , we apply the usual evolutionary stability analysis to a modified strategy fitness function:
, we apply the usual evolutionary stability analysis to a modified strategy fitness function:
 we define
we define ![c(\sigma) = \epsilon_R \mathbb{I}[\sigma \in \mathcal{R}]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-d66e3c71631e7293dd43bab83a03e9f6_l3.png "Rendered by QuickLaTeX.com") (where the function
(where the function  returns
returns  , the unique Nash equilibrium in
, the unique Nash equilibrium in  . Each player uses a strategy that (through the function
. Each player uses a strategy that (through the function  . If a given strategy has
. If a given strategy has  parameters under selection across
parameters under selection across  games,
games,  : Plays
: Plays  in game
in game  .
. : Plays the rational strategy with respect to
: Plays the rational strategy with respect to  by a single
by a single  , letting
, letting  denote the number of unique elements of
denote the number of unique elements of  , define:
, define:
 and
and  . Intuitively, a behavioral strategy will be stable when
. Intuitively, a behavioral strategy will be stable when  with
with  and
and  , denoted
, denoted  and
and  . However, to investigate the effects of imbalanced environments (i.e., where
. However, to investigate the effects of imbalanced environments (i.e., where  in
in  as the externality game payoff function for a given
as the externality game payoff function for a given  against
against 
 is randomly sampled from the spaces of rational and behavioral strategies. In each round
is randomly sampled from the spaces of rational and behavioral strategies. In each round  of evolution, each player in the population either (with low probability) switches to a random strategy, or else switches to the best response to a uniformly sampled opponent in the population (with respect to the penalized fitness
of evolution, each player in the population either (with low probability) switches to a random strategy, or else switches to the best response to a uniformly sampled opponent in the population (with respect to the penalized fitness  above).
above). might use one action across both games, incurring a complexity cost of
might use one action across both games, incurring a complexity cost of  . We fix
. We fix  , and
, and  . In each experiment, we tune the multi-game complexity penalty
. In each experiment, we tune the multi-game complexity penalty  ,
,  , and
, and  , and vary
, and vary  . For
. For  , the population converged to a behavioral strategy that uses only one action, for all values of
, the population converged to a behavioral strategy that uses only one action, for all values of  . For
. For ![\kappa_1 \in [-0.1, 0.1]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-2eb0282704799062547035425c392d67_l3.png "Rendered by QuickLaTeX.com") , the population converges to
, the population converges to  , suggesting that other-regarding preferences only interpolate well across these externality games when the externalities are sufficiently strong in magnitude.
, suggesting that other-regarding preferences only interpolate well across these externality games when the externalities are sufficiently strong in magnitude.
 of games have
of games have  , as a function of
, as a function of 
 , as a function of
, as a function of  and
and  , where the population consists of behavioral strategies (depicted with open circles). The per-parameter penalty is
, where the population consists of behavioral strategies (depicted with open circles). The per-parameter penalty is  .
. , for three pairs of games. For all pairs of
, for three pairs of games. For all pairs of  and
and  (blue curve in Figure 2). Again, the trend of decreasing
(blue curve in Figure 2). Again, the trend of decreasing  . When
. When  and
and  (orange curve), even small proportions of the large-magnitude negative
(orange curve), even small proportions of the large-magnitude negative  . That is, in an environment where one game has weak positive externalities and the other has strong negative externalities, most of the effect on the population's other-regarding preferences comes just from having a frequency of strong negative externalities above some (small) threshold. The same pattern holds in the opposite direction when
. That is, in an environment where one game has weak positive externalities and the other has strong negative externalities, most of the effect on the population's other-regarding preferences comes just from having a frequency of strong negative externalities above some (small) threshold. The same pattern holds in the opposite direction when  and
and  (green curve).
(green curve).
 takes over the population when
takes over the population when ![\kappa \in [-0.1, 0.1]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-5a7a5fe579537290716d826c1b8dc02e_l3.png "Rendered by QuickLaTeX.com") is not sensitive to
is not sensitive to 
 and a proportion
and a proportion  , as a function of the per-parameter penalty
, as a function of the per-parameter penalty  for different values of
for different values of  for each
for each  . To visualize the transitions between limiting populations of behavioral versus rational strategies, we compute the social welfare
. To visualize the transitions between limiting populations of behavioral versus rational strategies, we compute the social welfare  averaged over the last two rounds (for some parameter values, the population oscillates) of each evolutionary simulation for penalty
averaged over the last two rounds (for some parameter values, the population oscillates) of each evolutionary simulation for penalty  ) the population attains the near-lowest social welfare, where all in the population play the base game Nash equilibrium. The penalty
) the population attains the near-lowest social welfare, where all in the population play the base game Nash equilibrium. The penalty  is sufficient for all populations to converge to an other-regarding rational strategy, which attains the highest social welfare when
is sufficient for all populations to converge to an other-regarding rational strategy, which attains the highest social welfare when  but nearly the lowest when
but nearly the lowest when  , i.e., when most of the games have
, i.e., when most of the games have  or
or  (see the values of
(see the values of  for
for  , while
, while  is the unique efficient rational strategy.
is the unique efficient rational strategy.
 , let
, let ![c(\sigma) = \epsilon_H\mathbb{I}[\sigma \in \mathcal{H}] + \epsilon_R \mathbb{I}[\sigma \in \mathcal{R}]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-cc29260f235a953b50192fe0b886d7a4_l3.png "Rendered by QuickLaTeX.com") . Then
. Then  is still an ESS under the conditions of Proposition 2, with
is still an ESS under the conditions of Proposition 2, with 
 would yield similar results to Section
would yield similar results to Section  , the payoff of the Nash equilibrium with egoistic preferences. By the definition of Nash equilibrium of
, the payoff of the Nash equilibrium with egoistic preferences. By the definition of Nash equilibrium of  , the strategy
, the strategy  . Then we must have
. Then we must have  , because otherwise uniqueness of the Nash equilibrium (assumption 1) would be violated. So
, because otherwise uniqueness of the Nash equilibrium (assumption 1) would be violated. So  is not a Nash equilibrium in
is not a Nash equilibrium in  is unique, there is no behavioral strategy
is unique, there is no behavioral strategy  such that
such that  . Suppose a rational strategy
. Suppose a rational strategy  . Then
. Then ![\[\argmax_{a} V^\alpha_i(a,\text{NE}_i(0,0)) = \argmax_{a} \{u_i(a,\text{NE}_i(0,0)) + \alpha u_j(a\text{NE}_i(0,0))\} = \text{NE}_i(0,0).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-38e0b5f203c338b923982e6663da1fb3_l3.png "Rendered by QuickLaTeX.com")
 .
. , and
, and  , therefore
, therefore  against itself, so
against itself, so  . Suppose a deviator
. Suppose a deviator  such that
such that  . Therefore:
. Therefore:
 . Then
. Then ![\[f_i(B(\text{NE}_i(\alpha,\alpha)), R(\alpha)) = u_i(\text{NE}_i(\alpha,\alpha), \text{NE}_j(\alpha,\alpha)) = f_i(R(\alpha),R(\alpha)),\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-f14ce609d60288464732012d3cf3d65f_l3.png "Rendered by QuickLaTeX.com")
 . So
. So  do not change, since this set has the lowest complexity. However, when assessing the stability of
do not change, since this set has the lowest complexity. However, when assessing the stability of  ,
, ![\[f_i(\sigma, B(\text{NE}_i(0,0))) \leq u_N - \epsilon_R < f_i(B(\text{NE}_i(0,0)), B(\text{NE}_i(0,0))).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-0b3d06ed8dbe0747b2a85ab508d4c8f2_l3.png "Rendered by QuickLaTeX.com")
 . But
. But  , so
, so  , where the strategy is
, where the strategy is  or
or  if
if  . A population of size
. A population of size  is initialized with
is initialized with  and
and  for each player in the population. Let
for each player in the population. Let  and
and  if
if  , otherwise
, otherwise  . The probability of switching to a random strategy from the initialization distribution in round
. The probability of switching to a random strategy from the initialization distribution in round  . (We decay
. (We decay ![\[\begin{array}{ccc} \textbf{Anthony DiGiovanni} & &\textbf{Jesse Clifton}\\ \text{Center on Long-Term Risk} & &\text{Center on Long-Term Risk}\\ \texttt{anthony.digiovanni@longtermrisk.org} & &\texttt{jesse.clifton@longtermrisk.org}\\ \end{array}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-4daec5c06eadb1e0f1fb4944d92e808e_l3.png "Rendered by QuickLaTeX.com")
 form an equilibrium of mutual cooperation.
form an equilibrium of mutual cooperation. , giving joint type space
, giving joint type space  . At the start of the game, players' types are sampled by Nature according to the common prior
. At the start of the game, players' types are sampled by Nature according to the common prior  . Each player knows only their type. Player
. Each player knows only their type. Player  for each type in
for each type in  denote player
denote player  and follow an action profile
and follow an action profile  . A Bayesian Nash equilibrium is an action profile
. A Bayesian Nash equilibrium is an action profile  in which every player and type plays a best response with respect to the prior over other players' types: For all players
in which every player and type plays a best response with respect to the prior over other players' types: For all players  ,
,  . An
. An  (a distribution over action profiles), let
(a distribution over action profiles), let  . When it is helpful, we will write
. When it is helpful, we will write  to clarify the subset of the type profile on which the correlated strategy is conditioned. Let
to clarify the subset of the type profile on which the correlated strategy is conditioned. Let  denote a correlated strategy whose
denote a correlated strategy whose  independently of
independently of  such that, for all players
such that, for all players  ,
, 
 used by the other players such that, for all
used by the other players such that, for all 
 is used by the other players to punish player
is used by the other players to punish player  . Since the inequalities hold for all
. Since the inequalities hold for all  ,
, 
 , a payoff
, a payoff  such that
such that  for all
for all  for some
for some 
 from some revelation action set
from some revelation action set  , which is a subset of
, which is a subset of  . Then, all players observe each~
. Then, all players observe each~ be the profile of revelation actions (as functions of types) in a Bayesian Nash equilibrium
be the profile of revelation actions (as functions of types) in a Bayesian Nash equilibrium  for all
for all  is a strict subset of
is a strict subset of 
 and
and  to countries 1 and 2, respectively. If country 2 rejects this offer, they go to war. Each player wins with some probability (detailed below), and each pays a cost of fighting
to countries 1 and 2, respectively. If country 2 rejects this offer, they go to war. Each player wins with some probability (detailed below), and each pays a cost of fighting  . The winner receives a payoff of 1, and the loser gets 0.
. The winner receives a payoff of 1, and the loser gets 0. ) or strong (
) or strong ( ), while country 1's strength is common knowledge. Further, country 2 has a weak point, which country 1 believes is equally likely to be in one of two locations
), while country 1's strength is common knowledge. Further, country 2 has a weak point, which country 1 believes is equally likely to be in one of two locations  . Thus country
. Thus country  . Country 1 can make a sneak attack on
. Country 1 can make a sneak attack on  , independent of whether they go to war. Country 1 would gain
, independent of whether they go to war. Country 1 would gain  from attacking
from attacking  , costing
, costing  for country 2. But incorrectly attacking
for country 2. But incorrectly attacking  would cost
would cost  for country 1, so country 1 would not risk an attack given a prior of
for country 1, so country 1 would not risk an attack given a prior of  on each of the locations. If country 2 reveals its full type by allowing inspectors from country 1 to assess its military strength
on each of the locations. If country 2 reveals its full type by allowing inspectors from country 1 to assess its military strength  for all players
for all players  from an abstract space of devices
from an abstract space of devices  . These devices are mappings from the player's type to a response function and a type revelation function. As in
. These devices are mappings from the player's type to a response function and a type revelation function. As in  . (This notation, adopted from F
. (This notation, adopted from F and a signal
and a signal  .
. , which are not in the framework of F
, which are not in the framework of F indicates whether player
indicates whether player  if this value is 1 or
if this value is 1 or  if it is
if it is  . Further, they can choose whether to reveal their type to another player, via
. Further, they can choose whether to reveal their type to another player, via  , based on that player's device. Thus players can decide not to reveal private information to players whose devices are not in a desired device profile, and instead punish them.
, based on that player's device. Thus players can decide not to reveal private information to players whose devices are not in a desired device profile, and instead punish them. is the one-shot Bayesian game in which each player
is the one-shot Bayesian game in which each player  , as a function of their type. After devices are simultaneously and independently submitted (potentially as a draw from a mixed strategy over devices), the signal
, as a function of their type. After devices are simultaneously and independently submitted (potentially as a draw from a mixed strategy over devices), the signal  in
in  is
is  .
. be a correlated strategy inducing a feasible and INTIR payoff profile
be a correlated strategy inducing a feasible and INTIR payoff profile  . Let
. Let  be a punishment strategy that is arbitrary except, if
be a punishment strategy that is arbitrary except, if  , let
, let  be the deterministic action profile, called the target action profile, given by
be the deterministic action profile, called the target action profile, given by  , and let
, and let  be the deterministic action profile given by
be the deterministic action profile given by 
 .
. . Note that the outputs of player
. Note that the outputs of player  may in general be the same as those returned by
may in general be the same as those returned by  . We will show that
. We will show that  or
or  . Let
. Let  . Then:
. Then:
 , therefore
, therefore  so
so  such that:
such that:
 . Then if player
. Then if player  such that
such that  :
:
 . If country 2 rejects the offer
. If country 2 rejects the offer  if its army is weak, or
if its army is weak, or  if strong.
if strong. . In the perfect Bayesian equilibrium of
. In the perfect Bayesian equilibrium of  , which country 2 rejects
, which country 2 rejects  , which country 2 would accept, given knowledge of the weak point
, which country 2 would accept, given knowledge of the weak point  .
. that country 2 accepts, and commits not to attack
that country 2 accepts, and commits not to attack  is not IC, and hence cannot be achieved under the assumptions of
is not IC, and hence cannot be achieved under the assumptions of  (absent type-conditional commitment by country 1). In this example, conditional type revelation is required for efficiency due to a practical inability to reveal military strength without also revealing a vulnerability (Table 1). In other words, country 2's revelation action set
(absent type-conditional commitment by country 1). In this example, conditional type revelation is required for efficiency due to a practical inability to reveal military strength without also revealing a vulnerability (Table 1). In other words, country 2's revelation action set  is too restricted for full unraveling to occur. Interactions between advanced artificially intelligent agents may feature similar problems necessitating our framework. For example, if revelation requires sharing source code or the full set of parameters of a neural network that lacks cleanly separated modules, unconditional revelation risks exposing exploitable information. See also example 7 of
is too restricted for full unraveling to occur. Interactions between advanced artificially intelligent agents may feature similar problems necessitating our framework. For example, if revelation requires sharing source code or the full set of parameters of a neural network that lacks cleanly separated modules, unconditional revelation risks exposing exploitable information. See also example 7 of  rather than
rather than  depends only on the part of country 2's type that is revealed by the unraveling argument. Country 2 does not profit from lying about its exploitable, non-unraveled information — that is, the payoff is IC with respect to that information, even if not IC in the pre-unraveling game. Thus country 1 does not need to know this information for the efficient payoff to be achieved in equilibrium. Formally, in this case
depends only on the part of country 2's type that is revealed by the unraveling argument. Country 2 does not profit from lying about its exploitable, non-unraveled information — that is, the payoff is IC with respect to that information, even if not IC in the pre-unraveling game. Thus country 1 does not need to know this information for the efficient payoff to be achieved in equilibrium. Formally, in this case  , i.e., country 2 can choose to reveal any
, i.e., country 2 can choose to reveal any  , producing an equilibrium of partial unraveling. We can generalize this observation with the following proposition.
, producing an equilibrium of partial unraveling. We can generalize this observation with the following proposition. for all
for all  . Let
. Let  of types remaining after unraveling. As in F
of types remaining after unraveling. As in F ).
).![s_i \stackrel{\text{iid}}{\sim} \text{Unif}[0,1]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-3fc8510e98c1817498c60ca4c4544ff9_l3.png "Rendered by QuickLaTeX.com") of a good. After observing their respective valuations, players simultaneously choose whether to reveal them. Then they simultaneously submit bids
of a good. After observing their respective valuations, players simultaneously choose whether to reveal them. Then they simultaneously submit bids  , and the higher bid wins the good, with a tie broken by a fair coin. Thus player
, and the higher bid wins the good, with a tie broken by a fair coin. Thus player ![s_i(\mathbb{I}[x_i \geq x_{-i}] - \frac{1}{2}\mathbb{I}[x_i = x_{-i}]) - x_i](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-a962c3b5b76326f1f7d06483809403db_l3.png "Rendered by QuickLaTeX.com") . There is a Bayesian Nash equilibrium of this base game in which
. There is a Bayesian Nash equilibrium of this base game in which  , and neither player reveals their valuation [14]. In this equilibrium, each player's ex interim payoff is:
, and neither player reveals their valuation [14]. In this equilibrium, each player's ex interim payoff is:
 if
if  ,
,  if
if  , and
, and  otherwise.
otherwise. , and consider the following strategy
, and consider the following strategy  and
and  . For
. For  , let
, let  and
and  . Otherwise, let
. Otherwise, let  . Then:
. Then:
 if
if  if
if  otherwise. Finally, this payoff is not IC, because if
otherwise. Finally, this payoff is not IC, because if  .
. and
and  , i.e., the case of
, i.e., the case of  , are not feasible. This non-IC payoff thus requires
, are not feasible. This non-IC payoff thus requires  . However, in practice the players may favor this payoff over
. However, in practice the players may favor this payoff over  for either player, the supremum of the sum of payoffs is
for either player, the supremum of the sum of payoffs is  .
. ") is:
") is: 
 (where "SIR" stands for "strategic information revelation"), and show that it forms a
(where "SIR" stands for "strategic information revelation"), and show that it forms a  from the program space
from the program space  , a set of computable functions from
, a set of computable functions from  to
to  . A program returns either an action or a type revelation vector. Each program takes as input the players' program profile, the signal
. A program returns either an action or a type revelation vector. Each program takes as input the players' program profile, the signal  , and a boolean that equals 1 if the program's output is an action, and 0 otherwise.
, and a boolean that equals 1 if the program's output is an action, and 0 otherwise. for a call to a program with the boolean set to
for a call to a program with the boolean set to  . Player
. Player  . (We refer to these initial program calls as the base calls to distinguish them from calls made by other programs.) Then, the ex post payoff of player
. (We refer to these initial program calls as the base calls to distinguish them from calls made by other programs.) Then, the ex post payoff of player  .
. on which programs can condition their outputs. Like
on which programs can condition their outputs. Like  of recursion reached in the call stack, a variable
of recursion reached in the call stack, a variable  is independently sampled from
is independently sampled from ![\text{Unif}[0,1]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-6c39484077a038c632ed3dd4c805a4e3_l3.png "Rendered by QuickLaTeX.com") . Each program call at level
. Each program call at level  from
from  will call truncated versions of its counterparts' revelation programs: For
will call truncated versions of its counterparts' revelation programs: For  , let
, let ![[p_i]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-c7b11cbbdffde73b9534f1c31042ff1f_l3.png "Rendered by QuickLaTeX.com") denote
denote  with immediate termination upon calling another program.
with immediate termination upon calling another program.
 reveals its type unconditionally with probability
reveals its type unconditionally with probability  some players who may have otherwise cooperated, with low probability.
some players who may have otherwise cooperated, with low probability.
 . Assume all strategies returned by these programs are computable. For type profile
. Assume all strategies returned by these programs are computable. For type profile  be the maximum payoff achievable by any player in
be the maximum payoff achievable by any player in  . Then the program profile given by Algorithm 1 (with
. Then the program profile given by Algorithm 1 (with  ) for players
) for players  , denoted
, denoted  , is a
, is a  play this profile, and player
play this profile, and player  that terminates with probability 1 given that any programs it calls terminate with probability 1, then:
that terminates with probability 1 given that any programs it calls terminate with probability 1, then:
 for two levels of recursion in a row, the calls to
for two levels of recursion in a row, the calls to  forces termination (line 4) of calls to other players' revelation programs. Thus the deviating programs also terminate, since they call terminating non-deviating programs. This establishes (1a). Finally, in the high-probability event that the first two levels of calls to
forces termination (line 4) of calls to other players' revelation programs. Thus the deviating programs also terminate, since they call terminating non-deviating programs. This establishes (1a). Finally, in the high-probability event that the first two levels of calls to ![[0,1]^2](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-afc980486b9d25732c7953dcb85b429f_l3.png "Rendered by QuickLaTeX.com") ). Their warriors are camped somewhere on the mountain, with coordinates
). Their warriors are camped somewhere on the mountain, with coordinates  . Player 1 has no information on the warriors' location, hence the prior is
. Player 1 has no information on the warriors' location, hence the prior is ![(\theta_x, \theta_y) \sim \text{Unif}[0,1]^2](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-a879d92c865d4e0995d2818168e1a4f3_l3.png "Rendered by QuickLaTeX.com") . But they know that warriors at higher altitudes are tougher; strength is proportional to
. But they know that warriors at higher altitudes are tougher; strength is proportional to  . As in Example 3.1, player 1 can offer a split
. As in Example 3.1, player 1 can offer a split  of disputed territory. If the players fight, then player 1 will send in paratroopers at a location
of disputed territory. If the players fight, then player 1 will send in paratroopers at a location  to fight player 2's warriors at a cost proportional to their strength
to fight player 2's warriors at a cost proportional to their strength  ). Meanwhile, player 2 wants the paratroopers to land as far from their village as possible, i.e., they want to maximize
). Meanwhile, player 2 wants the paratroopers to land as far from their village as possible, i.e., they want to maximize  . Player 2 wins the ensuing battle with probability equal to their army's strength, i.e.,
. Player 2 wins the ensuing battle with probability equal to their army's strength, i.e.,  . First, player 2 chooses
. First, player 2 chooses  . Then player 1 chooses
. Then player 1 chooses ![s \in [0,1]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-5ef62fd38ae9616fcf994079ac344646_l3.png "Rendered by QuickLaTeX.com") . Player 2 can either accept or reject
. Player 2 can either accept or reject  . Otherwise, player 1 plays
. Otherwise, player 1 plays ![(t_x, t_y) \in [0,1]^2](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-c88731e539aff2c1b2f7c61fd7d2002b_l3.png "Rendered by QuickLaTeX.com") , and for
, and for  :
:
 for any function
for any function ![\begin{align*} t^*(s) &= \begin{cases} \frac{3-\sqrt{5}}{2},& \text{if } s > c_2 - \frac{3-\sqrt{5}}{2} + 1\\ \frac{(3-\sqrt{5})(c_2 - s - 1)}{2} + 1,& \text{otherwise}. \end{cases}\\ r(s) &= 1 - s - t^*(s) + c_2 \\ q_{U_1(s)}(\theta_x, \theta_y) &= \frac{\mathbb{I}[\min\{\theta_x, \theta_y\} \leq t^*(s)]}{t^*(s)(2 - t^*(s))} \\ q_{U_2(s)}(\theta_x, \theta_y) &= \frac{\mathbb{I}[\min\{\theta_x, \theta_y\} \in (r^+(s), t^*(s)]]}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ p(s) &= \mathbb{I}[r(s) \geq t^*(s)] + \mathbb{I}[r(s) < t^*(s)] \cdot \frac{r^+(s)(2 - r^+(s))}{t^*(s)(2 - t^*(s))} \\ m_1(s) &= \frac{(r^+(s)^4 - r^+(s)^3 - r^+(s)) - (t^*(s)^4 - t^*(s)^3 - t^*(s))}{3(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ m_2(s) &= \frac{t^*(s)^2 - r^+(s)^2 - \frac{2}{3}(t^*(s)^3 - r^+(s)^3)}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ s^* &= \textrm{arg\,max}_s sp(s) + (1 - 2m_2(s) - 2(m_1(s) - t^*(s)^2) - c_1)(1-p(s)) \\ s(\theta_x,\theta_y) &= 1 - 2\min\{\theta_x, \theta_y\} + c_2 \end{align*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-476389862e87f63540389854850cbd27_l3.png "Rendered by QuickLaTeX.com")
 . Let player 1's strategy be
. Let player 1's strategy be  then
then  conditional on a given
conditional on a given  then
then  , and to accept any and only
, and to accept any and only  . Let player 1's belief update to
. Let player 1's belief update to  conditional on player 2 not revealing their type, and to
conditional on player 2 not revealing their type, and to  conditional on player 2 not revealing their type and rejecting
conditional on player 2 not revealing their type and rejecting  such that this equilibrium is inefficient, and the payoff profile
such that this equilibrium is inefficient, and the payoff profile  is (1) a Pareto improvement on the equilibrium payoff and (2) not IC.
is (1) a Pareto improvement on the equilibrium payoff and (2) not IC.
 , player 1's optimal
, player 1's optimal  prefer to reveal, otherwise they prefer not to reveal, and types for which
prefer to reveal, otherwise they prefer not to reveal, and types for which  prefer to accept
prefer to accept  . The squared loss is minimized at
. The squared loss is minimized at ![\min\{\theta_x, \theta_y\} \in [r^+(s), t^*(s)]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-632d17dc21c63ad2482fbec61acf04be_l3.png "Rendered by QuickLaTeX.com") (see Figure 2), weighted by the areas of these rectangles, which can be shown to be:
(see Figure 2), weighted by the areas of these rectangles, which can be shown to be:
 .
. .
. for each
for each 
![\[P(\text{accept } s) = P(1 - s \geq t^*(s) + \min\{\theta_x, \theta_y\} - c_2) = P(\min\{\theta_x, \theta_y\} \leq r(s)).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-ae9d9d9f1ba4a0e69ab4c53a5f5e8234_l3.png "Rendered by QuickLaTeX.com")
 , this probability is given by the ratio of the areas of the regions
, this probability is given by the ratio of the areas of the regions  and
and  . We have:
. We have:
 and
and  . Therefore
. Therefore ![\begin{align*} \mathbb{E}_{q_{U_2(s)}}(u_1 | \text{reject } s) &= 1 - 2\min\{\theta_x, \theta_y\} - c_1 \\ P(\text{accept } s) &= \mathbb{I}[1 - s \geq 2 \min\{\theta_x, \theta_y\} - c_2] \\ \mathbb{E}(u_1) &= \begin{cases} s,& \text{if } s \leq 1 - 2\min\{\theta_x, \theta_y\} + c_2\\ 1 - 2\min\{\theta_x, \theta_y\} - c_1,& \text{otherwise}. \end{cases} \end{align*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-4e7458bc1af7edd1ee0c45a7c9dd6650_l3.png "Rendered by QuickLaTeX.com")
 is optimal, since
is optimal, since  increases with
increases with  , after which it drops to
, after which it drops to  .
. , and so
, and so  and
and  for any type. Given these responses, if player 2 does not reveal their type, their payoff is
for any type. Given these responses, if player 2 does not reveal their type, their payoff is  . If player 2 reveals their type, since we have shown that
. If player 2 reveals their type, since we have shown that  , and so player 2 prefers to reveal if and only if
, and so player 2 prefers to reveal if and only if  . Thus
. Thus  . Thus the updated belief is uniform on
. Thus the updated belief is uniform on ![\min\{\theta_x, \theta_y\} \in (r(s^*), t^*(s^*)]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-99720dc52f706abdd70148d797086e65_l3.png "Rendered by QuickLaTeX.com") , so
, so  is consistent. This proves that the proposed strategy profile and beliefs are a perfect Bayesian equilibrium.
is consistent. This proves that the proposed strategy profile and beliefs are a perfect Bayesian equilibrium. . The equilibrium payoffs for any types that do not reveal are:
. The equilibrium payoffs for any types that do not reveal are:
![\[(s_P(\theta_x,\theta_y), 1-s_P(\theta_x,\theta_y)) = (1 - t^*(1) - \min\{\theta_x, \theta_y\} + c_2, t^*(1) + \min\{\theta_x, \theta_y\} - c_2),\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-37eee71d30752adef498fbde6461ace1_l3.png "Rendered by QuickLaTeX.com")
 and player 2 accepts any
and player 2 accepts any  . This is feasible because player 2 only reveals if
. This is feasible because player 2 only reveals if  , and
, and  , so
, so  . For this to be a Pareto improvement on the perfect Bayesian equilibrium, it is sufficient that
. For this to be a Pareto improvement on the perfect Bayesian equilibrium, it is sufficient that  . This payoff profile is not IC, because player 2's payoff increases with
. This payoff profile is not IC, because player 2's payoff increases with  can profit from the strategy profile above conditioned on a type
can profit from the strategy profile above conditioned on a type  such that
such that  .
.![\begin{align*} \mathbb{E}_{q_{U_2(s)}}(\min\{\theta_x, \theta_y\}) = \frac{\int_0^1 \int_0^1 \min\{\theta_x, \theta_y\} \mathbb{I}[\min\{\theta_x, \theta_y\} \in [r^+(s),t^*(s)]] d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))}\end{align*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-a91d04d095f123d1560352b91024d250_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} &= \frac{\int_0^1 \int_0^{\theta_y} \theta_x \mathbb{I}[\theta_x \in [r^+(s),t^*(s)]] d\theta_x d\theta_y + \int_0^1 \int_{\theta_y}^1 \theta_y \mathbb{I}[\theta_y \in [r^+(s),t^*(s)]] d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\&= \frac{\int_0^1 \int_{\min\{\theta_y,t^*(s), r^+(s)\}}^{\min\{\theta_y, t^*(s)\}} \theta_x d\theta_x d\theta_y + \int_{r^+(s)}^{t^*(s)} \int_{\theta_y}^{1} \theta_y d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= \frac{\frac{1}{2}\int_0^1 (\min\{\theta_y, t^*(s)\}^2 - \min\{\theta_y,t^*(s),r^+(s)\}^2) d\theta_y + \int_{r^+(s)}^{t^*(s)} \theta_y (1 - \theta_y) d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= \frac{\frac{1}{2}\int_0^{t^*(s)} \theta_y^2 d\theta_y + \frac{1}{2}\int_{t^*(s)}^1 t^*(s)^2 d\theta_y - \frac{1}{2}\int_0^{r^+(s)} \theta_y^2 d\theta_y - \frac{1}{2}\int_{r^+(s)}^1 r^+(s)^2 d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &+ \frac{\frac{1}{2}(t^*(s)^2 - r^+(s)^2) - \frac{1}{3}(t^*(s)^3 - r^+(s)^3)}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= \tfrac{\frac{1}{6}t^*(s)^3 + \frac{1}{2}(1-t^*(s)) t^*(s)^2 - \frac{1}{6}r^+(s)^3 - \frac{1}{2}(1-r^+(s)) r^+(s)^2 + \frac{1}{2}(t^*(s)^2 - r^+(s)^2) - \frac{1}{3}(t^*(s)^3 - r^+(s)^3)}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\&= m_2(s). \end{align*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-8562ffad57496dff2f50a7f94b6a3d6c_l3.png "Rendered by QuickLaTeX.com")
 Further,
Further,![\[\mathbb{V}_{q_{U_2(s)}} \theta_x = \mathbb{E}_{q_{U_2(s)}} \theta_x^2 - (\mathbb{E}_{q_{U_2(s)}} \theta_x)^2,\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-a7065ef7f6f4653970eb0a8e868686ef_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} \mathbb{E}_{q_{U_2(s)}} \theta_x^2 &= \frac{\int_0^1 \int_0^1 \theta_x^2 \mathbb{I}[\min\{\theta_x, \theta_y\} \in [r^+(s),t^*(s)]] d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= \frac{\int_0^1 \int_0^1 \theta_x^2 \mathbb{I}[\min\{\theta_x, \theta_y\} \geq r^+(s)] d\theta_x d\theta_y - \int_0^1 \int_0^1 \theta_x^2 \mathbb{I}[\min\{\theta_x, \theta_y\} \geq t^*(s)] d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= \frac{\int_{r^+(s)}^1 \int_{r^+(s)}^1 \theta_x^2 d\theta_x d\theta_y - \int_{t^*(s)}^1 \int_{t^*(s)}^1 \theta_x^2 d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\&= \frac{\frac{1}{3}(1 - r^+(s))(1 - r^+(s)^3) - \frac{1}{3}(1 - t^*(s))(1 - t^*(s)^3)}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= m_1(s). \end{align*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-17b26cc470b4c19897f151a3efe7d0e2_l3.png "Rendered by QuickLaTeX.com")
 . Suppose player
. Suppose player  . Given this assumption, we omit the subscripts of
. Given this assumption, we omit the subscripts of  and
and  . Let
. Let  and
and  respectively denote calls to
respectively denote calls to  immediately returns
immediately returns  . Consequently, every call to
. Consequently, every call to  because line 5 in
because line 5 in  . (Notice that the shared random variables
. (Notice that the shared random variables  are essentiall — if the programs unconditionally cooperated using independently sampled variables, an exponentially increasing number of variables would each need to be less than
are essentiall — if the programs unconditionally cooperated using independently sampled variables, an exponentially increasing number of variables would each need to be less than  be the event that
be the event that  be the event that
be the event that  and
and  . Thus for the program profile to terminate in finite time, it is sufficient to show that with probability 1 there exists a finite
. Thus for the program profile to terminate in finite time, it is sufficient to show that with probability 1 there exists a finite  are independent, because they do not overlap, we have:
are independent, because they do not overlap, we have:
 is the complement of the event we wanted to guarantee, this proves termination with probability 1. Further, the event
is the complement of the event we wanted to guarantee, this proves termination with probability 1. Further, the event  and
and  to return
to return  . Let
. Let  be the smallest finite level such that
be the smallest finite level such that  ,
,  , and
, and  (which exists with probability 1 by a similar argument to that above). Then all
(which exists with probability 1 by a similar argument to that above). Then all  and
and  for
for  for
for ](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-ca79fa842f6fb73eea6ed4f3be0aa711_l3.png "Rendered by QuickLaTeX.com") for
for  , guaranteed to terminate by definition, thus
, guaranteed to terminate by definition, thus  . But because
. But because  terminates, all calls to the programs of
terminates, all calls to the programs of  and
and  . First, note that any players
. First, note that any players  for
for  or
or  , note that if
, note that if  , we will only have
, we will only have  if
if  return
return  , then all other players also play
, then all other players also play  , all players
, all players  do not match those of
do not match those of 






