Coordination challenges for preventing AI conflict
Summary
In this article, I will sketch arguments for the following claims:
- Transformative AI scenarios involving multiple systems pose a unique existential risk: catastrophic bargaining failure between multiple AI systems (or joint AI-human systems).
- This risk is not sufficiently addressed by successfully aligning those systems, and we cannot safely delegate its solution to the AI systems themselves.
- Developers are better positioned than more far-sighted successor agents to coordinate in a way that solves this problem, but a solution also does not seem guaranteed.
- Developers intent on solving this problem can choose between developing separate but compatible systems that do not engage in costly conflict or building a single joint system.
- While the second option seems preferable from an altruistic perspective, there appear to be at least weak reasons that favor the first one from the perspective of the developers.
- Several avenues for (governance) interventions present themselves: increasing awareness of the problem among developers, facilitating the reaching of agreements (perhaps those for building a joint system in particular), and making development go well in the absence of problem awareness.
Contents
- Introduction
- Bargaining failure as a multipolar existential risk
- Even the most intelligent agents may fail to bargain successfully
- Why developer coordination might be necessary
- Comparing a joint system to multiple compatible ones
- Conclusion
- Acknowledgments
- Appendix: Examples of features developers might coordinate on
Introduction
In this article, I examine the challenge of ensuring coordination between AI developers to prevent catastrophic failure modes arising from the interactions of their systems. More specifically, I am interested in addressing bargaining failures as outlined in Jesse Clifton’s research agenda on Cooperation, Conflict & Transformative Artificial Intelligence (TAI) (2019) and Dafoe et al.’s Open Problems in Cooperative AI (2020).
First, I set out the general problem of bargaining failure and why bargaining problems might persist even for aligned superintelligent agents. Then, I argue for why developers might be in a good position to address the issue. I use a toy model to analyze whether we should expect them to do so by default. I deepen this analysis by comparing the merit and likelihood of different coordinated solutions. Finally, I suggest directions for interventions and future work.
The main goal of this article is to encourage and enable future work. To do so, I sketch the full path from problem to potential interventions. This large scope comes at the cost of depth of analysis. The models I use are primarily intended to illustrate how a particular question along this path can be tackled rather than to arrive at robust conclusions. At some point, I might revisit parts of this article to bolster the analysis in later sections.
Bargaining failure as a multipolar existential risk
Transformative AI scenarios involving multiple systems (“multipolar scenarios”) pose unique existential risks resulting from their interactions.1 Bargaining failure between AI systems, i.e., cases where each actor ends up much worse off than they could have under a negotiated agreement, is one such risk. The worst cases could result in human extinction or even worse outcomes (Clifton 2019).2
As a prosaic example, consider a standoff between AI systems similar to the Cold War between the U.S. and the Soviet Union. If they failed to handle such a scenario well, they might cause nuclear war in the best case and far worse if technology has further advanced at that point.
Short of existential risk, they could jeopardize a significant fraction of the cosmic endowment by preventing the realization of mutual gains or causing the loss of resources in costly conflicts.
This risk is not sufficiently addressed by AI alignment, by which I mean either “ensuring that systems are trying to do what their developers want them to do” or “ensuring that they are in fact doing what their developers want them to do.”3 Consider the Cuban Missile Crisis as an analogy: The governments of the U.S. and the Soviet Union were arguably “aligned” with some broad notion of human values, i.e., both governments would at least have considered total nuclear war to be a moral catastrophe. Nevertheless, they got to the brink of causing just that because of a failure to bargain successfully. Put differently, it’s conceivable, or even plausible, that the Cuban Missile Crisis could have resulted in global thermonuclear war, an outcome so bad that both parties would probably have preferred complete surrender.4
Even the most intelligent agents may fail to bargain successfully
This risk scenario is probably also not sufficiently addressed by ensuring that the AI systems we build have superhuman bargaining skills. Consider the Cuban Missile crisis again. I am arguing that a superintelligent Kennedy and superintelligent Khrushchev would not have been sufficient to guarantee successful prevention of the crisis. Even for superintelligent agents, some fundamental game-theoretic incompatibilities persist because the ability to solve them is largely orthogonal to any notion of “bargaining skill,” whether we conceive of that skill as part of intelligence or rationality. These are the “mixed-motive coordination problem” and the “prior selection problem.”5
“Mixed-motive coordination problem”6: As I use the term here, a mixed-motive coordination problem is a problem that arises when two agents need to pick one Pareto-optimal solution out of many different such solutions. The failure to pick the same one results in a failure to reach a mutually agreeable outcome. At the level of equilibria, this may arise in games that do not have a uniquely compelling cooperative equilibrium, i.e., they have multiple Pareto-optimal equilibria that correspond to competing notions of what counts as an acceptable agreement.78
For instance, in Bach or Stravinsky (see matrix below), both players would prefer going to any concert together (Stravinsky, Stravinsky or Bach, Bach) over going to any concert by themselves (Stravinsky, Bach or Bach, Stravinsky). However, one person prefers going to Stravinsky together, whereas the other prefers going to Bach together. Thus, there is a distributional problem when allocating the gains from coordination (Morrow 1994).9 Put in more technical terms: each player favors a different solution on the Pareto curve. Within this simple game, there is no way for the two players to reliably select the same concert, which will often cause them to end up alone.
