Commitment games with conditional information revelation
![\[\begin{array}{ccc} \textbf{Anthony DiGiovanni} & &\textbf{Jesse Clifton}\\ \text{Center on Long-Term Risk} & &\text{Center on Long-Term Risk}\\ \texttt{anthony.digiovanni@longtermrisk.org} & &\texttt{jesse.clifton@longtermrisk.org}\\ \end{array}\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-4daec5c06eadb1e0f1fb4944d92e808e_l3.png "Rendered by QuickLaTeX.com")
Abstract
The conditional commitment abilities of mutually transparent computer agents have been studied in previous work on commitment games and program equilibrium. This literature has shown how these abilities can help resolve Prisoner’s Dilemmas and other failures of cooperation in complete information settings. But inefficiencies due to private information have been neglected thus far in this literature, despite the fact that these problems are pervasive and might also be addressed by greater mutual transparency. In this work, we introduce a framework for commitment games with a new kind of conditional commitment device, which agents can use to conditionally reveal private information. We prove a folk theorem for this setting that provides sufficient conditions for ex post efficiency, and thus represents a model of ideal cooperation between agents without a third-party mediator. Connecting our framework with the literature on strategic information revelation, we explore cases where conditional revelation can be used to achieve full cooperation while unconditional revelation cannot. Finally, extending previous work on program equilibrium, we develop an implementation of conditional information revelation. We show that this implementation forms program  -Bayesian Nash equilibria corresponding to the Bayesian Nash equilibria of these commitment games.
-Bayesian Nash equilibria corresponding to the Bayesian Nash equilibria of these commitment games.
KEYWORDS
Cooperative AI, program equilibrium, smart contractsACM Reference Format:
Anthony DiGiovanni and Jesse Clifton. 2022. Commitment games with conditional information revelation. In Appears at the 4th Games, Agents, and Incentives Workshop (GAIW 2022). Held as part of the Workshops at the 20th International Conference on Autonomous Agents and Multiagent Systems., Auckland, New Zealand, May 2022, IFAAMAS, 14 pages.
Contents
- Abstract
- 1 Introduction
- 2 Related Work
- 3 Preliminaries: Games of Incomplete Information and Inefficiency
- 4 Commitment Games with Conditional Information Revelation
- 5 Other Conditions for Efficiency and Counterexamples
- 6 Implementation of Conditional Type Revelation via Robust Program Equilibrium
- 7 Discussion
- Acknowledgements
- References
- A Partial Unraveling Example
- B Proof of Theorem 2
1 Introduction
What are the upper limits on the ability of rational, self-interested agents to cooperate? As autonomous systems become increasingly responsible for important decisions, including in interactions with other agents, the study of “Cooperative AI” [2] will potentially help ensure these decisions result in cooperation. It is well-known that game-theoretically rational behavior — which will potentially be more descriptive of the decision-making of advanced computer agents than humans — can result in imperfect cooperation, in the sense of inefficient outcomes. Some famous examples are the Prisoner’s Dilemma and the Myerson-Satterthwaite impossibility of efficient bargaining under incomplete information [20]. Fearon [4] explores “rationalist” explanations for war (i.e., situations in which war occurs in equilibrium); these include Prisoner’s Dilemma-style inability to credibly commit to peaceful alternatives to war, as well as incentives to misrepresent private information (e.g., military strength). Because private information is so ubiquitous in real strategic interactions, resolving these cases of inefficiency is a fundamental open problem. Inefficiencies due to private information will be increasingly observed in machine learning, as machine learning is used to train agents in complex multi-agent environments featuring private information, such as negotiation. For example, Lewis et al. [16] found that when an agent was trained with reinforcement learning on negotiations under incomplete information, it failed to reach an agreement with humans more frequently than a human-imitative model did.
But greater ability to make commitments and share private information can open up more efficient equilibria. Computer systems could be much better at making their internal workings legible to other agents, and at making sophisticated conditional commitments. More mutually beneficial outcomes could also be facilitated by new technologies like smart contracts [30]. This makes the game theory of interactions between agents with these abilities important for the understanding of Cooperative AI — in particular, for developing an ideal standard of multi-agent decision making with future technologies. An extreme example of the power of greater transparency and commitment ability is Tennenholtz [29] ’s “program equilibrium” solution to the one-shot Prisoner’s Dilemma. The players in Tennenholtz’s “program game” version of the Prisoner’s Dilemma submit computer programs to play on their behalf, which can condition their outputs on each other’s source code. Then a pair of programs with the source code  form an equilibrium of mutual cooperation.
form an equilibrium of mutual cooperation.