 draws, the following world described gives the highest likelihood for both SIA and SSA (with reference class of observers in intelligent civilizations). That is, civilizations like ours are both relatively common and typical amongst all advanced-but-not-yet-expansive civilizations in this world.
draws, the following world described gives the highest likelihood for both SIA and SSA (with reference class of observers in intelligent civilizations). That is, civilizations like ours are both relatively common and typical amongst all advanced-but-not-yet-expansive civilizations in this world. , their light has reached around 35% of the observable universe. Nearly all GCs appear between 10Gy and 18 Gy after the Big Bang.
, their light has reached around 35% of the observable universe. Nearly all GCs appear between 10Gy and 18 Gy after the Big Bang.
 . This distribution is dependent on factors such as the difficulty of the evolution of life and the number of planets capable of supporting intelligent life. This distribution does not factor in the expansion of other ICs, which may prevent (‘preclude’) later ICs from existing. That is the focus of Chapter 2.
. This distribution is dependent on factors such as the difficulty of the evolution of life and the number of planets capable of supporting intelligent life. This distribution does not factor in the expansion of other ICs, which may prevent (‘preclude’) later ICs from existing. That is the focus of Chapter 2. for the time since the Big Bang, which is estimated 13.787 Gy (Ade 2016) [Gy = gigayear = 1 billion years].
for the time since the Big Bang, which is estimated 13.787 Gy (Ade 2016) [Gy = gigayear = 1 billion years]. away, and an identical copy of you
away, and an identical copy of you  away.
away. . Fixing some time
. Fixing some time  . When the step is hard, for
. When the step is hard, for  ,
,  is constant since
is constant since  .
. , the completion time of the steps has
, the completion time of the steps has . For modeling purposes, I split these try-try steps into delay steps and hard steps.
. For modeling purposes, I split these try-try steps into delay steps and hard steps. from the steps
from the steps  , the approximate duration life has taken on Earth so far. I then approximate the completion time of the delay try-try steps with the exponential distribution with parameter
, the approximate duration life has taken on Earth so far. I then approximate the completion time of the delay try-try steps with the exponential distribution with parameter  for the expected completion times of the
for the expected completion times of the  remaining steps. These steps are not necessarily hard with respect to Earth's habitable duration. I model each
remaining steps. These steps are not necessarily hard with respect to Earth's habitable duration. I model each  to have log-uniform uncertainty between 1 Gy and
to have log-uniform uncertainty between 1 Gy and  Gy. With this prior, most
Gy. With this prior, most  , the geometric mean hardness of the try-try steps.
, the geometric mean hardness of the try-try steps. for the PDF of the completion time of all the delay steps and hard try-try steps. Strictly, it is given as the convolution of the gamma distribution parameters
for the PDF of the completion time of all the delay steps and hard try-try steps. Strictly, it is given as the convolution of the gamma distribution parameters  and exponential distribution parameter
and exponential distribution parameter  ,
,  where
where  is the PDF of the Gamma distribution. That is, the delay steps can be approximated as completing in their expected time when they are sufficiently short in expectation.
is the PDF of the Gamma distribution. That is, the delay steps can be approximated as completing in their expected time when they are sufficiently short in expectation.
 ,
,  and
and  respectively, truncated to
respectively, truncated to  .
. . I chose this prior to later give estimates of life in line with existing estimates. A longer tailed distribution is arguably more applicable.
. I chose this prior to later give estimates of life in line with existing estimates. A longer tailed distribution is arguably more applicable.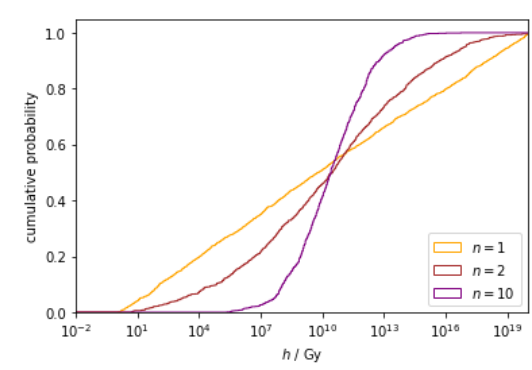
 . For higher
. For higher  .
.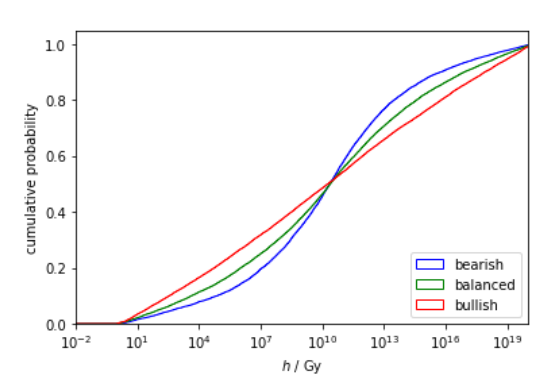
 . By definition
. By definition  and
and  makes little difference. My prior distribution gives median
makes little difference. My prior distribution gives median  . The delay parameter
. The delay parameter  for the probability of passing through all try-once steps. That is, if there are
for the probability of passing through all try-once steps. That is, if there are  then
then![\[w = P(w_1) \cdot P(w_2|w_1)\cdot \cdots P(w_l|w_1, w_2,...,w_{l-1}).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-d0a53cf526a5167b183d6dec7c457547_l3.png "Rendered by QuickLaTeX.com")
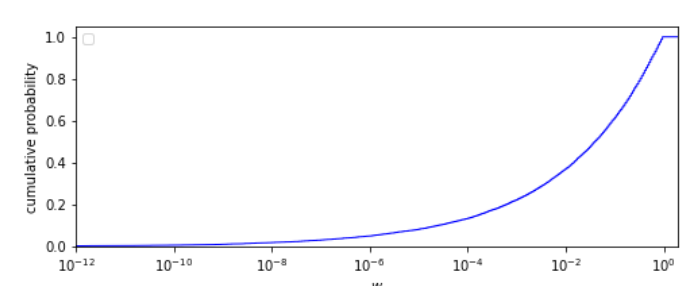
 . This allows for no try-once steps (
. This allows for no try-once steps ( ).
).
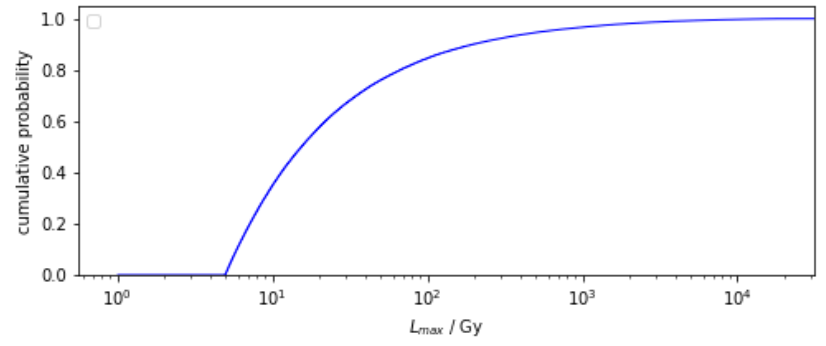
 , truncated to
, truncated to  . This prior disfavors the habitability of longer-lived stars. As I later show, this prior is mostly washed out by the anthropic update against the habitability of planets around longer-lived stars. In the appendix, I also consider variants of this prior.
. This prior disfavors the habitability of longer-lived stars. As I later show, this prior is mostly washed out by the anthropic update against the habitability of planets around longer-lived stars. In the appendix, I also consider variants of this prior. terrestrial planets around FGK stars and
terrestrial planets around FGK stars and  around M stars in the observable universe. Interpolating, I set the total number of terrestrial planets around stars that last up to
around M stars in the observable universe. Interpolating, I set the total number of terrestrial planets around stars that last up to ![\[T(L_{max}) = 5 \cdot 10^{18} \cdot (L_{max} \ \mathrm{in} \ Gy)^{0.5}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-0d73d31c81ce67daaedd06e64878a6e8_l3.png "Rendered by QuickLaTeX.com")
 for
for  and
and  for
for  . The fraction of planets formed at time
. The fraction of planets formed at time  .
. and
and  satisfy the property that for any
satisfy the property that for any , the expression
, the expression ![T(L_{max}) [H_{L_{max}}(L_2)-H_{L_{max}}(L_1)]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-d6d6927adc03b99acb7ca8811335ee2a_l3.png "Rendered by QuickLaTeX.com") - the number of planets per OUSV habitable for between
- the number of planets per OUSV habitable for between  with power
with power  and decay
and decay  where
where  .
.
 , (t) for three pairs of
, (t) for three pairs of  , with peak
, with peak  .
. and function
and function  which gives the fraction of habitable planets capable of hosting advanced life at time
which gives the fraction of habitable planets capable of hosting advanced life at time  and
and (hence
(hence  ). My prior on
). My prior on  , 0.99).
, 0.99).
![\[T(L_{max}) \cdot \gamma_u(t) \cdot \int_{0}^{t} \hat{\varrho}(b) \cdot [1-H_{L_{max}}(t-b)] \ \mathrm{d}b\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-718f93081a6cefa3a054a2621b9ecdde_l3.png "Rendered by QuickLaTeX.com")
 for
for  , the lower bound of the integral can be changed to
, the lower bound of the integral can be changed to  .
.![\[\alpha(t) = w \cdot \gamma_u(t) \cdot T(L_{max}) \cdot \int_{\max(0, t-L_{max})}^{t} f_{n,h,d}(t-b) \cdot \hat{\varrho}(b) \cdot[1-H(t-b)] \mathrm{d}b\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-a91f5703545b07d66cdbad7862e177a1_l3.png "Rendered by QuickLaTeX.com")
 after the process began
after the process began is the rate of habitable star formation at time
is the rate of habitable star formation at time  is the fraction of potentially habitable terrestrial planets that are habitable for at least
is the fraction of potentially habitable terrestrial planets that are habitable for at least  for the arrival time distribution
for the arrival time distribution  is the probability density of a randomly chosen (eventually) existing IC to have arrived at
is the probability density of a randomly chosen (eventually) existing IC to have arrived at 
 ,
,  ,
,  .. The left-hand plots have
.. The left-hand plots have  and right hand plots have
and right hand plots have  .
.
 and
and  and uses an anthropic theory that updates towards hypotheses where human civilization is more typical among all ICs. Given these assumptions, one expects the vast majority of ICs to appear much further into the future and on planets around red dwarf stars. However, human civilization arrived relatively shortly after the universe first became habitable, on a planet that is habitable for only a relatively short duration and is thus very atypical (according to our arrival time function that does not factor in the preclusion of ICs by other ICs.
and uses an anthropic theory that updates towards hypotheses where human civilization is more typical among all ICs. Given these assumptions, one expects the vast majority of ICs to appear much further into the future and on planets around red dwarf stars. However, human civilization arrived relatively shortly after the universe first became habitable, on a planet that is habitable for only a relatively short duration and is thus very atypical (according to our arrival time function that does not factor in the preclusion of ICs by other ICs. for the rate of ICs per OUSV with feature
for the rate of ICs per OUSV with feature  where
where ![\[N_{XIC} \propto w \cdot \gamma_u(t) \cdot f_{n,h,d} (4.5 \ Gy).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-36a935ad46220e6ecdf0902ce8e5de56_l3.png "Rendered by QuickLaTeX.com")
 ,
, the number of ICs with feature
the number of ICs with feature  for the rate of ICs that appear per OUSV, supposing no IC precludes any other, which is given by
for the rate of ICs that appear per OUSV, supposing no IC precludes any other, which is given by  .
.
 is not the probability that there is less than one IC per OUSV. This latter probability is approximately
is not the probability that there is less than one IC per OUSV. This latter probability is approximately  .
. , the rate of ICs per OUSV that have arrived at the same time as human civilization on a planet habitable for the same duration and do not observe any GCs.
, the rate of ICs per OUSV that have arrived at the same time as human civilization on a planet habitable for the same duration and do not observe any GCs. for the average fraction of ICs that become GCs.