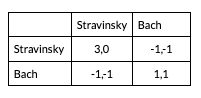
More fundamentally, agents may differ in the solution concepts or decision rules they use to decide what agreements are acceptable in a bargaining situation, e.g., they may use different bargaining solutions. In bargaining problems, different “reasonable” decision rules make different recommendations for which Pareto-optimal solution to pick. The worry is that independently developed systems could end up using, either implicitly or explicitly, different decision rules for bargaining problems, leading to bargaining failure. For instance, in the variant of Bach or Stravinsky above, (Stravinsky, Stravinsky) leads to the greatest total payoffs, while (Bach, Bach) is more equitable.10
As a toy example, consider the case where two actors are bargaining over some territory. There are many ways of dividing this territory. (Different ways of dividing the territory are analogous to (Stravinsky, Stravinsky) and (Bach, Bach) above.) One player (the proposer) makes a take-it-or-leave-it offer to the other player (the responder) of a division of the territory, and war occurs if the offer is rejected. (A rejected offer is analogous to the miscoordination outcome (Stravinsky, Bach.) If the proposer and responder have different notions of what counts as an acceptable offer, war may ensue. If the agents have highly destructive weapons at their disposal, then war may be extremely costly. (To see how this might apply in the context of transformative AI, imagine that these are AI systems bargaining over the resources of space.)
There are two objections to address here. First, why would the responder reject any offer if they know that war will ensue? One reason is that they have a commitment to reject offers that do not meet their standards of fairness to reduce their exploitability by other agents. For AI systems, there are a few ways this could happen. For example, such commitments may have evolved as an adaptive behavior in an evolution-like training environment or be the result of imitating human exemplars with the same implicit commitments. AI systems or their overseers might have also implemented these commitments as part of a commitment race.
Second, isn’t this game greatly oversimplified? For instance, agents could engage in limited war and return to the bargaining table later, rather than catastrophic war. There are a few responses here. For one thing, highly destructive weapons or irrevocable commitments might preclude the success of bargaining later on. Another consideration is that some complications — such as agents having uncertainty about each others’ private information (see below) — would seem to make bargaining failure more likely, not less so.
“Prior selection problem”: In games of incomplete information, i.e., games in which players have some private information about their payoffs or available actions, the standard solution–Bayesian Nash equilibrium–requires the agents to have common knowledge of each others’ priors over possible values of the players’ private information. However, if systems end up with different priors, outcomes may be bad.11 For instance, one player might believe their threat to be credible, whereas the other player might think it’s a bluff, leading to the escalation of the conflict. Similar to mixed-motive coordination problems, there are many “reasonable” priors and no unique individually rational rule that picks out one of them. In the case of machine learning, priors could well be determined by the random initialization of the weights or incidental features of the training environment (e.g., the distribution of other agents against which an agent is trained). Such differences in beliefs may persist over time due to models of other agents being underdetermined in strategic settings.12
Note that these concepts are idealizations. More broadly, AI systems may have different beliefs and procedures for deciding which commitments are credible and which bargains are acceptable.
Why developer coordination might be necessary
Independent development as a cause
These incompatibility problems are much more likely to arise or lead to catastrophic failures if AI systems are developed independently. During training, failure to arrive at mutually agreeable solutions is likely to result in lower rewards. So a system will usually perform well against counterparts that are similar to the ones it encountered during training. If the development of two systems is independent, such similarity is not guaranteed, and bargaining is more likely to fail catastrophically due to the reasons I sketched above.
Again, let’s consider a human analogy. There is evidence for significant behavioral differences among individuals from different cultures when playing standard economic games (e.g., the ultimatum game, the dictator game, different public goods games). For instance, Henrich et al. (2005) found that mean offers from Western university students usually ranged from 42-48% in the ultimatum game. Among members of the fifteen small-scale societies they studied, mean offers instead spanned 25-57%. In a meta-analysis, Oosterbeek, Sloof & van de Kuilen (2004) found systematic cultural differences in the behavior of responders (but not proposers). Relatedly, there also appears to be evidence for cross-cultural differences with regard to notions of fairness (e.g., Blake et al. 2015, Schaefer et al. 2015). This body of literature is at least suggestive of humans learning different “priors” or “decision rules” depending on their “training regime,” i.e., their upbringing.