In this spirit, we are interested in exploring the kinds of cooperation that can be achieved by agents who are capable of extreme mutual transparency and credible commitment. We can think of this as giving an upper bound on the ability of advanced artificially intelligent agents, or humans equipped with advanced technology for commitment and transparency, to achieve efficient outcomes. While such abilities are inaccessible to current systems, identifying sufficient conditions for cooperation under private information provides directions for future research and development, in order to avoid failures of cooperation. These are our main contributions:
- We develop a new class of games in which players can condition both their commitments and revelation of private information on their counterparts’ commitments and decisions to reveal private information. We present a folk theorem for these games: The set of equilibrium payoffs equals the set of feasible and interim individually rational payoffs, notably including all ex post efficient payoffs. The equilibria are conceptually straightforward: For a given ex post payoff profile, players reveal their private information and play according to an action profile attaining that payoff profile; if anyone deviates, they revert to a punishment strategy (without revealing private information to the deviator). The problem is to avoid circularity in these conditional decisions. Our result builds on Forges [5] ’ folk theorem for Bayesian games without conditional information revelation, in which equilibrium payoffs must also be incentive compatible. This expansion of the set of equilibrium payoffs is important, because in several settings, such as those of the classic Myerson-Satterthwaite theorem [20], ex-post efficiency (or optimality according to some function of social welfare) and incentive compatibility are mutually exclusive.
- Due to findings that the ability to unconditionally reveal private information often leads players to reveal that information [7, 18 , 19], one might suspect that conditional revelation is unnecessary. It is not. We present examples where our assumptions allow for ex-post efficiency but the ability to unconditionally reveal private information does not.
- In these commitment games, the conditional commitment and revelation devices are abstract objects. The devices in Forges [5] ’s and our folk theorems avoid circularity by conditioning on the particular identities of the other players’ devices, but this precludes robust cooperation with other devices that would output the same decisions. Using computer programs as conditional commitment and revelation devices, we give a specific implementation of -Bayesian Nash equilibria corresponding to the equilibria of our commitment game. This approach extends Oesterheld [21] ’s “robust program equilibria.” We solve the additional problems of (1) ensuring that the programs terminate with more than two players, (2) in circumstances where cooperating with other players requires knowing their private information. Ours is the first study of program equilibrium [29] under private information.
2 Related Work
Commitment games and program equilibrium. We build on commitment games, introduced by Kalai et al. [11] and generalized to Bayesian games (without verifiable revelation) by Forges [5]. In a commitment game, players submit commitment devices that can choose actions conditional on other players’ devices. This leads to folk theorems: Players can choose commitment devices that conditionally commit to playing a target action (e.g., cooperating in a Prisoner’s Dilemma), and punishing if their counterparts do not play accordingly (e.g., defecting in a Prisoner’s Dilemma if counterparts’ devices do not cooperate). A specific kind of commitment game is one played between computer agents who can condition their behavior on each other’s source code. This is the focus of the literature on program equilibrium [1, 15 , 21 , 22 , 25 , 29]. Peters and Szentes [24] critique the program equilibrium framework as insufficiently robust to new contracts, because the programs in, e.g., Kalai et al . [11] ’s folk theorem only cooperate with the exact programs used in the equilibrium profile. Like ours, the commitment devices in Peters and Szentes [24] can reveal their types and punish those that do not also reveal. However, their devices reveal unconditionally and thus leave the punishing player exploitable, restricting the equilibrium payoffs to a smaller set than that of Forges [5] or ours.
Our folk theorem builds directly on Forges [5]. In Forges’ setting, players lack the ability to reveal private information. Thus the equilibrium payoffs must be incentive compatible. We instead allow (conditional) verification of private information, which lets us drop Forges’ incentive compatibility constraint on equilibrium payoffs. Our program equilibrium implementation extends Oesterheld [21] ’s robust program equilibrium to allow for conditional information revelation.