for the average fraction of ICs that become GCs. .
.
 truncated to
truncated to  .
.
 truncated to
truncated to  . This distribution prior has a median
. This distribution prior has a median  and is informed by Armstrong
and is informed by Armstrong  Sandberg (2013) considerations of designs for self-replicating probes that travel at speeds
Sandberg (2013) considerations of designs for self-replicating probes that travel at speeds  and
and  .
. , a function that describes the expansion of the universe over time.
, a function that describes the expansion of the universe over time.![\[a'(t)^2 = H_0\cdot (\Omega_m \cdot a(t)^{-1} + \Omega_r \cdot a(t)^{-2} + \Omega_\Lambda a(t)^2),\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-6b640d6603bd28c22f3bf7093249fc06_l3.png "Rendered by QuickLaTeX.com")
 and
and  ,
,  ,
,  and
and  given by Ade et al. (2016). The Friedmann equation assumes the universe is homogeneous and isotropic, as discussed in Chapter 1.
given by Ade et al. (2016). The Friedmann equation assumes the universe is homogeneous and isotropic, as discussed in Chapter 1.
 .The comoving volume of a GC at time
.The comoving volume of a GC at time ![\[V(b,t,v) = \frac{4\pi}{3} \cdot \left(\int_b^t \frac{v}{a(t')} \mathrm{d}t'\right)^3.\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-82f26326a95bb104ad1d73463623e40c_l3.png "Rendered by QuickLaTeX.com")
 in units of fraction of the volume of an OUSV, approximately
in units of fraction of the volume of an OUSV, approximately  .
.
 delaying colonization by 100 years results in about 0.0000019% loss of volume. Due to the clumping of stars in galaxies and galaxies in clusters, it’s possible this results in no loss of useful volume.
delaying colonization by 100 years results in about 0.0000019% loss of volume. Due to the clumping of stars in galaxies and galaxies in clusters, it’s possible this results in no loss of useful volume. for the average fraction of OUSVs unsaturated by GCs at time
for the average fraction of OUSVs unsaturated by GCs at time ![\[g(t) = e^{-\int_0^t f_{GC} \cdot \alpha(b) \cdot V(b,t) \mathrm{d}b}.\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-da5d003f57794c4f9808d5165cdd9f25_l3.png "Rendered by QuickLaTeX.com")
 is the rate of GCs appearing per OUSV at time
is the rate of GCs appearing per OUSV at time  is a function of the parameters
is a function of the parameters 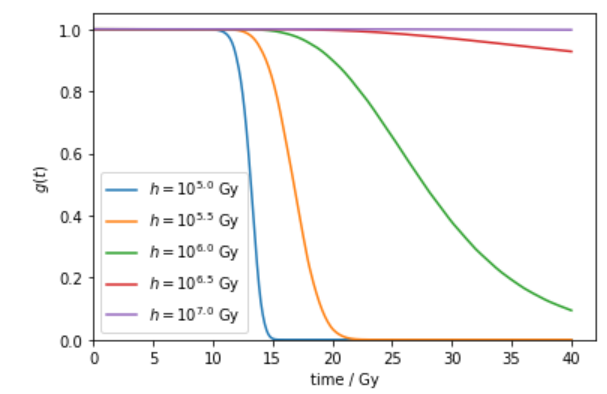
 ,
,  ,
,  ,
,  ,
,  ,
,  and varying
and varying 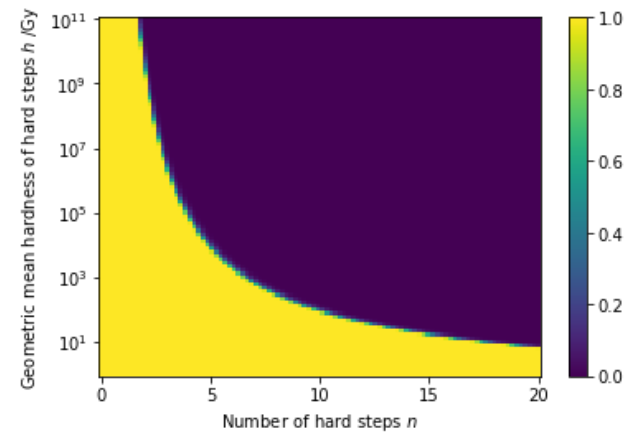
 ,
,  ,
,  and
and  . Only for a small fraction of pairs
. Only for a small fraction of pairs  is the eventual fraction of OUSVs saturated by GCs is neither very close to 0 nor exactly 1.
is the eventual fraction of OUSVs saturated by GCs is neither very close to 0 nor exactly 1. for the expected actual volume of a GC at time
for the expected actual volume of a GC at time  since GCs that prevent expansion can only decrease the actual volume. If GCs are sufficiently rare, then
since GCs that prevent expansion can only decrease the actual volume. If GCs are sufficiently rare, then  . I derive an approximation for
. I derive an approximation for  in the appendix.
in the appendix.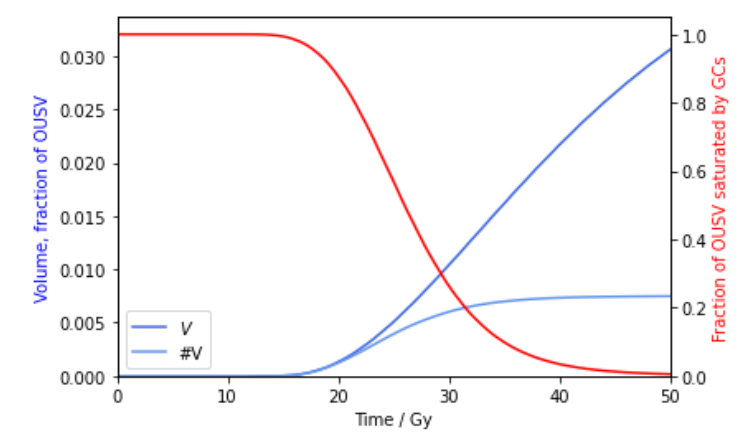
 to
to  ,
, ,
,  ,
,  ,
,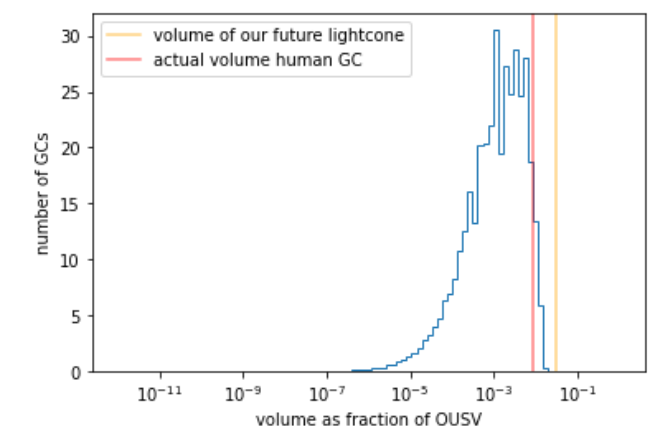
 that gives the rate of ICs appearing per OUSV, and write
that gives the rate of ICs appearing per OUSV, and write  for the number of ICs that actually appear per OUSV.
for the number of ICs that actually appear per OUSV.
 for
for  ,
,  ,
,  ,
, 
 ,
, 
 with the same parameters as above (these are just the graphs to the above but each rescaled).
with the same parameters as above (these are just the graphs to the above but each rescaled).
 varying
varying  ,
,  for the rate of ICs with feature X per OUSV that do not observe GCs. Since information about GCs travels at the speed of light,
for the rate of ICs with feature X per OUSV that do not observe GCs. Since information about GCs travels at the speed of light,  gives the fraction of OUSVs that is unsaturated by light from GCs at time
gives the fraction of OUSVs that is unsaturated by light from GCs at time  gives the number of XICs per OUSV with no GCs in their past light cone.
gives the number of XICs per OUSV with no GCs in their past light cone.
 .
.
 and
and  ) respectively.
) respectively. or observation I label
or observation I label  . Both
. Both  after the Big Bang
after the Big Bang![\[P(n,h,d,w,L_{max}, u, f_{GC}, v | X) \propto P(X|n,\dots, v) \cdot P(n, \dots ,v).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-f50761ed528a7d10d56c7f68d29b497f_l3.png "Rendered by QuickLaTeX.com")
 and so it remains to calculate the likelihood P(X|n, ..., v). I derive likelihoods in the discrete case, and index my priors by worlds
and so it remains to calculate the likelihood P(X|n, ..., v). I derive likelihoods in the discrete case, and index my priors by worlds  .
.![\[P_{SIA}(X|W_i) = \frac{|XOMs|_i}{\sum_{j} |OMs|_j} \propto |XOMs|_i.\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-58c6f27cca73808ed0ac5f7f3b1d5360_l3.png "Rendered by QuickLaTeX.com")
 .
.
 .
.
![\[P_{SSA, R}(X|W_i) = \frac{|RXOMS|_i}{|ROMs|_i}.\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-bc10a9ebc772cba134d51610901c486a_l3.png "Rendered by QuickLaTeX.com")
 and
and  . The reference class
. The reference class  . As in the SIA case, the number of XOMs is proportional to
. As in the SIA case, the number of XOMs is proportional to  .
.
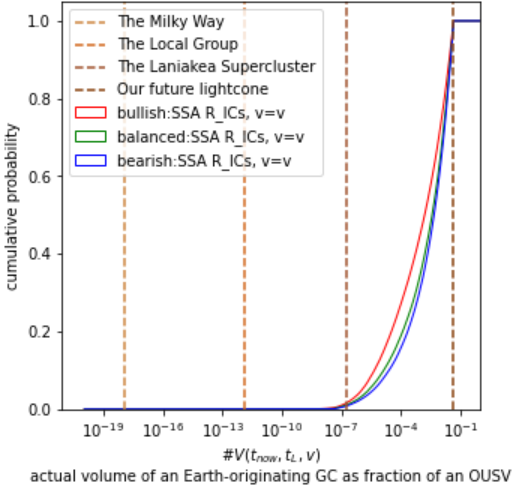
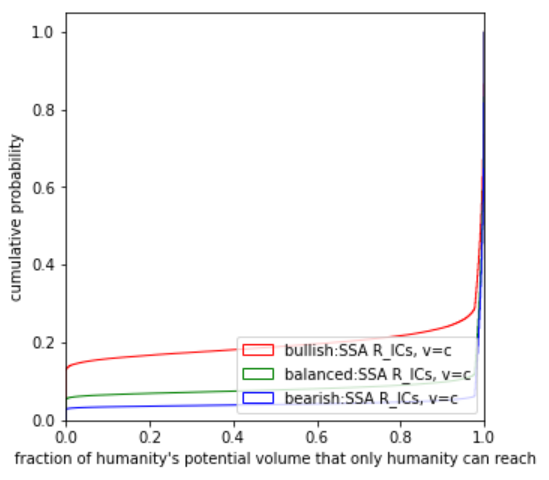
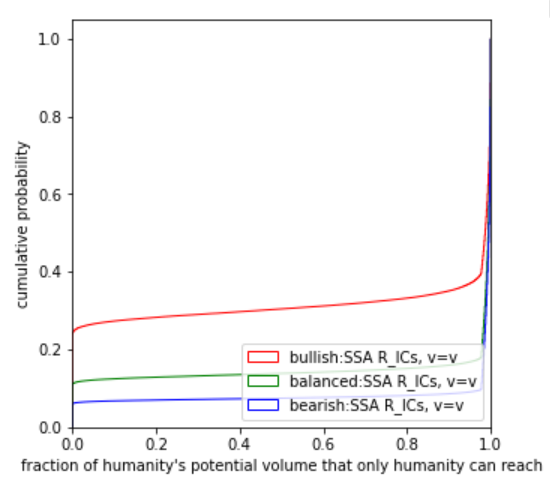
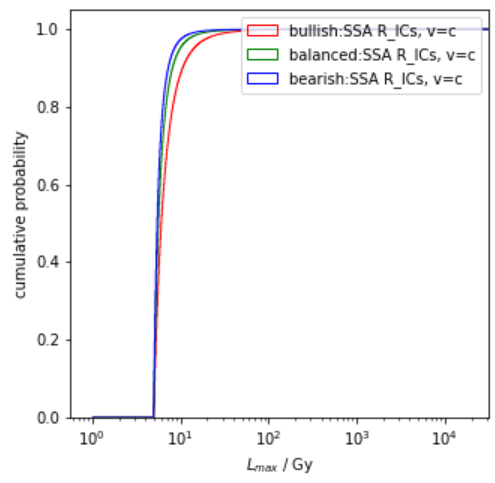
 , the average fraction of OUSVs saturated by GCs at some time
, the average fraction of OUSVs saturated by GCs at some time  when all expansion has finished
when all expansion has finished![\# N_{XIC}/[1-g(t_L)]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-ad888693a750cb61f092eda27f467054_l3.png "Rendered by QuickLaTeX.com") .
.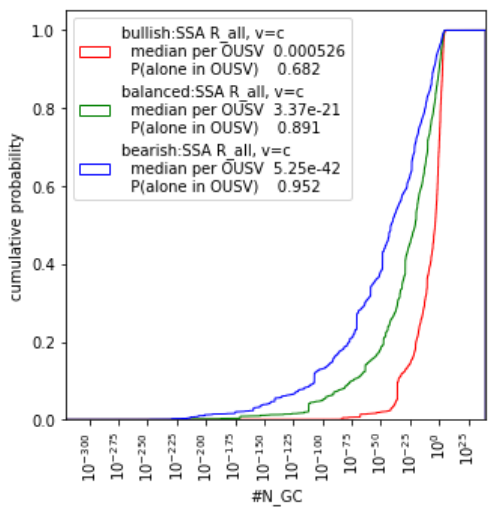
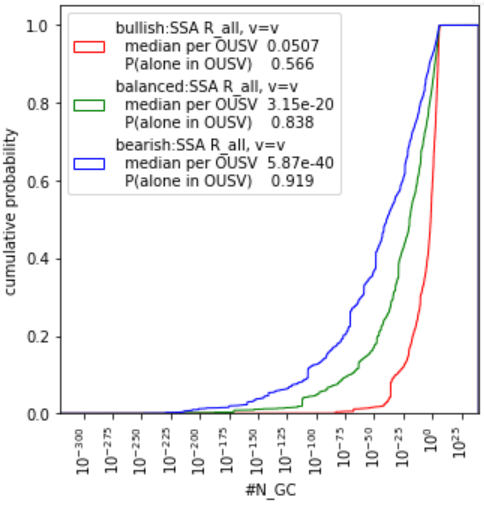
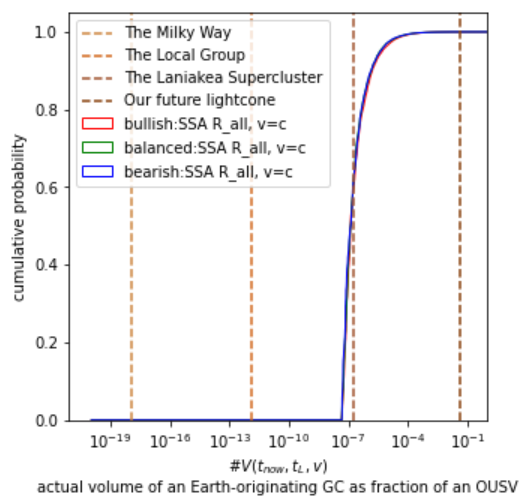
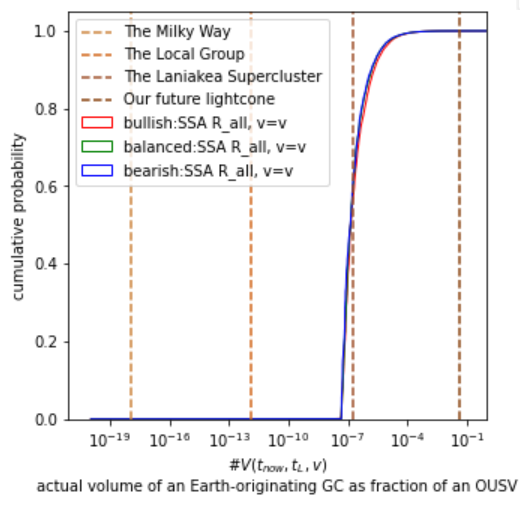
 ) paired with a non-causal decision theory, such as evidential decision theory (EDT). SSA
) paired with a non-causal decision theory, such as evidential decision theory (EDT). SSA  and in (2)
and in (2) 
 . Using the assumption that our influence is linear in resources, the decision worthiness of each world is
. Using the assumption that our influence is linear in resources, the decision worthiness of each world is![\[f_{GC} \cdot \# N_{XIC} \cdot \# V(t_{now}, t_{L},v).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-96a024558dcbc9491e314a10d6d87ecf_l3.png "Rendered by QuickLaTeX.com")
 The resources of all GCs is proportional to
The resources of all GCs is proportional to ![\[f_{GC} \cdot \# N_{XIC} \cdot \# V(t_{now}, t_{L},v) \cdot [1-g(t_L)]^{-1}.\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-a2497db14151457138f36de03e36ce5b_l3.png "Rendered by QuickLaTeX.com")
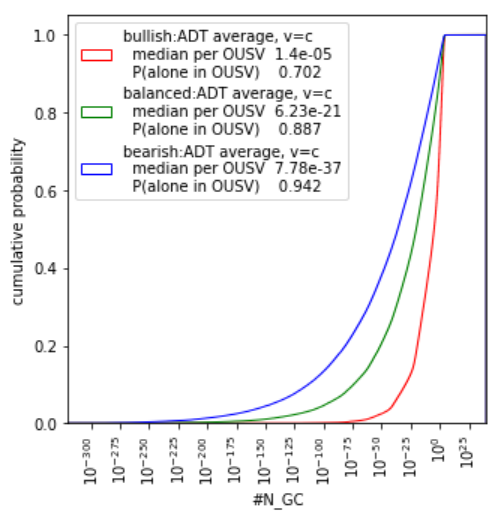
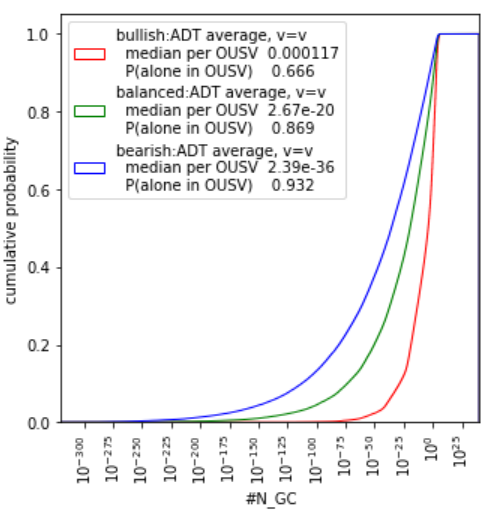
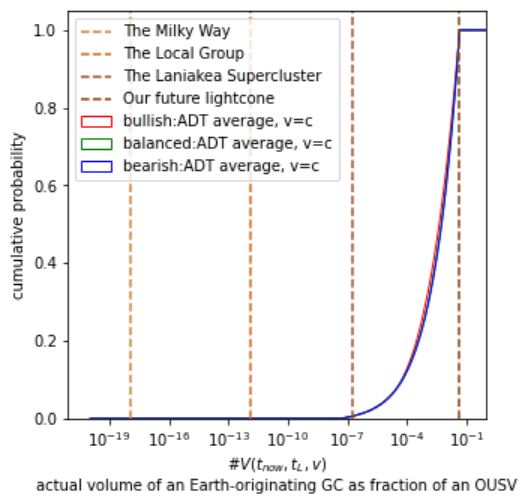
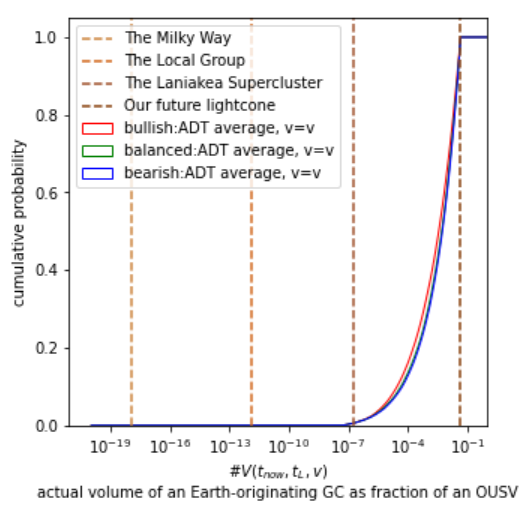
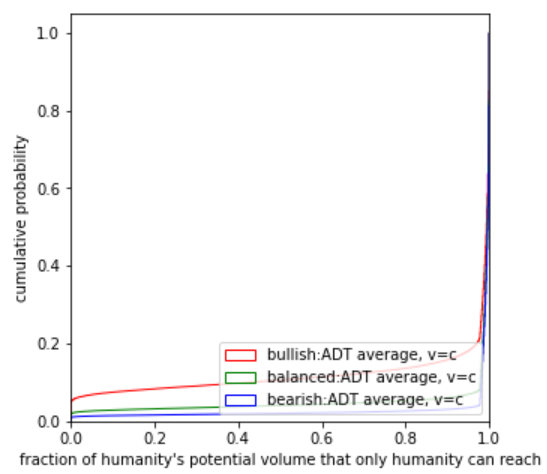
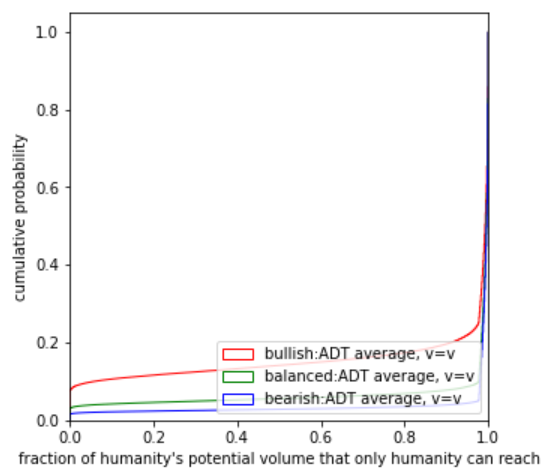
![\# V(t_{now},t_L,v) \cdot [1-g(t_L)]^{-1}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-235845bcc8db630dc5b0fb07d991500b_l3.png "Rendered by QuickLaTeX.com")
 . Supposing a total utilitarian’s decisions can influence both cases equally, the expected decision-worthiness per copy in an IC that becomes a GC is
. Supposing a total utilitarian’s decisions can influence both cases equally, the expected decision-worthiness per copy in an IC that becomes a GC is![\[p \cdot \# V(t_{now}, t_L, v) + (1-p) \cdot \frac{\# V(t_{now}, t_L, v)}{1-g(t_L)} \cdot V(t_{now}, t_L, v).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-b4a91ba3e5aecb289a995c598d3ba541_l3.png "Rendered by QuickLaTeX.com")
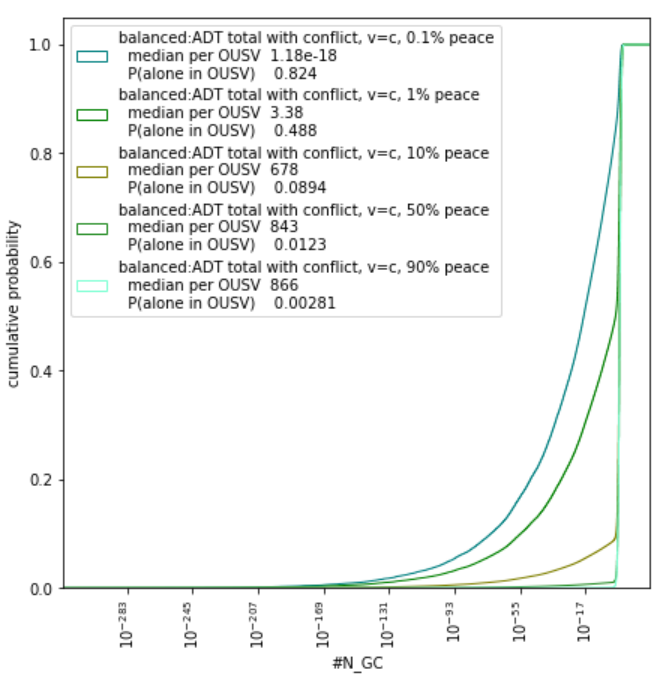
 moral patients to be increased by one unit. For
moral patients to be increased by one unit. For  the GC benefits by making the trade, and so should always make such a trade rather than using the resources to create utility themselves. I write
the GC benefits by making the trade, and so should always make such a trade rather than using the resources to create utility themselves. I write  for the probability density of a randomly chosen trade providing
for the probability density of a randomly chosen trade providing  for some
for some  . For smaller
. For smaller  , a greater proportion of all available trades are beneficial, and a greater number are very beneficial. For example, for k=1 the fraction of the volume controlled by GCs that the average utilitarian GC can make beneficial trades with is
, a greater proportion of all available trades are beneficial, and a greater number are very beneficial. For example, for k=1 the fraction of the volume controlled by GCs that the average utilitarian GC can make beneficial trades with is and
and  of volume controlled by GCs allows for trades that return twice as much as they put in. For
of volume controlled by GCs allows for trades that return twice as much as they put in. For  these same terms are
these same terms are and
and respectively.
respectively.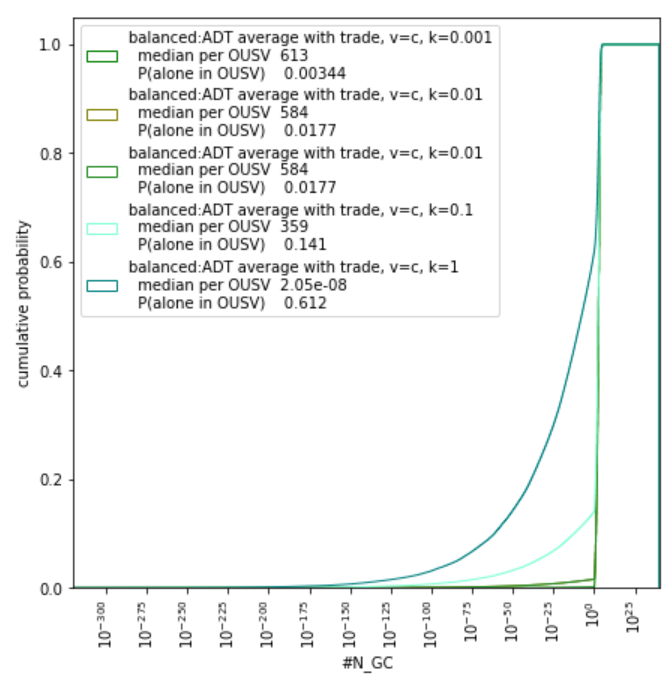
 human lives per second, each containing many OMs. Around
human lives per second, each containing many OMs. Around  humans have ever lived: if we expect a GC to emerge in the few centuries, it seems unlikely more than 1012 humans will have lived by this time. In this case, only
humans have ever lived: if we expect a GC to emerge in the few centuries, it seems unlikely more than 1012 humans will have lived by this time. In this case, only  (one hundred million trillionths) of all a GC’s resources would need to be used for a single second to create an equal number of XOMs to the number of basement-level XOMs.
(one hundred million trillionths) of all a GC’s resources would need to be used for a single second to create an equal number of XOMs to the number of basement-level XOMs. by
by  , this means one can approximate all XOMs as contained in AS.
, this means one can approximate all XOMs as contained in AS. . Each creates some average number of HS each containing some average constant number of XOMs.
. Each creates some average number of HS each containing some average constant number of XOMs.