The smaller literature on intercultural play, where members from different cultures play against one another, weakly supports welfare losses as a result of such differences: “while a few studies have shown no differences between intra- and intercultural interactions, most studies have shown that intercultural interactions produce less cooperation and more competition than intracultural interactions” (Matsumoto, Hwang 2011). I only consider this weak evidence as the relevant studies do not seem to carefully control for the potential of (shared) distrust of perceived strangers, which would also explain these results but is independent of incompatible game-playing behavior.
Incompatibility problems all the way down
It is tempting to delegate the solving of these problems to future more capable AI systems. However, it is not guaranteed that they will be in a position to solve them, despite being otherwise highly capable.
For one, development may have already locked in priors or strong preferences over bargaining solutions, either unintentionally or deliberately (as the result of a commitment race, for instance). This could put strict limits on their abilities to solve these problems.
More fundamentally, solving these incompatibility problems requires overcoming another such problem. Picking out some equilibrium, solution concept, or prior will favor one system over another. So they face another distributional problem. Solving that requires successful bargaining, the failure of which was the original problem. If they wanted to solve this second incompatibility problem, they would face another one. In other words, there are incompatibility problems all the way down.
One possibility is that many agents will by default be sufficiently “reasonable” that they can agree on a solution concept via reasoned deliberation, avoiding commitments to incompatible solution concepts for bargaining problems. Maybe many sufficiently advanced systems will engage in reasoning such as “let’s figure out the correct axioms for a bargaining solution, or at least sufficiently reasonable ones that we can both feel OK about the agreement.”13 Unfortunately, it does not seem guaranteed that this kind of reasoning will be selected for during the development of the relevant AI systems.
Why developers are better suited
Developers then might be better suited to addressing this issue than more capable successor agents, whether they be AI systems or AI-assisted humans:
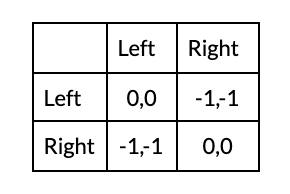
The comparative ignorance of present-day humans mitigates the distributional problem faced by more far-sighted and intelligent successor agents.14 The distributional consequences of particular coordination arrangements will likely be very unclear to AI developers. Compared to future agents, I expect them to have more uncertainty about their values, preferred solution concepts, the consequences of different coordination agreements, and how these three variables relate to one another. This will smooth out differences in expected value between different coordination outcomes. However, developers will have much less uncertainty about the value of averting conflict by coordinating in some form. So it will be easier for them to find a mutually agreeable arrangement as the situation for them looks more like a pure coordination game (see matrix below), which are much easier to solve by cheap talk alone, than Bach or Stravinsky (see matrix above).15
The loss aversion and scope insensitivity of (most) human bargainers will likely compound this effect. I expect it will increase the inclination to avoid catastrophes compared to securing relative gains. This, again, will push this game more toward one of pure coordination, mitigating the distributional problem. In comparison, AI systems are less likely to exhibit such “biases.”16
A related point is that human bargainers might not even know what the Pareto frontier looks like. Thus, instead of trying to bargain for their most favorable point on the Pareto frontier, they have incentives to converge on any mutually agreeable settlement even if it is Pareto inferior to many other possible outcomes. This, in turn, probably decreases the chance of catastrophic failures.17 As Young (1989) writes:
Negotiators who know the locus of a contract curve or the shape of a welfare frontier to begin with will naturally be motivated primarily by a desire to achieve an outcome on this curve or frontier that is as favorable to their own interests as possible. They will, therefore, immediately turn to calculations regarding various types of strategic behavior or committal tactics that may help them achieve their distributive goals.
Negotiators who do not start with a common understanding regarding the contours of the contract curve or the locus of the negotiation set, by contrast, have compelling incentives to engage in exploratory interactions to identify opportunities for devising mutually beneficial deals. Such negotiators may never discover the actual shape of the contract curve or locus of the negotiation set, and they may consequently end up with arrangements that are Pareto-inferior in the sense that they leave feasible joint gains on the table. At the same time, however, they are less likely to engage in negotiations that bog down into protracted stalemates brought about by efforts to improve the outcome for one party or another through initiatives involving strategic behavior and committal tactics.
What developer coordination looks like
Developers intent on solving this problem can choose between two broad classes of options18:
- They could coordinate on choosing compatible features such that interactions between their systems do not lead to catastrophic outcomes. Within the current machine learning paradigm, it will likely not be possible to coordinate directly on the priors and decision rules of the respective systems, as these may only be represented implicitly in the learned policies of agents. More realistically, developers would coordinate on training features like the reward structure and the learning environment or restrictions on the space of policies that agents learn over. (See “Appendix: Examples of features developers might coordinate on” for concrete examples.) To the extent that systems are modular, coordination could also occur at the level of bargaining-relevant modules.
- They could agree to build a single joint system to prevent any conflict between their systems in the first place. So instead of two developers building two separate systems, they join forces to build a single one.19 This may take various institutional forms, ranging from a joint engineering project to a full merger. In all those cases, no direct bargaining between AI systems would occur as long as all developers participate.
Both solutions require overcoming the distributional problem discussed in the previous section. In the case of coordinating on compatible features, each set of features will have different distributional consequences for the developers. In the case of agreeing to build a joint system, there will be different viable agreements, again with different distributional consequences for the developers (e.g., the system may pursue various tradeoffs between the developers’ individual goals, or developers might get different distributions of equity shares).20
Coordination is not guaranteed in a game-theoretic toy model
For now, let’s assume that there are only two developers who are both aware of these coordination problems and have the technical ability to solve them. Let’s further assume the two options introduced above do not differ significantly in their effectiveness at preventing conflict, and the costs of coordination are negligible. Then the game they are playing can be modeled as a coordination game like Bach or Stravinsky.2122
In non-iterated and sequential play, we can expect coordination, at least under idealized conditions. The follower will adapt to the strategy chosen by the leader since they have nothing to gain by not coordinating (“pre-emption”). If I know that my friend is at the Bach concert, I will also go to the Bach concert since I prefer that to being at the Stravinsky concert on my own.
In non-iterated and simultaneous play, the outcome is underdetermined. They may end up coordinating, or they may not. It depends on whether they will be able to solve the bargaining problem inherent to the game. Introducing credible commitments could move us from simultaneous play to sequential play, ensuring coordination once again.23 If I can credibly commit to going to one concert rather than another, my counterpart has again nothing to gain by choosing the other concert. They will join me at the one that I signaled I would go to.
In iterated play, the outcome is, again, uncertain. Unlike the Prisoner’s Dilemma, there is no need to monitor and enforce any agreement in coordination games once it has been reached. Free-riding is not possible: deviation from equilibrium harms both players, i.e., agreements are generally self-enforcing (Snidal 1985). However, the iteration of the game incentivizes players to insist on the coordination outcome that is more favorable to them. Foregoing coordination one round might be worth it if you think you can cause your counterpart to move to the more favorable equilibrium in subsequent rounds.
Which of these versions of the game best describes AI takeoff primarily depends on two variables: Close races will be more akin to simultaneous play where developers do not first observe what their counterpart “played” until they have already locked in a certain choice themselves. Iteration is akin to successive deployment where developers release improved versions over time. So only if one developer is clearly ahead of the competition is it that coordination seems anything close to guaranteed in this toy model, and those might be the scenarios where one actor gains a decisive strategic advantage in any case. Otherwise, bargaining will occur, and may fail.
Note: I don’t intend for this section to be a comprehensive analysis of this situation. Rather, it is intended as a first stab at the problem and a demonstration of how to make progress on the question of whether we can expect coordination by default. This basic model could be extended in various ways to capture different complexities of the situation.
Coordination could occur without awareness
If we drop the assumption that developers are aware of the need to coordinate, coordination may still occur regardless. However, it is necessarily less likely. Three paths then seem to remain:
First, norms might emerge organically as the result of trial and error. This would require iteration and a well-functioning feedback mechanism. For instance, the two labs release pre-TAI systems, which interact poorly, perhaps due to the problems described in this article. They lack concrete models for the reasons for this failure, but in subsequent releases, both labs independently tinker with the algorithms until they interact well with one another. This compatibility then also transfers to their transformative systems. My intuition is that the likelihood of such an outcome will depend a lot on how fast and how continuously AI development progresses.
Second, the relevant features may end up being compatible due to the homogeneity of the systems. However, even the same training procedures can result in different and incompatible decision rules due to random differences in initialization.24 More narrowly, a third party might develop a bargaining “module” or service, which is integrated into all transformative systems by their developers due to its competitive performance rather than as the result of a coordination effort. Again, this outcome is not guaranteed.
Third, developers might agree to build a joint system for reasons other than the problem discussed in this article:
- Most likely, they might want to speed up development by pooling rival goods or increasing available capital (e.g., Quebec Agreement25, International Space Station26, Concorde27, CERN28).29 In the case of TAI, the researchers and engineers with the specialized (tacit) knowledge required to build such a system might be distributed over two labs. In that case, a negotiated collaboration could be preferable to mutual poaching of top talent, the latter of which is not even possible in the case of national projects.