![\frac{\#N_XIC}{\# N_{IC}} \cdot [1-g(t_L)]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-4d95abb41aed2c1bcea149d4bc764751_l3.png "Rendered by QuickLaTeX.com")
 will be of XICs.
will be of XICs.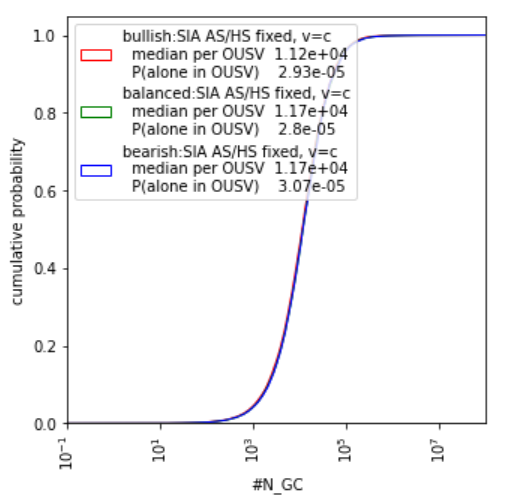
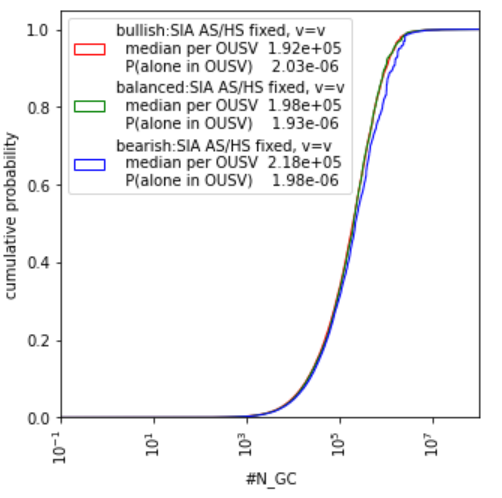
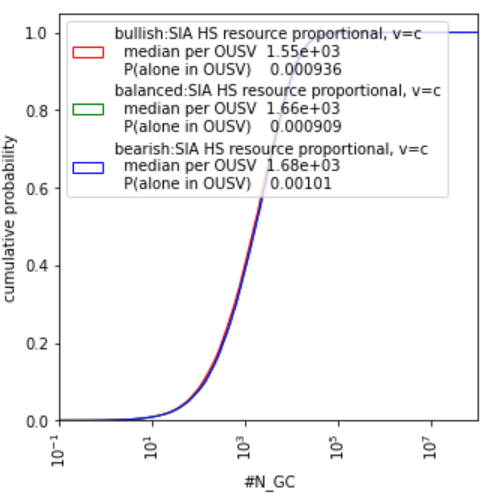
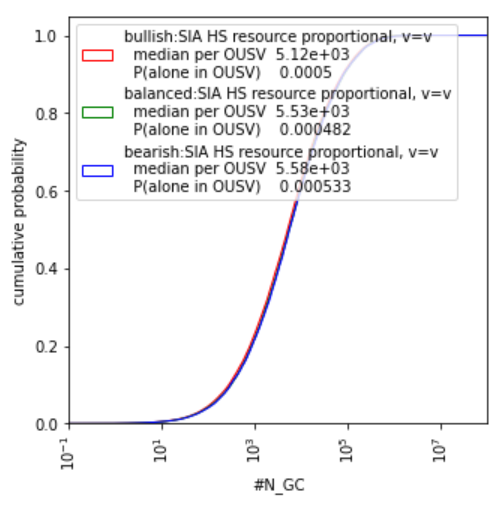