- Less likely, developers might want to decrease risk by spreading upside and downside across multiple stakeholders. This follows the same idea behind portfolio diversification. In the case of AI, the development of a huge, unprecedented model might require large upfront investments that no firm might be willing to undertake on their own because failure could result in ruinous losses.30
- Also less likely, national labs might want to prevent freeriding when they expect the building of a system to create massive public goods.31 In the case of AI, they might think it will be difficult to prevent the diffusion of novel algorithms across borders. If so, it would be difficult to internalize the benefits of a large public investment in foundational AI R&D, allowing others to freeride.32 Sharing the costs mitigates those concerns.33 This would be most relevant in scenarios where transformative systems require breakthrough algorithmic insights instead of tacit engineering knowledge and a lot of computing power.
None of these would guarantee that only one system is developed. They merely give reasons to some developers to merge with some other developers.
Comparing a joint system to multiple compatible ones
Given the toy model we used above, both solutions (compatible features and the building of a single system) do not differ in terms of payoffs. However, to examine how desirable they are from an altruistic perspective and how likely they are to come about, we need to analyze them in more detail. Again, the analysis will remain at the surface level and is intended as a first stab and illustration.
Building a joint system seems preferable to multiple compatible ones
Restricting our perspective to the problem discussed in this article, developers building a joint system is preferable since it completely obviates any bargaining by the AI systems themselves.34 Moreover, the underlying agreement seems significantly harder to renege on. It also effectively addresses the racing problem and some other multipolar challenges introduced in Critch, Krueger 2020.
At the same time, it would increase the importance of solving multi (stakeholder)/single (AI system) challenges (cf. section 8 of Critch, Krueger 2020), e.g., those related to social choice and accommodating disagreements between developers. If that turns out to be less tractable or to have worse side effects, this could sway the overall balance. The above analysis also ignores potential negative side-effects such agreements might have on the design of AI systems and the dynamics of AI development more broadly, e.g., by speeding up development in general. Analyzing these effects is beyond the scope of this article. Overall, however, I tend to believe that such an agreement would be desirable, especially in a close race.
It seems unclear whether developers will build a joint system or settle for multiple compatible ones
It seems to me that two factors are most likely to determine the choice of developers35: (1) the consequences of each mode of coordination for the anticipated payoffs attained by the AI systems after deployment and (2) the transaction costs incurred by bringing about either of the two options prior to deployment.36
It’s plausible that the post-deployment payoffs will be overwhelmingly important, especially if developers appreciate the astronomical stakes involved. Nevertheless, transaction costs may still be important to the extent that developers are not as far-sighted and suffer from scope neglect.
Understanding the differences in payoffs would require a more comprehensive version of the analysis attempted in the previous section and the motivations of the developers in question. For instance, if the argument of the previous section holds, altruistically inclined developers would see higher payoffs associated with building a single system compared to an agreement to build compatible systems.37 On the other hand, competing national projects may be far more reluctant to join forces.
More general insights can be gleaned when it comes to transaction costs. The most common analytical lens for predicting what kinds of transactions agents will make is new institutional economics (NIE).38 Where game-theoretic models often abstract away such costs through idealization assumptions, NIE acknowledges that agents have cognitive limitations, lack information, and struggle to monitor and enforce agreements. This results in different transaction costs for different contractual arrangements, which influences which one is picked. This perspective can shed light on the question of whether to collaborate using the market to contract (e.g., buying, selling) or whether to collaborate using hierarchy & governance (e.g., regular employment, mergers). In our case, these transaction types are represented by agreeing to use compatible features and by agreeing to build a joint system, respectively.
Transaction costs are often grouped into three categories39:
- search costs (e.g., finding the cheapest supplier)
- bargaining costs (e.g., negotiating the details of the contract)
- governance & enforcement costs (e.g., setting up mechanisms for communication, monitoring behavior, and punishing defections)40
On the face of it, this lens suggests that all else equal, actors would prefer to find compatible features over agreeing to build a single system because the costs for the former seem lower than the ones for the latter41:
- I expect that search costs will make up a negligible fraction of the total transaction costs as the number of relevant developers will be small and probably well-known to one another. I also don’t expect them to differ significantly in the two cases we are examining. In both cases, the partners in the transactions are the same, the information required to transact will be similar, and there will be little switching of transaction partners.
- It’s difficult to estimate differences in bargaining costs; specifying exact & appropriate technical standards is likely going to be complicated, but reaching an agreement for the institutional structure required to build a joint system may also be complicated. I expect this to depend a lot on the specifics of the respective scenarios.
- Any agreement stipulating compatible features would have minimal enforcement costs since it would be largely self-enforcing (see above).42 Agreements to build a single system, on the other hand, would impose substantial governance costs. It would be challenging to set up or adapt the administrative structures required to ensure two previously separate teams work together smoothly.43
This is weakly suggestive to me that transaction costs will incline developers to building compatible systems over building a joint system. Looking for case studies, this impression seems confirmed. I am not aware of any real-world examples of agreements to merge, build a single system instead of multiple, or establish a supranational structure to solve a coordination problem. Instead, actors seem to prefer to solve such problems through agreements and conventions. For instance, all standardization efforts fall into this category. Those reasons become stronger with an increasing number of potentially relevant developers as the costs for coordinating the development of a joint system rise more rapidly with an increasing number of actors compared to an agreement among independent developers, which probably will have very low marginal costs.
Overall, I expect that there will be strong reasons to build a joint system if there is a small number of relevant nonstate developers who are aware of and moved by the astronomical stakes. In those cases, I would be surprised if transaction costs swayed them. I am more pessimistic in other scenarios.
Conclusion
Coordination is not assured. Even if coordination is achieved, the outcome could still be suboptimal. This suggests that additional work on this problem would be valuable. In the next two sections, I will sketch directions for potential interventions and future research to make progress on this issue.
Interventions
I will restrict this section to interventions for the governance problem sketched in this article while ignoring most technical challenges.44 I don’t necessarily endorse all of them without reservations as good ideas to implement. Some of them might have positive effects beyond the narrow application discussed here. Some might have (unforeseen) negative effects.
Increasing problem awareness
Without awareness of the problem, a solution to the core problem becomes significantly less likely. Accordingly, increasing awareness of this problem among competitive developers is an important step.45 It seems particularly important to do so in a way that is accessible to people with a machine learning background. One potential avenue might be to develop benchmarks that highlight the limits on achieving cooperation among AI agents without coordination by their developers. Our work on mixed-motive coordination problems in Stastny et al. 2021 is an example of ongoing work in this area.
Facilitating agreements
Some interventions can make the reaching of an agreement more likely under real-world conditions. Some reduce the transaction costs developers need to pay. Other mitigate the distributional problem they may face. I expect that many of these would also contribute to solving other bargaining problems between AI developers (e.g., finding solutions to the racing problem).
- Setting up or improving bargaining fora (e.g., the Partnership on AI or standards bodies like the IEEE or the ISO) could help structure the bargaining process (Fearon 1998). Following Keohane (1984), such institutions can also ‘cluster’ issues together, facilitating side payments and issue linkage (e.g., McGinnis 1986), which can help with constructing mutually beneficial bargains.
- Young (1989) suggests that salient solutions can help select one out of the many possible agreements.46 Additional research could identify such focal points to be advocated by the AI safety community.
- Krasner (1982) suggests that increasing the knowledge of the relevant actors about how the most dangerous scenarios could materialize and how to prevent them could aid in actually implementing such a solution. This has often been the role of epistemic communities in facilitating international regimes & agreements (e.g., Haas 1992).
- Facilitating agreements between the relevant actors on other issues could help build trust, formal procedures, and customs, which also seems to improve the chance of successful bargaining (Snidal 1985, Krasner 1982). The literature on confidence-building measures might also be relevant (e.g., Landau and Landau 1997).
Making development go well in the absence of problem awareness
If developers are not sufficiently aware of the problem, there might still be interventions making coordination more likely.
- “Interlab” training environments or tournaments, in which AI systems interact with one another (either during training or before deployment), could provide the feedback required to build AI systems with compatible bargaining features.
- Requirements to test novel systems against existing ones in a boxed environment might lead to all subsequent developers adjusting to the first one. Instead of an iterative emergence, compatible features would come about as a result of pre-emption. As a downside, this might exacerbate racing by developers to deploy first to select the most advantageous equilibrium.
Facilitating agreements to build a joint system
As I wrote above, a superficial analysis suggests that such agreements would be beneficial. If so, there might be interventions to make them more likely without causing excessive negative side-effects. For instance, one could restrict such efforts to tight races, as the OpenAI Assist Clause attempts to do.
Future work
There are many ways in which the analysis of this post could be extended or made more rigorous:
- building more sophisticated game-theoretic models to analyze the coordination problem between developers (e.g., allowing for partial coordination);
- including transaction costs in an analysis of whether developers would coordinate in the first place or whether doing so would be too costly;
- more comprehensively comparing the transaction costs of realizing different arrangements.
There are also more foundational questions about takeoff scenarios relevant to this problem:
- Are agreements to build a single system actually overall a good idea?
- How similar to one another (in relevant respects) should we expect the AI systems in multipolar scenarios to be?