 biological human lives lost per second of delayed colonization, due to the finite lifetimes of stars. This estimate further does not include stars that become impossible for a human civilization due to the expansion of the universe.
biological human lives lost per second of delayed colonization, due to the finite lifetimes of stars. This estimate further does not include stars that become impossible for a human civilization due to the expansion of the universe.





 for this reference class. Throughout, I ignore delay steps, and include only hard try-try steps.
for this reference class. Throughout, I ignore delay steps, and include only hard try-try steps. . The SSA
. The SSA ![\[\frac{f_{n,h}(4.5 \ Gy)}{\int_0^{5 \ Gy} f_{n,h}(t) \mathrm{d} t }\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-2ff189ac9d184192e5892c746b2c2cf5_l3.png "Rendered by QuickLaTeX.com")
 is the Gamma distribution PDF with shape
is the Gamma distribution PDF with shape  . This likelihood ratio is largest for
. This likelihood ratio is largest for  . We could further condition on the time that life first appeared, but this is not necessary to illustrate the point.
. We could further condition on the time that life first appeared, but this is not necessary to illustrate the point.
![\[\frac{f_{n,h}(4.5 \ Gy)}{\int_{5 \ Gy}^{L_{max}} K(L) \cdot \int_0^L f_{n,h}(t) \mathrm{d} t \ \mathrm{d} L}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-b77f45ac00d810f8fa127500bf51270e_l3.png "Rendered by QuickLaTeX.com")
 is the 'number' of planets habitable for
is the 'number' of planets habitable for 
 and is decreasing in
and is decreasing in  .
. and max planet duration <50Gyr. That is, we seem early.
and max planet duration <50Gyr. That is, we seem early. which has
which has  , SSA
, SSA  . As seen below, increasing the lower bound on the prior of
. As seen below, increasing the lower bound on the prior of 
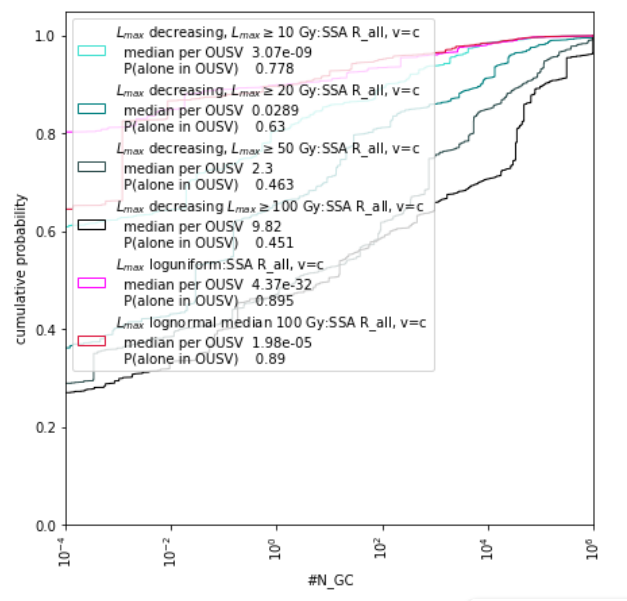
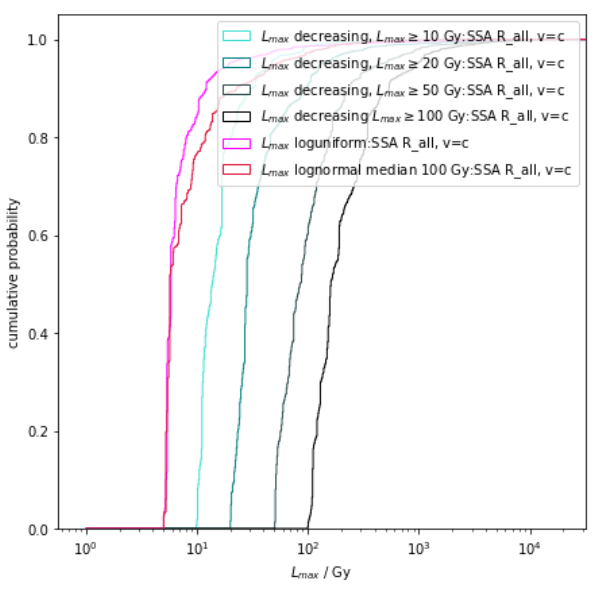
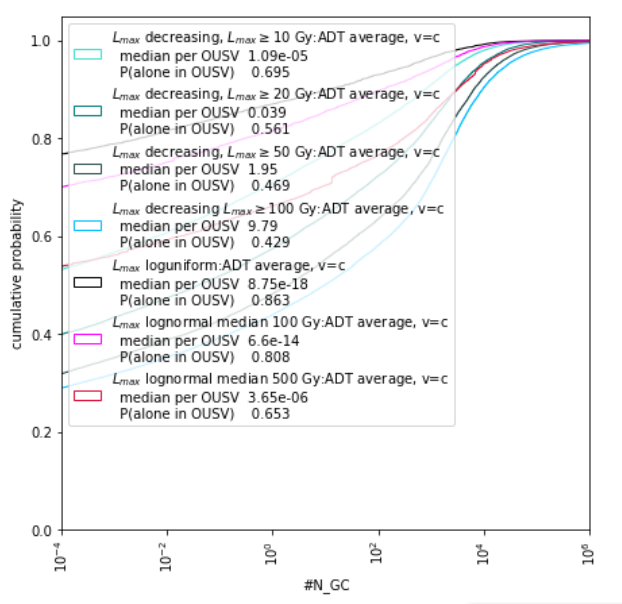
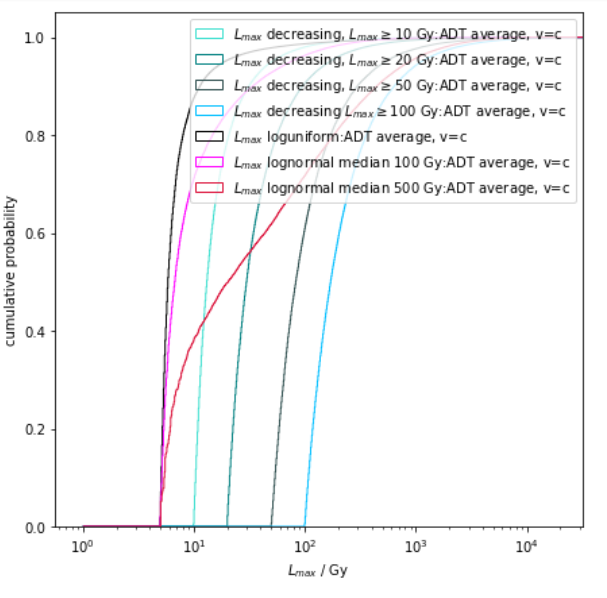
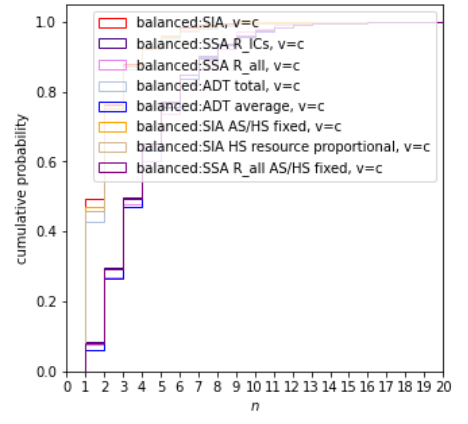
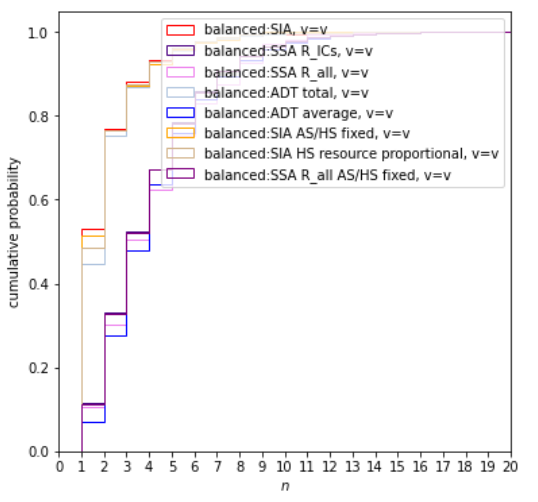
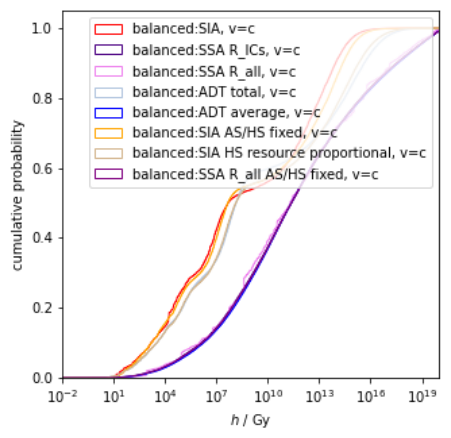
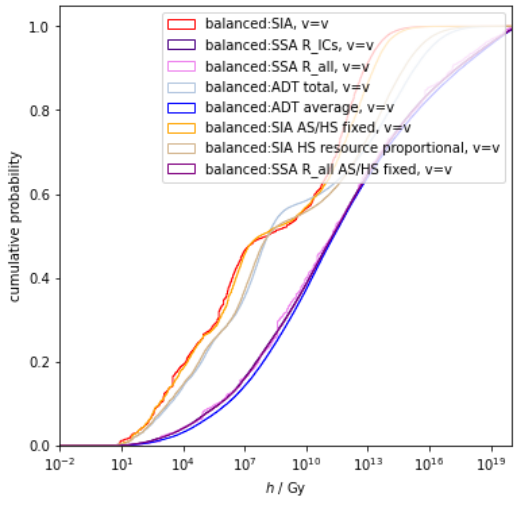
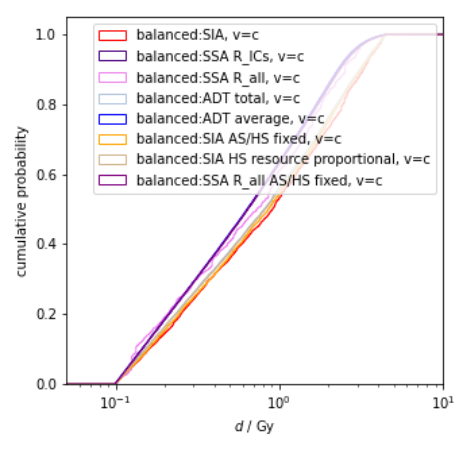
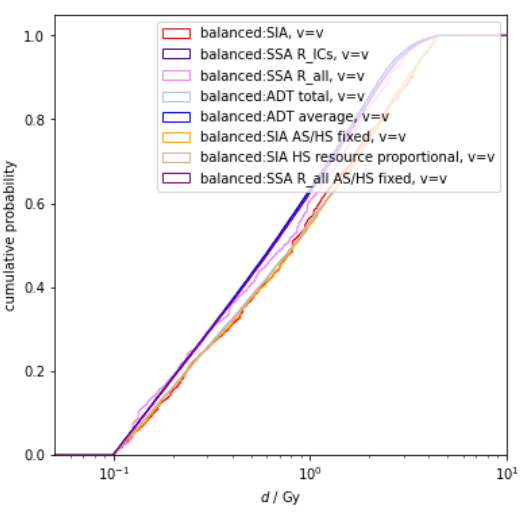
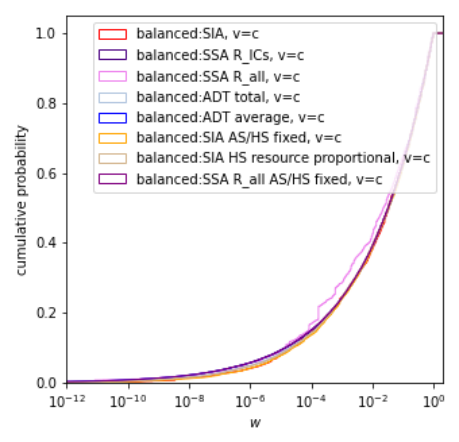
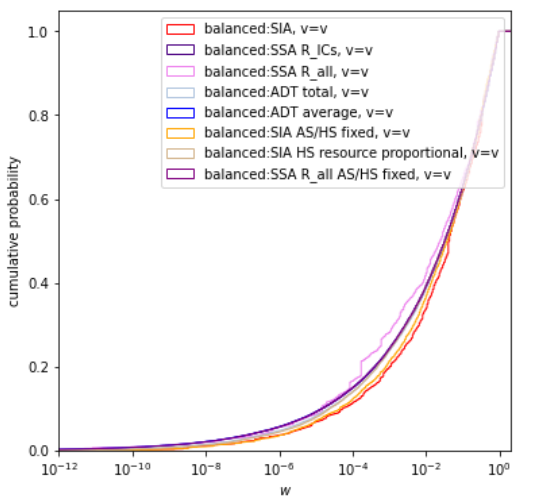

 not conditioned on the value of n
not conditioned on the value of n
 . I also run with
. I also run with  below
below