We can ask further questions about potential interventions:
- What are ideal institutional arrangements, either for building a single system or for multiple compatible systems?
- What limits does antitrust regulation place on the kind of coordination proposed in this article?
- What insights can be gained from the literature about epistemic communities?
Acknowledgments
I want to thank Jesse Clifton for substantial contributions to this article as well as Daniel Kokotajlo, Emery Cooper, Kwan Yee Ng, Markus Anderljung, and Max Daniel for comments on a draft version of this article.
Appendix: Examples of features developers might coordinate on
Throughout this document, I have talked about bargaining-relevant features of AI systems that developers might coordinate on. The details of these features depend on facts about how transformative AI systems are trained which are currently highly uncertain. For the sake of concreteness, however, here are some examples of features that AI developers might coordinate on, depending on what approach to AI development is ultimately taken:
- A social welfare function for their systems to jointly optimize, and policies for deciding how to identify and punish defections from this agreement (see Stastny et al. 2021, Clifton, Riché 2020);
- The details of procedures for resolving high-stakes negotiations; for instance, collaborative game specification47 is such a method, and requires (among other things) agreement (perhaps among other things) on 1) a method for combining agents’ reported models of their strategic situation and 2) a solution concept to apply to a collaboratively specified game;
- The content of parts of a user's manual for human-in-the-loop AI training regimes that are relevant to bargaining-related behavior. For instance, developers might adopt common instructions for how to give approval to agents being trained in various bargaining environments;
- The content of guidelines for how to behave in high-stakes bargaining situations, in regimes where natural language instructions are used to impose constraints on AI systems’ behavior.
- I do not mean to imply that this is the only risk posed by multipolar scenarios. For other ones, see for example: Critch, Krueger 2020, Zwetsloot, Dafoe 2019, Manheim 2018.
- Note that bargaining failure is not the only cause of catastrophic interactions. For instance, the interactions of Lethal Autonomous Weapon Systems might also be catastrophic.
- Alignment only suffices if the goals of the two systems are identical, and they have common knowledge of this fact, which seems unlikely in a multipolar scenario. Working toward “social alignment”, i.e., alignment with society as a whole (as described, e.g., here), or a “homogeneous takeoff” might make that more likely.
- One strand of the international relations literature argues that the failure of rational agents to bargain successfully is one explanation for wars between human nation states. See Fearon (1995) for the seminal text of this perspective.
- These problems have been explored in the context of AI in more detail here and in Stastny et al. 2021.
- We are still deliberating about the appropriate terminology for this problem.
- There are equilibrium selection problems which do not have this more specific property. Take, for instance, the Iterated Prisoner's Dilemma: It has many equilibria, but the only cooperative one is both players playing (Cooperate, Cooperate) at every time step on the equilibrium path.
- This is formalized in Stastny et al. 2021.
- This distributional problem is compounded by informational problems because the bargaining parties have an incentive to distort their private information (e.g., about their preferences) to get a better deal (Morrow 1994).
- Now, one might object that a rational actor would realize this problem and play as conservatively as possible. One could, for instance, always accept any Pareto-optimal agreement. This behavior, however, is very exploitable and comes at a significant competitiveness cost, which makes this strategy unattractive.
- Outcomes are not necessarily catastrophic, but on the face of it, misperception seems much more likely to cause than prevent conflict.
- Jesse Clifton makes this point here.
- See this comment thread.
- For what it’s worth, myopia has been suggested as a safety technique and appropriately myopic systems might also address this problem. At the same time, however, they need to be sufficiently far-sighted to realize that future conflict could pose a catastrophic risk.
- Even to the extent that distributional issues remain, humans might be better suited to solve them as they have a shared evolutionary history and an increasingly shared cultural background, which is more uncertain in the case of AI systems, where it depends mostly on the homogeneity of AI takeoff.
- This argument carries less force for AI systems that might still exhibit such biases. Myopic agents might, again, be such an example. Overall, however, I do think it’s more plausible than not that AI systems will be more scope-sensitive than humans. They are more likely to pursue an idealized version of human goals or they may modify their goals to be more scope-sensitive to improve their bargaining position.
- It could, however, lead to the failed exploitation of some significant fraction of the cosmic endowment. By some totalist value systems, this may be a tragedy not worth risking.
- One unilateral solution is for developers to make their systems maximally conservative, i.e., to follow a policy of accepting any agreement that is proposed to them. Such exploitable systems, however, would probably not be acceptable to developers, and as soon as systems are not maximally conservative, there is room for bargaining failure. (Also see footnote 10.)
- Critch, Krueger (2020) discuss this under the heading of multi/single delegation.
- There are some structural differences between the two solutions. For instance, agreements to use mutually compatible features might allow partial coordination because the option space might not be discrete (Snidal 1985). This is not the case when agreeing to build a single system. However, these differences are unimportant for the subsequent analysis.
- Analyses of this simple game can be found in Stein 1982, who calls this a “dilemma of common aversion”, and in Snidal 1985.
- If the game is indeed more appropriately modeled as a game of pure coordination due to the uncertainty of the developers as suggested by the previous section, coordination is assured conditional on developers being aware of the problem, communication being possible, and coordination being sufficiently cheap. So I will not discuss this option further.
- Such credible commitments could, for instance, be achieved through transparency tools.
- See Stastny et al. 2021 for an example of such failure.
- The UK did not have capacity for its own atomic weapon program. Joining forces with the US was their only viable path to an atomic weapon in the short-term. The US seems to have believed that the British could provide important help for some parts of the Manhattan project.
- NASA could not secure sufficient capital for the ISS domestically. So they pushed for involving European allies in the project. Russia was approached for their operational and technical experience with space stations, which was unique at the time (Lambright, Schaefer 2004).
- It seems like the sharing of the high cost was the main reason for collaboration (Johnman, Lynch 2002a, Johnman, Lynch 2002b).
- Facilities for high-energy particle physics were simply too expensive for any one European country at the time. As all of them were interested in preventing brain drain, pooling resources was in their mutual interest. It also seems like CERN served as a confidence-building measure in post-war Europe (Schukraft 2004). However, I would be surprised if this factor will play a large role in the potential joining of national AI labs due to the strategic nature of the technology.
- Note that often this is done to beat another competitor since unilateral development would usually become feasible in due time.
- This is less relevant for national projects because governments face no realistic risk of ruin.
- ITER might have been an example of this, but so far I have not been able to find any reliable sources on the reasons for collaboration on this project.
- Sandler, Cauley (2007) discuss this rationale.
- On the other hand, such mergers lead to technology diffusion which is costly or even impossible to prevent.
- Though there might still be acausal bargaining.
- In the case of commercial developers, legal constraints may also play a decisive role. Mergers & acquisitions as well as self-regulation/coordination are subject to antitrust regulation and rulings (see here, for instance).
- These two factors could be integrated into a single payoff value. The conceptual distinction is still analytically helpful.
- For instance, there is good reason to believe that OpenAI added the “Assist Clause” to their charter not to ensure their own success as an organization but to prevent a development race, which could be disastrous from an impartial perspective.
- In principle, it also allows us to make more precise predictions about whether to expect a coordinated outcome in the first place because it allows for less idealized conditions. Concretely, developers will find coordination worth it if the (estimated) transaction costs required to bring about any given coordination outcome are lower than the (estimated) benefits of the coordination outcome over their best alternative to a negotiated agreement (BATNA). Actually analyzing this for the case at hand is beyond the scope of this article.
- This list is not intended to be exhaustive. It only covers commonly discussed types of transaction costs.
- Especially in the international relations literature, supranational structures are usually only discussed as solutions for monitoring and enforcement in the face of opportunism, which does not arise for coordination problems (e.g., Sandler, Cauley 1977). Such analysis is applied, for instance, to the question of empire/alliance formation (Lake 1996) or the formation of the single European market (e.g., Garrett 1992, Garrett 1995).
- In what follows, I assume that actors can make sufficiently accurate estimates of the transaction costs involved. Lipson (2004) discusses this assumption in the context of international relations.
- This theoretic self-enforcement result abstracts away a number of real-world difficulties. For instance, actors might initially agree but renege due to hyperbolic discounting when faced with implementation costs. It further assumes that actors are unitary and have timeless preferences. Neither assumption is strictly correct. For instance, a change in leadership might change the value assigned to a previous agreement.
- Their nature and extent will depend on the institutional setup agreed upon to build the single system. For instance, a contractual agreement to build a single system would probably require monitoring & enforcement mechanisms but no administrative apparatus. A merger between two labs would probably have inverse requirements. Here, I am subsuming both under “governance costs.”
- See the appendix for a few research directions on making systems compatible. Critch, Krueger (2020) discuss technical challenges for building joint systems under the category multi (stakeholders)/single (AI system).
- I expect there are insights to be gleaned from the research on epistemic communities for how to best do so.
- For example, in the idealized case where agents have explicit utility functions and developers coordinate on what tradeoff between their utility functions should be pursued, candidate focal points might be bargaining solutions with compelling normative properties.
- Consider as an analogy the Moscow–Washington hotline, which provided a direct communication link between the leaders of the U.S. and the Soviet Union. It was instituted after the Cuban Missile Crisis had made the need for better communication channels apparent.