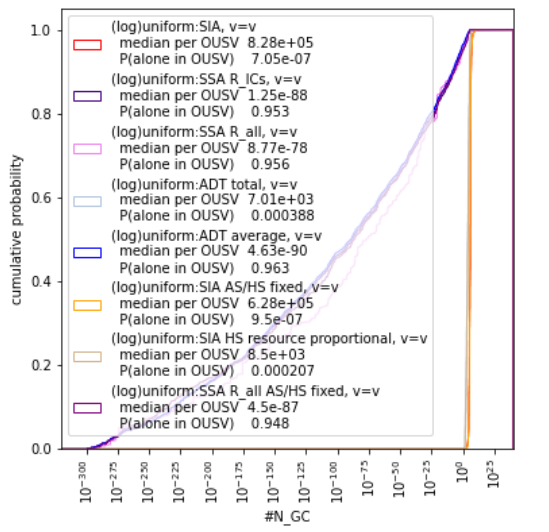
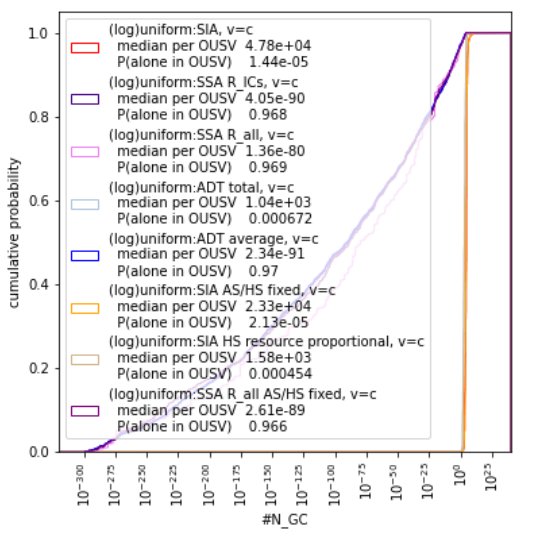
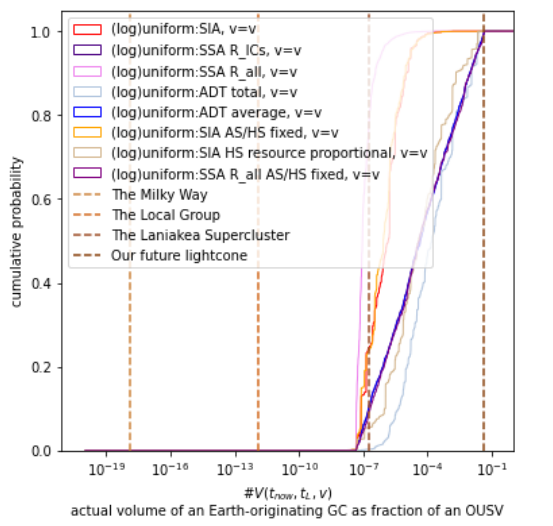
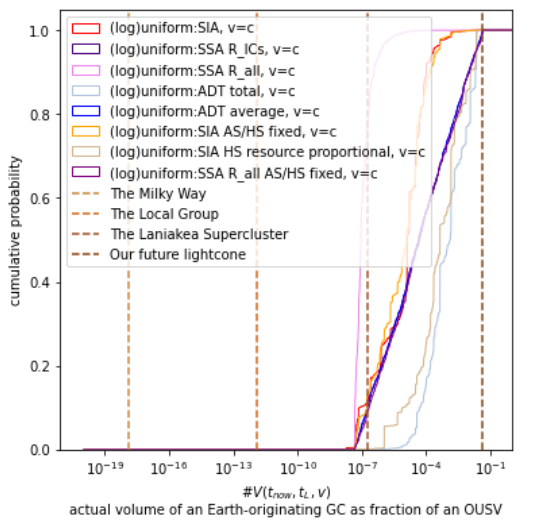
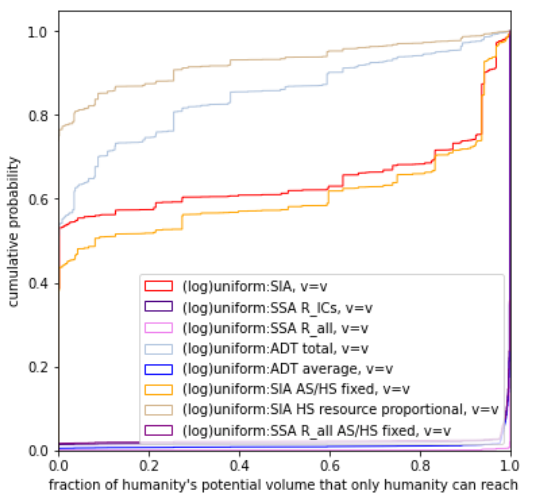
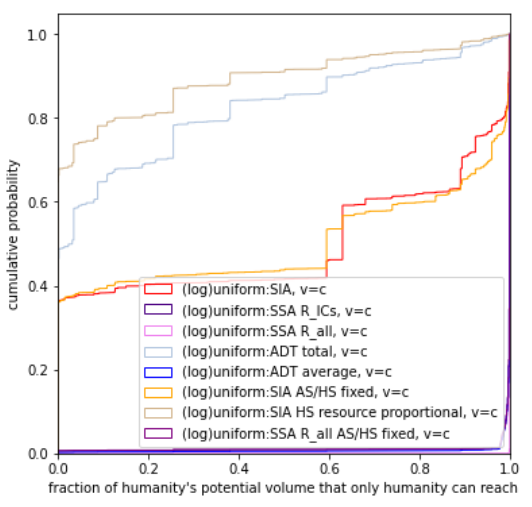
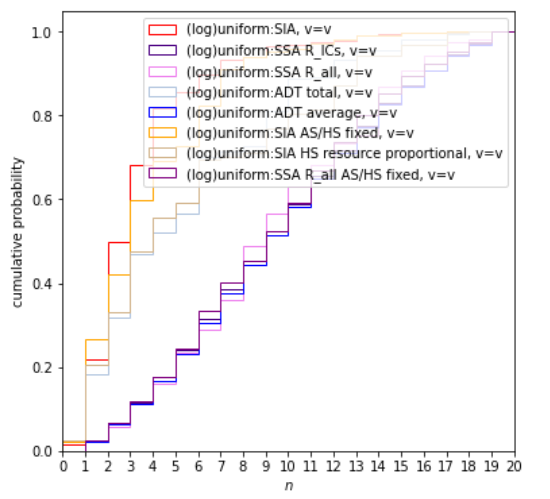
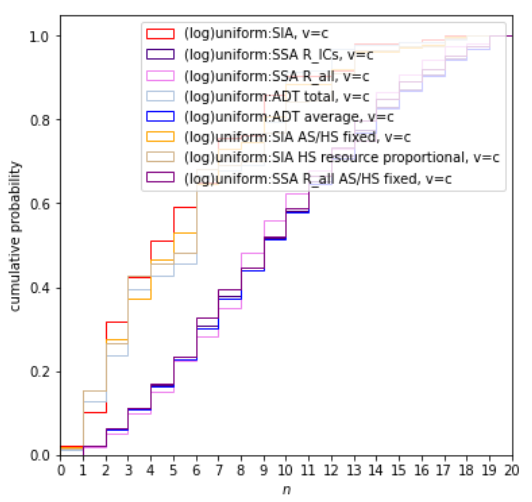
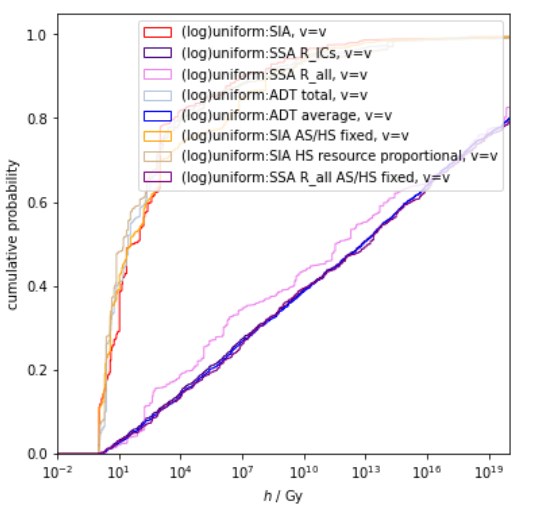
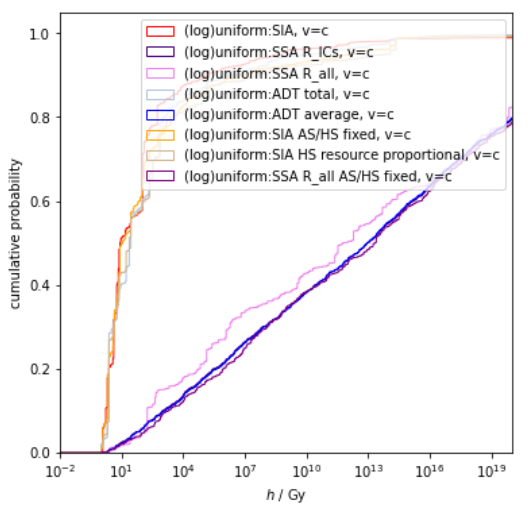
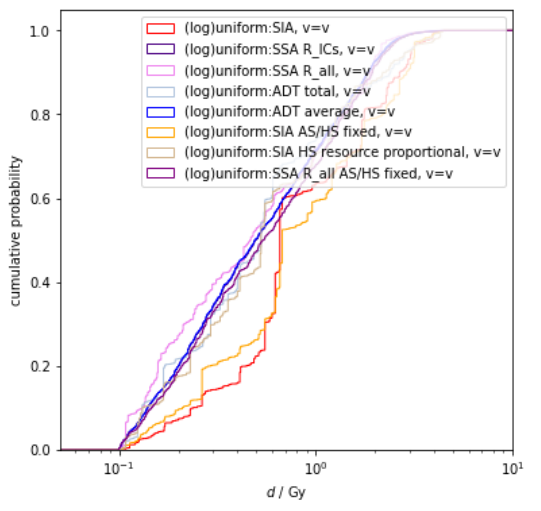
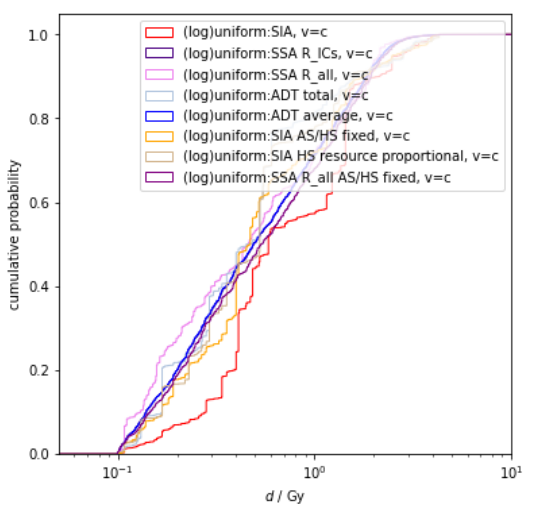
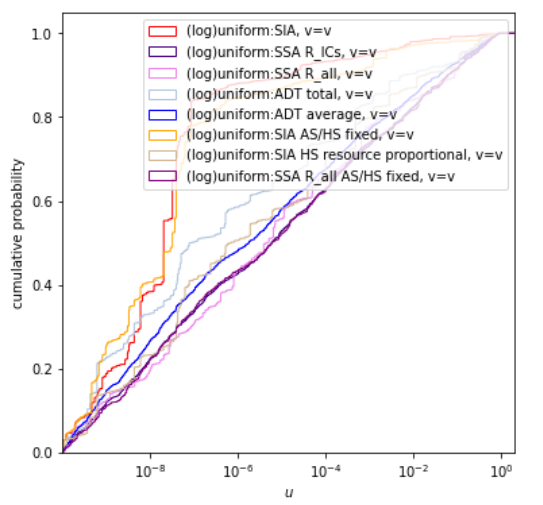
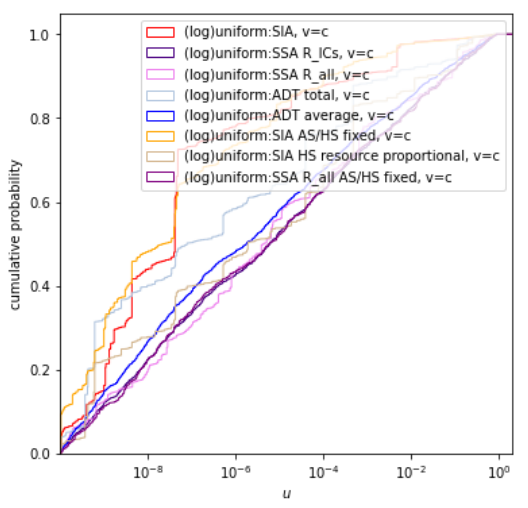
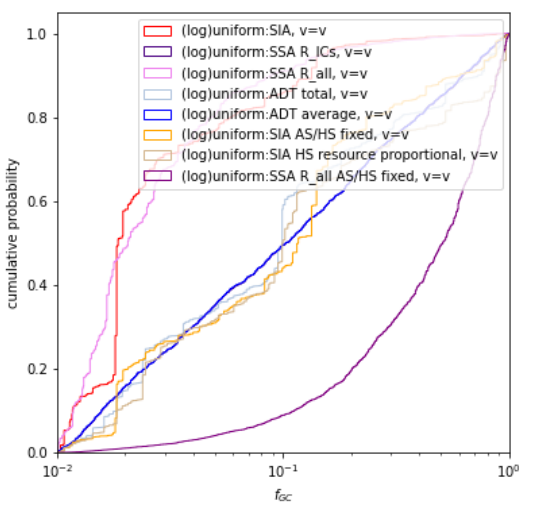
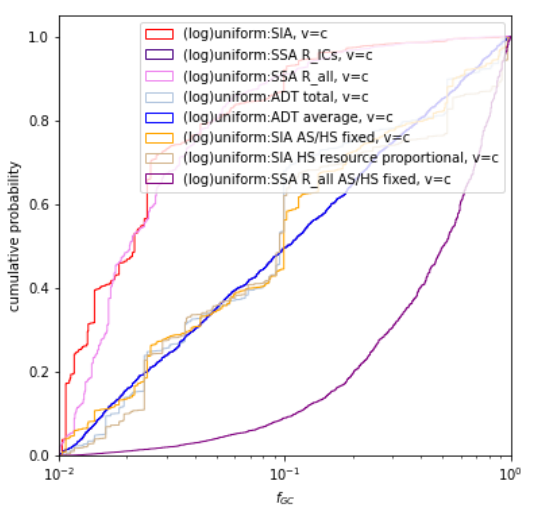

 for the fraction of ICs that trigger a vacuum decay some time shortly after they become an IC. More relevantly, one may consider vacuum decay events being triggered when GCs meet one another.
for the fraction of ICs that trigger a vacuum decay some time shortly after they become an IC. More relevantly, one may consider vacuum decay events being triggered when GCs meet one another.
 ,
,  ,
,  ,
, 
 and
and  , around 50% of the OUSVs on average will be eventually consumed by vacuum decay bubbles travelling at the speed of light.
, around 50% of the OUSVs on average will be eventually consumed by vacuum decay bubbles travelling at the speed of light. and so would similarly support the existence of ICs that trigger false vacuum decay as a deadline.
and so would similarly support the existence of ICs that trigger false vacuum decay as a deadline.![\[f_{n,h}(t) = \frac{1}{\Gamma(n)} \cdot \frac{1}{h^n} \cdot t^{n-1} \cdot \exp(-t/h)\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-d018146d5dbd41e37ce030997fdac18a_l3.png "Rendered by QuickLaTeX.com")
 ,
,  and so
and so  . That is, when the steps are sufficiently hard, the probability of completion grows as a polynomial in
. That is, when the steps are sufficiently hard, the probability of completion grows as a polynomial in 
 and CDF (blue) grows approximately
and CDF (blue) grows approximately  .
. greater probability of life appearing than a planet habitable for 5 Gy.
greater probability of life appearing than a planet habitable for 5 Gy.![\[\begin{array}{ccc} \textbf{Julian Stastny} & &\textbf{Maxime Riché}\\ \text{University of Tuebingen} & &\text{Center on Long-Term Risk}\\ \texttt{julianstastny@gmail.com} & &\texttt{maxime.riche@longtermrisk.org}\\ & & \\ \textbf{Alexander Lyzhov} & &\textbf{Johannes Treutlein}\\ \text{Center on Long-Term Risk} & &\text{Vector Institute}\\ \text{Now at New York University} & & \text{University of Toronto} \\ \texttt{alex.grig.lyzhov@gmail.com} & & \texttt{treutlein@cs.toronto.edu} \\ & & \\ \textbf{Allan Dafoe} & &\textbf{Jesse Clifton}\\ \text{DeepMind} & &\text{Center on Long-Term Risk}\\ \texttt{allandafoe@deepmind.com} & &\texttt{jesse.clifton@longtermrisk.org}\\ \end{array}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-26e211bfe7decdea311dab37d9dd106b_l3.png "Rendered by QuickLaTeX.com")
 — can be seen as a more general variant of an approach proposed by Boutilier [1999] for coordinating in pure coordination games. As it implicitly searches for overlap in the agents’ sets of allowed welfare functions, it is also similar to Rosenschein and Genesereth [1988]’s approach to reaching agreement in general-sum games via sets of proposals by each agent.
— can be seen as a more general variant of an approach proposed by Boutilier [1999] for coordinating in pure coordination games. As it implicitly searches for overlap in the agents’ sets of allowed welfare functions, it is also similar to Rosenschein and Genesereth [1988]’s approach to reaching agreement in general-sum games via sets of proposals by each agent. . There is a space
. There is a space  which evolve according to a Markovian transition function
which evolve according to a Markovian transition function  . At each time step, each player sees an observation
. At each time step, each player sees an observation  which depends on
which depends on  . We refer to the set of all histories for player
. We refer to the set of all histories for player  and assume for simplicity that the initial observation history is fixed and common knowledge:
and assume for simplicity that the initial observation history is fixed and common knowledge:  . Finally, principals choose among policies
. Finally, principals choose among policies  , which we imagine as artificial agents deployed by the principals. We will refer to policy profiles generically as
, which we imagine as artificial agents deployed by the principals. We will refer to policy profiles generically as  .
.
 , whereas playing SS maximizes the egalitarian welfare
, whereas playing SS maximizes the egalitarian welfare  subject to
subject to  Pareto-optimal. Throwing a correlated fair coin to choose between the two would lead to an expected payoff that is optimal with respect to the Nash welfare
Pareto-optimal. Throwing a correlated fair coin to choose between the two would lead to an expected payoff that is optimal with respect to the Nash welfare  . Each of these different equilibria has a normative principle to motivate it.
. Each of these different equilibria has a normative principle to motivate it. differs across games.
differs across games. , where
, where  are normative policies (i.e., those which comply with the norm);
are normative policies (i.e., those which comply with the norm);  are “punishment” policies, which are enacted when deviations from a normative policy are detected; and
are “punishment” policies, which are enacted when deviations from a normative policy are detected; and  . A policy
. A policy  is compatible with norm
is compatible with norm  ,
,
 (this is the normative policy), and for a player to respond to deviations by continuing to play
(this is the normative policy), and for a player to respond to deviations by continuing to play  are chosen such that players are made worse off by deviating than by continuing to play according to the normative policy profile.
are chosen such that players are made worse off by deviating than by continuing to play according to the normative policy profile. for that game. Let
for that game. Let  be a surjective function that maps histories of observations to norms (i.e., for each norm in
be a surjective function that maps histories of observations to norms (i.e., for each norm in  chooses that norm.) Then, a policy
chooses that norm.) Then, a policy  is norm-adaptive if, for all
is norm-adaptive if, for all  and
and  .
. Note that although
Note that although  is maximized by both players always consuming the Cooperation coin, however, this will make one player benefit more than the other. Due to the sequential nature of the game, this means that welfare functions which also care about (in)equity will favor an equilibrium in which the player who benefits less from the Cooperation coin is allowed to consume the Disagreement coin from time to time without retaliation.
is maximized by both players always consuming the Cooperation coin, however, this will make one player benefit more than the other. Due to the sequential nature of the game, this means that welfare functions which also care about (in)equity will favor an equilibrium in which the player who benefits less from the Cooperation coin is allowed to consume the Disagreement coin from time to time without retaliation.
 (see Appendix
(see Appendix  to be the set of welfare functions which we use in our experiments in the environment in question. For instance, for IAsymBoS and
to be the set of welfare functions which we use in our experiments in the environment in question. For instance, for IAsymBoS and  . Second, we define disagreement payoff profiles
. Second, we define disagreement payoff profiles  corresponding to cooperation failure; in IAsymBoS the disagreement policy profile would be the one which has payoff profile
corresponding to cooperation failure; in IAsymBoS the disagreement policy profile would be the one which has payoff profile  . Then, for a policy profile
. Then, for a policy profile  . Under this scoring method, players do maximally well when they play a policy profile which is optimal according to some welfare function in
. Under this scoring method, players do maximally well when they play a policy profile which is optimal according to some welfare function in 

 . This is not necessarily bad – we claim that normative disagreement should be treated differently to defection – but it does mean that
. This is not necessarily bad – we claim that normative disagreement should be treated differently to defection – but it does mean that  . The agent starts out playing according to some
. The agent starts out playing according to some  . The initial choice can be made at random or according to a preference ordering between the
. The initial choice can be made at random or according to a preference ordering between the 
 . The legend shows various combinations of sets
. The legend shows various combinations of sets  and
and  . Coordination failure only occurs when
. Coordination failure only occurs when  .
. . More generally, an agent who puts higher probability on a welfare function it has a preference for, when re-sampling
. More generally, an agent who puts higher probability on a welfare function it has a preference for, when re-sampling  and showed in experiments that this tends to improve robustness to normative disagreement. On the other hand, we have demonstrated a robustness-exploitability tradeoff, under which methods that learn more normatively flexible strategies are also more vulnerable to exploitation.
and showed in experiments that this tends to improve robustness to normative disagreement. On the other hand, we have demonstrated a robustness-exploitability tradeoff, under which methods that learn more normatively flexible strategies are also more vulnerable to exploitation. are bargaining over the policy profile
are bargaining over the policy profile  the disagreement value, is the value which player
the disagreement value, is the value which player 
![\left[V_1(\pi) - d_1 \right] \cdot \left[ V_2(\pi) - d_2 \right]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-2e9d26dfecad474f3338c13e5a49ca75_l3.png "Rendered by QuickLaTeX.com")
 s.t. Pareto-optimal
s.t. Pareto-optimal s.t. Pareto-optimal
s.t. Pareto-optimal


 if the other player picks up their coin. This creates a social dilemma in which the socially optimal behavior is to only get one’s own coin, but there is incentive to defect and try to get the other player’s coin as well.
if the other player picks up their coin. This creates a social dilemma in which the socially optimal behavior is to only get one’s own coin, but there is incentive to defect and try to get the other player’s coin as well.
 for all the algorithms and environments unless specified otherwise in Table 4.
for all the algorithms and environments unless specified otherwise in Table 4.![\begin{equation*} \begin{aligned} w^{\mathrm{IA}}(\pi) = V_1(\pi) + V_2(\pi) - \beta\cdot \mathbb{E} \left[ \lvert e^t_1(h^t_1, h^t_2) - e^t_2(h^t_1, h^t_2) \rvert \right] \end{aligned} \end{equation*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-fa5c42b5e33a52a66c413bb40de40fe0_l3.png "Rendered by QuickLaTeX.com")
 are smoothed cumulative rewards with a discount factor
are smoothed cumulative rewards with a discount factor  as the value to player
as the value to player  . Then, the LOLA update [Foerster et al., 2018] for player 1 at time
. Then, the LOLA update [Foerster et al., 2018] for player 1 at time  is
is![\begin{equation*} \theta^t_1 = \theta^{t-1}_1+ \delta \nabla_{\theta_1} V_i(\theta_1, \theta_2) + \delta \eta\left[ \nabla_{\theta_2} V_1(\theta_1, \theta_2) \right]^{^{\sf T}}\nabla_{\theta_1} \nabla_{\theta_2} V_2(\theta_1, \theta_2). \end{equation*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-41d78742affb86ed725bc42b1246acca_l3.png "Rendered by QuickLaTeX.com")




 optimized in equilibrium, such that for any two policy profiles
optimized in equilibrium, such that for any two policy profiles  the cross-play policy profile
the cross-play policy profile  is Pareto-dominated. Note that the definition implies that the welfare functions must be distinct.
is Pareto-dominated. Note that the definition implies that the welfare functions must be distinct. and
and  are in equilibrium that for
are in equilibrium that for  it is
it is
 exists that is deterministic. Denote
exists that is deterministic. Denote  (where
(where  denotes the joint observation history up to step
denotes the joint observation history up to step  is strictly worse than the values of their preferred welfare function maximizing profile. Then we can show that policies maximizing the welfare functions exist such that after some time step, their returns will be upper bounded by their minimax return.
is strictly worse than the values of their preferred welfare function maximizing profile. Then we can show that policies maximizing the welfare functions exist such that after some time step, their returns will be upper bounded by their minimax return. optimizing the respective welfare functions and a time step
optimizing the respective welfare functions and a time step ![\[V_i(t, \tilde{\pi}_1^w,\tilde{\pi}_2^{w'})\leq \min_{a_{-i}}\max_{a_i}\frac{1}{1-\gamma}r_i(a)\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-73f796a110baec611f9e9aabdd906b95_l3.png "Rendered by QuickLaTeX.com")

 as the policy profile in which player
as the policy profile in which player  unless the other player's actions differ from
unless the other player's actions differ from  at least once, after which they switch to the action
at least once, after which they switch to the action  Define
Define  analogously. Note that both profiles are still optimal for the corresponding welfare functions.
analogously. Note that both profiles are still optimal for the corresponding welfare functions. must be strictly worse than their preferred profile, for both players. So there is a time
must be strictly worse than their preferred profile, for both players. So there is a time  after which an action of a player
after which an action of a player  We have
We have  i.e., the value
i.e., the value  after which
after which  so
so![\[V_i(t,\tilde{\pi}) = \frac{1}{1-\gamma}r_i(a)\leq \max_{a'_i}\frac{1}{1-\gamma}r_i(a_{-i},a'_i)=\min_{a'_{-i}}\max_{a'_i}\frac{1}{1-\gamma}r(a').\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-f09fbeded8df669b6b03d93e61d9d61b_l3.png "Rendered by QuickLaTeX.com")


 . This might be a world-model estimated from a large amount of data. The randomness in the agents' models can be interpreted as agents having different ways of estimating a model from data, yielding different estimates (perhaps even if they have access to the same dataset). While an agent with more computational resources might account for the fact that their counterpart might have a different model in a
. This might be a world-model estimated from a large amount of data. The randomness in the agents' models can be interpreted as agents having different ways of estimating a model from data, yielding different estimates (perhaps even if they have access to the same dataset). While an agent with more computational resources might account for the fact that their counterpart might have a different model in a  . We assume the following about the agents' policies:
. We assume the following about the agents' policies: which play according to the (utilitarian)
which play according to the (utilitarian) , agent
, agent  , and if
, and if  , they play according to
, they play according to  . Thus they will play
. Thus they will play 
 of the time when each plays according to their default policy.
of the time when each plays according to their default policy. . To keep things simple, these reporting policies only distort the observed value of agent
. To keep things simple, these reporting policies only distort the observed value of agent  in a direction that favors them;
in a direction that favors them; . This is to disincentivize their counterpart from reporting models that are too different from their own, and therefore likely to be distorted. (I chose 8
. This is to disincentivize their counterpart from reporting models that are too different from their own, and therefore likely to be distorted. (I chose 8 
 and distortions
and distortions  . This The payoffs under the default policy profile and the Nash equilibrium (it happened to be unique) of the game in which principals choose the distortion levels
. This The payoffs under the default policy profile and the Nash equilibrium (it happened to be unique) of the game in which principals choose the distortion levels  for their agents are reported in Table 3.
for their agents are reported in Table 3.
 ,
,  for
for  . (Note that, in sequential environments — e.g., stochastic games — these "actions'' may in fact be policies mapping, e.g., the states of stochastic game to actions in that stochastic game.)
. (Note that, in sequential environments — e.g., stochastic games — these "actions'' may in fact be policies mapping, e.g., the states of stochastic game to actions in that stochastic game.) to each principal
to each principal  ;
; on which they can condition their policies, with
on which they can condition their policies, with  . These observations will correspond to data from which the agents estimate world-models (e.g., a model of a stochastic game) or form beliefs about other agents' private information.
. These observations will correspond to data from which the agents estimate world-models (e.g., a model of a stochastic game) or form beliefs about other agents' private information. based on private information
based on private information  .
. and ex ante payoffs
and ex ante payoffs![\[u_i(\pi_1, \pi_2) = \int u_i\left\{ \pi_1(X_1), \pi_2(X_2); G\right\} \mathrm{d} P_{\mathcal{X}}(X_1 \mid G) \mathrm{d}P_{\mathcal{X}}(X_2 \mid G) \mathrm{d}P_{\mathcal{G}}(G).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-aed281cfc4931661b3944a0adc11a87d_l3.png "Rendered by QuickLaTeX.com")
 under each utility function in
under each utility function in  can be learned with high accuracy.
can be learned with high accuracy. be sets of policies such that it is tractable to evaluate each profile
be sets of policies such that it is tractable to evaluate each profile  . In this context, assuming that the principals' utility functions are common knowledge, a pair of policies
. In this context, assuming that the principals' utility functions are common knowledge, a pair of policies ![\[ \begin{aligned} & \int u_i\{ \pi_i(X_i), \pi_j(X_j); G \} \mathrm{d} P_{\mathcal{X}}(X_i \mid G) \mathrm{d}P_{\mathcal{X}}(X_j \mid G) \mathrm{d}P_{\mathcal{G}}(G) \\ & \quad \geq \int u_i\{ \pi'_i(X_i), \pi_j(X_j); G \} \mathrm{d} \mathrm{d} P_{\mathcal{X}}(X_i \mid G) \mathrm{d}P_{\mathcal{X}}(X_j \mid G) \mathrm{d}P_{\mathcal{G}}(G), \text{ for all } \pi'_i \in \Pi_i. \end{aligned} \]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-151bb69dce9895406c878690ebc8c7dd_l3.png "Rendered by QuickLaTeX.com")
 consists of policies with limited capacity (reflecting computational boundedness), agents may learn policies which do not account for the variability in the estimation of their private models. I will call the class of such policies learned over during training time the "default policies''
consists of policies with limited capacity (reflecting computational boundedness), agents may learn policies which do not account for the variability in the estimation of their private models. I will call the class of such policies learned over during training time the "default policies''  . To address this problem in a computationally tractable way, we introduce policies
. To address this problem in a computationally tractable way, we introduce policies  which allow for the specification of a shared model of
which allow for the specification of a shared model of  be a set of models, and let
be a set of models, and let  be a set of solution concepts which map elements of
be a set of solution concepts which map elements of  bimatrices, and the solution concept they used was the Nash equilibrium which maximized the sum of their payoffs in the game
bimatrices, and the solution concept they used was the Nash equilibrium which maximized the sum of their payoffs in the game  .
. have the property that, for some
have the property that, for some  , the policy profile
, the policy profile  succeeds in collaboratively specifying a game with positive probability. That is, with positive probability we have
succeeds in collaboratively specifying a game with positive probability. That is, with positive probability we have for some
for some  and some
and some  .
. which is a Bayes-Nash equilibrium that improves upon any equilibrium in
which is a Bayes-Nash equilibrium that improves upon any equilibrium in  and which succeeds in collaboratively specifying a game with high probability.
and which succeeds in collaboratively specifying a game with high probability.  matches the distribution of environments encountered by the deployed policies. Moreover, I assume that both principals train their agents on this distribution of environments. In reality, of course, these assumptions will fail. A more modest but attainable goal is to use CGS to construct policies which perform well on whatever criteria individual principals use to evaluate policies for multi-agent environments, as discussed in the
matches the distribution of environments encountered by the deployed policies. Moreover, I assume that both principals train their agents on this distribution of environments. In reality, of course, these assumptions will fail. A more modest but attainable goal is to use CGS to construct policies which perform well on whatever criteria individual principals use to evaluate policies for multi-agent environments, as discussed in the 
![[0, 1]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-64c6b8db60d59c98141c270dc836fd0b_l3.png "Rendered by QuickLaTeX.com") and parameters
and parameters ![\[\begin{aligned} u_{\mathrm{R}}(\mathrm{Accept} \: s) & = s-F\mathbbm{1}(s < 0.4);\\ u_{\mathrm{R}}(\mathrm{Reject} \: s) & = I\mathbbm{1}(s < 0.4). \end{aligned}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-d3a4d8ed1606d6a7dd1cfab8c22879bd_l3.png "Rendered by QuickLaTeX.com")
 term can be interpreted as the Responder deeming offers of less than
term can be interpreted as the Responder deeming offers of less than  as unfair. Then, the
as unfair. Then, the  , or equivalently,
, or equivalently,  Notice that the decision depends only on
Notice that the decision depends only on  , and thus the data cannot distinguish between the effects of
, and thus the data cannot distinguish between the effects of  . Now, suppose that we have two candidate models — one on which fairness is the main component, and one on which iterated play is:
. Now, suppose that we have two candidate models — one on which fairness is the main component, and one on which iterated play is:![\[ \begin{aligned} M_F & = (0.15, 0.05) \\ M_I & = (0.05, 0.15). \end{aligned} \]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-4399448cd310ce4529d9f06656a3728f_l3.png "Rendered by QuickLaTeX.com")
 are the offered split and the Responder's decision in the
are the offered split and the Responder's decision in the  experiment, the likelihood of model
experiment, the likelihood of model ![\[ P(\{s_t, A_t\}_{t=1}^T \mid F, I) = \prod_{t=1}^T & \left[ s_t - (F + I)\mathbbm{1}(s < 0.4) > 0 \right]^{A_t} \left[ s_t - (F + I)\mathbbm{1}(s < 0.4) < 0 \right]^{1-A_t}. \]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-ed8278f4609fc31394f610768b9a32e2_l3.png "Rendered by QuickLaTeX.com")
 under both
under both  and
and  , this means that the prior and posterior over
, this means that the prior and posterior over  are equal.
are equal. . Thus, the Proposer's posterior expected payoff for split
. Thus, the Proposer's posterior expected payoff for split ![\[ \begin{aligned} \mathbb{E}\{ u_{\mathrm{P}}(s) \} & = (1 - s) P\{ s - F \mathbbm{1}(s < 0.4) \} \\ & = (1 - s) \times [ P(M_F)P\{ s - 0.15 \mathbbm{1} (s < 0.4) \} + P(M_I)P\{ s - 0.05 \mathbbm{1} (s < 0.4) \} ]. \end{aligned} \]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-7ea56958de73cd60957dccd51f5652d9_l3.png "Rendered by QuickLaTeX.com")

 . The three expected payoff curves are:
. The three expected payoff curves are: ;
; ;
;
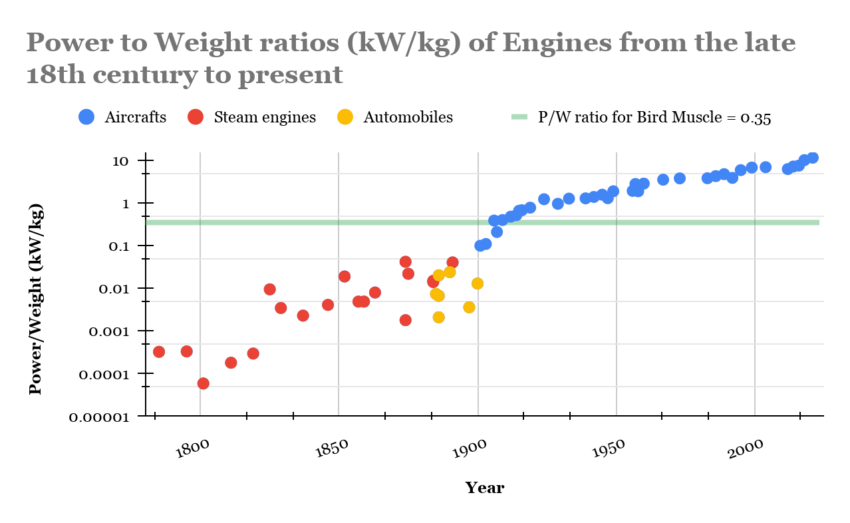
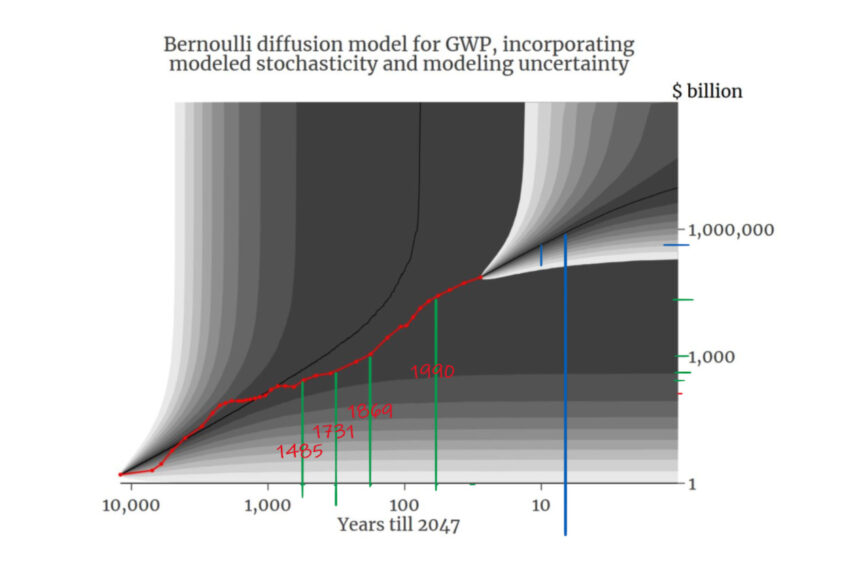

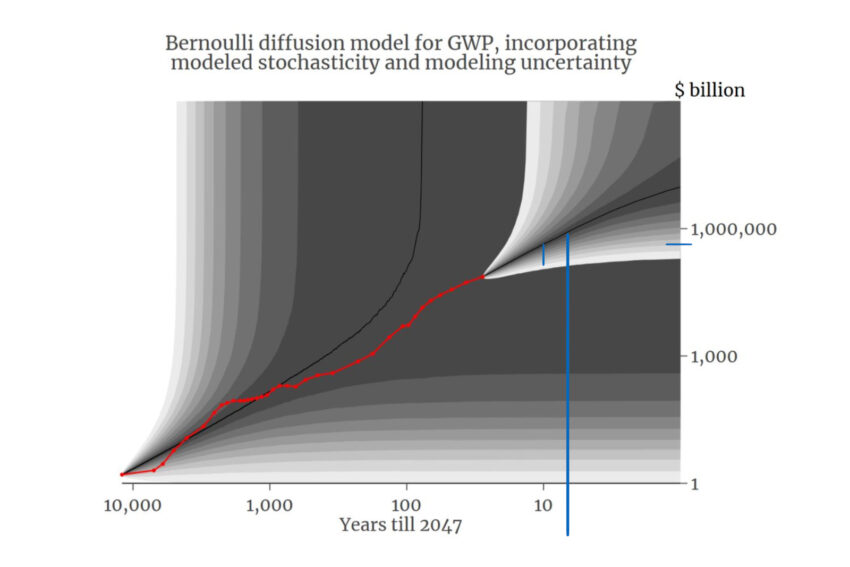
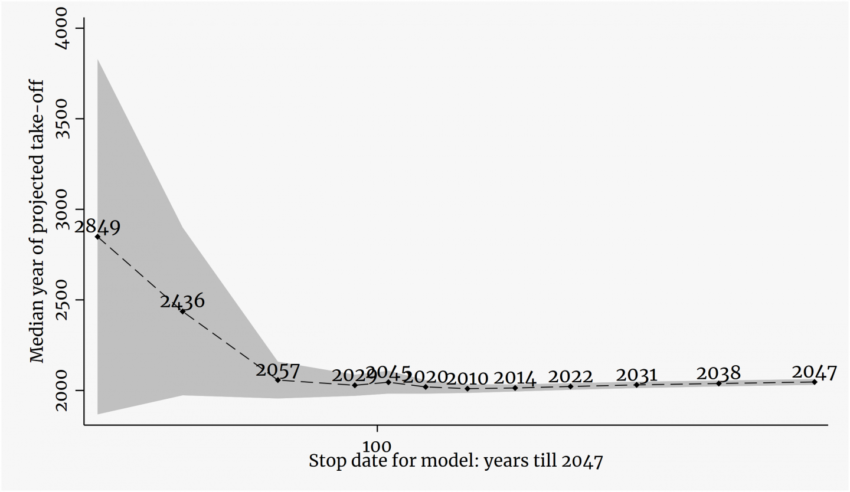
 (Mutual cooperation is better than mutual defection);
(Mutual cooperation is better than mutual defection); (Mutual cooperation is better than cooperating while your counterpart defects);
(Mutual cooperation is better than cooperating while your counterpart defects); (Mutual cooperation is better than randomizing between cooperation and defection);
(Mutual cooperation is better than randomizing between cooperation and defection); and
and  , the payoffs satisfy
, the payoffs satisfy  or
or  .
.
 while Player 2 plays
while Player 2 plays  for each country, so that their payoffs for Surrendering and Fighting are as in the top matrix in Table 2. However, suppose the countries agree on the probability
for each country, so that their payoffs for Surrendering and Fighting are as in the top matrix in Table 2. However, suppose the countries agree on the probability of simulations. Then, instead of engaging in a real conflict, they could allocate the territory based on a draw from the simulator. Playing this game is preferable, as it saves each country the cost
of simulations. Then, instead of engaging in a real conflict, they could allocate the territory based on a draw from the simulator. Playing this game is preferable, as it saves each country the cost 


 giving the probability of player 1 winning when the true types are
giving the probability of player 1 winning when the true types are  and agreed-upon win probability model
and agreed-upon win probability model  , for "cooperating with split
, for "cooperating with split 

 ; takes an action
; takes an action  based on their policy
based on their policy  . Player
. Player  if the policies
if the policies  be a "disagreement point'' measuring how well agent
be a "disagreement point'' measuring how well agent  , or an estimate of their value when the agents use independent learning algorithms. Finally, define player
, or an estimate of their value when the agents use independent learning algorithms. Finally, define player  . Table 5 displays welfare functions corresponding to several widely-discussed bargaining solutions, adapted to the multi-agent reinforcement learning setting.
. Table 5 displays welfare functions corresponding to several widely-discussed bargaining solutions, adapted to the multi-agent reinforcement learning setting.![\bgroup \def\arraystretch{1.5}% 1 is the default, change whatever you need\begin{tabular}{c|c} \centering \begin{tabular}{c|c} \textbf{Name of welfare function} $w$ & \textbf{Form of} $w(\pi_1, \pi_2)$ \\ \hline Nash (Nash, 1950) & $ \left[ V_1(\pi_1, \pi_2) - V_1^d \right] \cdot \left[ V_2(\pi_1, \pi_2) - V_2^d \right]$ \\ \hline Kalai-Smorodinsky (Kalai et al., 1975) & \makecell{$V_1(\pi_1, \pi_2)^2 + V_2(\pi_1, \pi_2)^2$ \\ & $ - \iota\left\{ \frac{V_1(\pi_1, \pi_2) - V_1^d}{V_2(\pi_1, \pi_2) - V_2^d} = \frac{V_1^* - V_1^d}{V_2^* - V_2^d} \right\} $} \\ \hline Egalitarian (Kalai, 1977) & $\min\left\{ V_1(\pi_1, \pi_2) - V_1^d, V_2(\pi_1, \pi_2) - V_2^d \right\}$ \\ \hline Utilitarian & $V_1(\pi_1, \pi_2) + V_2(\pi_1, \pi_2)$ \\ \hline \end{tabular} \egroup](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-6a07c4fc4a9d82899acb0e11853cb70b_l3.png "Rendered by QuickLaTeX.com")
 in the definition of the Kalai-Smorodinsky welfare is the
in the definition of the Kalai-Smorodinsky welfare is the  -
- . We need a way of detecting defections so that we can switch from the cooperative policy
. We need a way of detecting defections so that we can switch from the cooperative policy  to a punishment policy. Call a function that detects defections a "switching rule''. To make the framework general, consider switching rules
to a punishment policy. Call a function that detects defections a "switching rule''. To make the framework general, consider switching rules  which return 1 for
which return 1 for  and 0 for
and 0 for  . Rules
. Rules  .
. ;
; , for some
, for some  ;
; , for some
, for some  .
. to switch to in order to disincentivize defections. An extreme case of a punishment policy is the one in which an agent commits to minimizing their counterpart's utility once they have defected:
to switch to in order to disincentivize defections. An extreme case of a punishment policy is the one in which an agent commits to minimizing their counterpart's utility once they have defected:  . This is the generalization of the so-called "grim trigger'' strategy underlying the classical theory of iterated games (Friedman, 1971; Axelrod, 2000). It can be seen that each player submitting a grim trigger strategy in the above framework constitutes a Nash equilibrium in the case that the counterpart's observations and actions are visible (and therefore defections can be detected with certainty). However, grim trigger is intuitively an extremely dangerous strategy for promoting cooperation, and indeed does poorly in empirical studies of different strategies for the iterated Prisoner's Dilemma (Axelrod and Hamilton, 1981). One possibility is to train more forgiving, tit-for-tat-like punishment policies, and play a mixed strategy when choosing which to deploy in order to reduce exploitability.
. This is the generalization of the so-called "grim trigger'' strategy underlying the classical theory of iterated games (Friedman, 1971; Axelrod, 2000). It can be seen that each player submitting a grim trigger strategy in the above framework constitutes a Nash equilibrium in the case that the counterpart's observations and actions are visible (and therefore defections can be detected with certainty). However, grim trigger is intuitively an extremely dangerous strategy for promoting cooperation, and indeed does poorly in empirical studies of different strategies for the iterated Prisoner's Dilemma (Axelrod and Hamilton, 1981). One possibility is to train more forgiving, tit-for-tat-like punishment policies, and play a mixed strategy when choosing which to deploy in order to reduce exploitability.

 are possible outcomes;
are possible outcomes;  stands for a given notion of dependence of outcomes on actions. The dependence concept an agent uses for
stands for a given notion of dependence of outcomes on actions. The dependence concept an agent uses for ![\expect[ U \mid \mathrm{do}(a) ]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-0e479fe2c564e5be409633d3cc3ecc55_l3.png "Rendered by QuickLaTeX.com") . EDT, on the other hand, takes into account non-causal dependencies between the agent's actions and the outcome. In particular, it takes into account the evidence that taking the action provides for the actions taken by other agents in the environment with whom the decision-maker's actions are dependent. Thus the evidential expected utility is the classical conditional expectation
. EDT, on the other hand, takes into account non-causal dependencies between the agent's actions and the outcome. In particular, it takes into account the evidence that taking the action provides for the actions taken by other agents in the environment with whom the decision-maker's actions are dependent. Thus the evidential expected utility is the classical conditional expectation ![\expect[U \mid A = a]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-60ee6d11f6d63d720bdca5b5bb34261e_l3.png "Rendered by QuickLaTeX.com") .
. is high.)
is high.)























 This file is licensed under the Creative Commons Attribution 2.0 Generic license.")
 This file is licensed under the Creative Commons Attribution-Share Alike 2.0 Generic license.")
 killing a young Bushbuck (Tragelaphus sylvaticus) in the Kruger National Park.' Image by NJR ZA. (from https://en.wikipedia.org/wiki/File:Leopard_kill_-_KNP_-_001.jpg) This file is licensed under the Creative Commons Attribution-Share Alike 3.0 Unported license.")
.jpg) This file is licensed under the Creative Commons Attribution 3.0 Unported license.")
 This file is licensed under the Creative Commons Attribution 2.0 Generic license.")
 This file is licensed under the Creative Commons Attribution 2.0 Generic license.")
 This work has been released into the public domain by its author, Christina6593 at the wikipedia project. This applies worldwide.")
 bug nymphs.' Image by MedievalRich at en.wikipedia. (from https://en.wikipedia.org/wiki/File:Stink-bugs-hatching.jpg) This file is licensed under the Creative Commons Attribution-Share Alike 3.0 Unported license.")
 This file is licensed under the Creative Commons Attribution-Share Alike 2.0 Generic license.")
 This file is licensed under the Creative Commons Attribution-Share Alike 3.0 Unported license.")
 This file is licensed under the Creative Commons Attribution-Share Alike 3.0 Unported license. Subject to disclaimers.")
 This file is licensed under the Creative Commons Attribution 2.0 Generic license.")





 [GFDL (http://www.gnu.org/copyleft/fdl.html), CC-BY-SA-3.0 (http://creativecommons.org/licenses/by-sa/3.0/) or CC-BY-2.5 (http://creativecommons.org/licenses/by/2.5)], via Wikimedia Commons: https://commons.wikimedia.org/wiki/File:Honeywell_thermostat.jpg") Consider the following:
Consider the following: I think the extent of cooperation in the future is one of the most important factors to consider. A cautious, humane, and cooperative future has better prospects for building AGI in a way that avoids causing massive amounts of suffering to powerless creatures (e.g.,
I think the extent of cooperation in the future is one of the most important factors to consider. A cautious, humane, and cooperative future has better prospects for building AGI in a way that avoids causing massive amounts of suffering to powerless creatures (e.g., 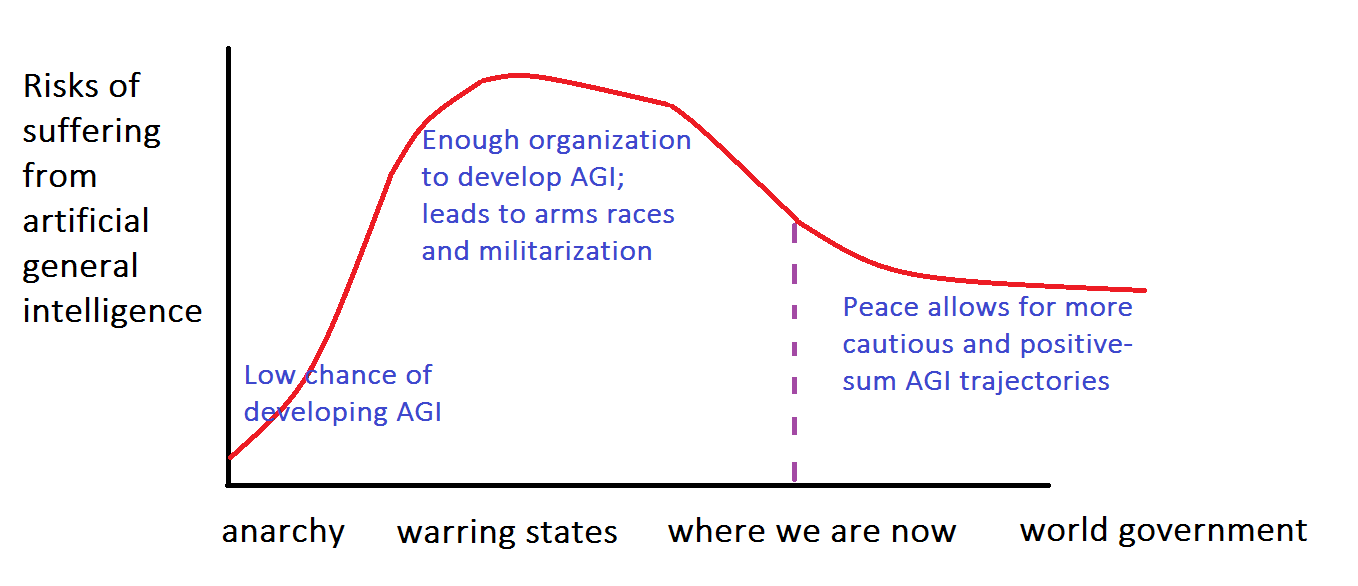

 Creative Commons Attribution-ShareAlike 3.0 or (2) GNU Free Documentation License (GFDL), Version 1.2 or any later version published by the Free Software Foundation with no invariant sections. See https://fa.wikipedia.org/wiki/%D9%BE%D8%B1%D9%88%D9%86%D8%AF%D9%87:Handshake_-_Pergamonmuseum.JPG") In the remainder of this piece I outline several
In the remainder of this piece I outline several ], via Wikimedia Commons: https://commons.wikimedia.org/wiki/File:Urval_av_de_bocker_som_har_vunnit_Nordiska_radets_litteraturpris_under_de_50_ar_som_priset_funnits_(3).jpg Licensed under Creative Commons Attribution 2.5 Denmark. Available for free use provided the source is credited.") Social networks and communities are extremely valuable in many ways, for emotional support, intellectual development, and sustaining altruistic motivation. That said, it's important also to take a bigger-picture view and think about what other thousands of intellectual communities you haven't explored yet. What other topics and world views should you learn about?
Social networks and communities are extremely valuable in many ways, for emotional support, intellectual development, and sustaining altruistic motivation. That said, it's important also to take a bigger-picture view and think about what other thousands of intellectual communities you haven't explored yet. What other topics and world views should you learn about? or GFDL (http://www.gnu.org/copyleft/fdl.html)], via Wikimedia Commons") Friend: "The
Friend: "The ")
 This work has been released into the public domain by its author, Bachrach44. This applies worldwide.")

 [CC-BY-SA-2.0 (http://creativecommons.org/licenses/by-sa/2.0)], via Wikimedia Commons: https://commons.wikimedia.org/wiki/File:United_Nations_Flags_-_cropped.jpg") world democratic government would make it likely that AI competition could be molded into cooperation.
world democratic government would make it likely that AI competition could be molded into cooperation. One coalition "wins" the contest and moves on to the global workspace, where the "news" is broadcast throughout the brain. This broadcasting is consciousness. The apparent serial nature of subjective experience despite parallel subcomponents results from the fact that only one news item is broadcast at a time.
One coalition "wins" the contest and moves on to the global workspace, where the "news" is broadcast throughout the brain. This broadcasting is consciousness. The apparent serial nature of subjective experience despite parallel subcomponents results from the fact that only one news item is broadcast at a time.], via Wikimedia Commons: https://commons.wikimedia.org/wiki/File:Philippine-stock-market-board.jpg")
 treaty, June 18, 1979, in Vienna.' Image by Bill Fitz-Patrick. (from https://commons.wikimedia.org/wiki/File:Carter_Brezhnev_sign_SALT_II.jpg) This work is in the public domain in the United States because it is a work prepared by an officer or employee of the United States Government as part of that person's official duties under the terms of Title 17, Chapter 1, Section 105 of the US Code.") global institutions, practices, and cultural outlooks would best encourage cooperative AI development, allowing for compromise and safety measures against suffering?
global institutions, practices, and cultural outlooks would best encourage cooperative AI development, allowing for compromise and safety measures against suffering?








 machine.' Author unknown. Source: Dr. Leon Kaufman. University Of California, San Francisco [Public domain], via Wikimedia Commons")





 This file is licensed under the Creative Commons Attribution-Share Alike 3.0 Unported, 2.5 Generic, 2.0 Generic and 1.0 Generic license.")

 and harem.' Image by M. Boylan. (from https://commons.wikimedia.org/wiki/File:Callorhinus_ursinus_and_harem.jpg) This work has been released into the public domain by its author, M. Boylan. This applies worldwide.")
. (from https://commons.wikimedia.org/wiki/File:Milky_Way_IR_Spitzer.jpg) This file is in the public domain because it was solely created by NASA. NASA copyright policy states that 'NASA material is not protected by copyright unless noted'.") Cross-supercluster communication seems tricky. Probably most of the exchanges among parties would happen at a local level, and intergalactic trades might be a rare and slow process.
Cross-supercluster communication seems tricky. Probably most of the exchanges among parties would happen at a local level, and intergalactic trades might be a rare and slow process.


 as well as by
as well as by {kind=link}
{kind=link}
{kind=link}