Strategic information revelation. In games of strategic information revelation, players have the ability to verifiably reveal some or all of their private information. The question then becomes: How much private information should players reveal (if any), and how should other players update their beliefs based on players’ refusal to reveal some information? A foundational result in this literature is that of full unraveling: Under a range of conditions, when players can verifiably reveal information, they will act as if all information has been revealed [7, 18, 19]. This means the mere possibility of verifiable revelation is often enough to avoid informational inefficiencies. However, there are cases where unraveling fails to hold, and informational inefficiencies persist even when verifiable revelation is possible. This can be due to uncertainty about a player’s ability to verifiably reveal [3, 26] or revelation being costly [8, 10]. But revelation of private information can fail even without such uncertainty or costs [14 , 17]. We will review several such examples in Section 5, show how the persistence of uncertainty in these settings can lead to welfare losses, and show how this can be remedied with the commitment technologies of our framework (but not weaker ones, like those of Forges [5]).
3 Preliminaries: Games of Incomplete Information and Inefficiency
3.1 Definitions
Let  be a Bayesian game with
be a Bayesian game with  players. Each player
players. Each player  has a space of types
has a space of types  , giving joint type space
, giving joint type space  . At the start of the game, players' types are sampled by Nature according to the common prior
. At the start of the game, players' types are sampled by Nature according to the common prior  . Each player knows only their type. Player 's strategy is a choice of action
. Each player knows only their type. Player 's strategy is a choice of action  for each type in . Let
for each type in . Let  denote player 's expected payoff in this game when the players have types
denote player 's expected payoff in this game when the players have types  and follow an action profile
and follow an action profile  . A Bayesian Nash equilibrium is an action profile
. A Bayesian Nash equilibrium is an action profile  in which every player and type plays a best response with respect to the prior over other players' types: For all players and all types
in which every player and type plays a best response with respect to the prior over other players' types: For all players and all types  ,
,  . An -Bayesian Nash equilibrium is similar: Each player and type expects to gain at most (instead of 0) by deviating from .
. An -Bayesian Nash equilibrium is similar: Each player and type expects to gain at most (instead of 0) by deviating from .
We assume players can correlate their actions by conditioning on a trustworthy randomization device  . For any correlated strategy
. For any correlated strategy  (a distribution over action profiles), let
(a distribution over action profiles), let  . When it is helpful, we will write
. When it is helpful, we will write  to clarify the subset of the type profile on which the correlated strategy is conditioned. Let
to clarify the subset of the type profile on which the correlated strategy is conditioned. Let  denote a correlated strategy whose
denote a correlated strategy whose  th entry is degenerate at
th entry is degenerate at  , and the actions of players other than are sampled from
, and the actions of players other than are sampled from  independently of . Then, the following definitions will be key to our discussion:
independently of . Then, the following definitions will be key to our discussion:
DEFINITION 1. A payoff vector  as a function of type profiles is feasible if there exists a correlated strategy
as a function of type profiles is feasible if there exists a correlated strategy  such that, for all players and types
such that, for all players and types  ,
, 
DEFINITION 2. A payoff is interim individually rational (INTIR) if, for each player , there exists a correlated strategy  used by the other players such that, for all ,
used by the other players such that, for all , 
The minimax strategy  is used by the other players to punish player . The threat of such punishments will support the equilibria of our folk theorem. Players only have sufficient information to use this correlated strategy if they reveal their types to each other. Moreover, the punishment can only work in general if they do not reveal their types to player , because the definition of INTIR requires the deviator to be uncertain about
is used by the other players to punish player . The threat of such punishments will support the equilibria of our folk theorem. Players only have sufficient information to use this correlated strategy if they reveal their types to each other. Moreover, the punishment can only work in general if they do not reveal their types to player , because the definition of INTIR requires the deviator to be uncertain about  . Since the inequalities hold for all , the players do not need to know player 's type to punish them.
. Since the inequalities hold for all , the players do not need to know player 's type to punish them.
DEFINITION 3. A feasible payoff induced by is incentive compatible (IC) if, for each player and type pair  ,
, 
Incentive compatibility means that each player prefers a given correlated strategy to be played according to their type, as opposed to that of another type.
DEFINITION 4. Given a type profile  , a payoff is ex post efficient (hereafter, "efficient") if there does not exist
, a payoff is ex post efficient (hereafter, "efficient") if there does not exist  such that
such that  for all and
for all and  for some
for some 
We will also consider games with strategic information revelation, i.e., Bayesian games where, immediately after learning their types, players are able to reveal their private information as follows. Players simultaneously each choose  from some revelation action set
from some revelation action set  , which is a subset of
, which is a subset of  . Then, all players observe each~, thus learning that player 's type is in . Revelation is verifiable in the sense that a player's choice of must contain their true type, i.e., they cannot falsely "reveal" a different type. We will place our results on conditional type revelation in the context of the literature on unraveling:
. Then, all players observe each~, thus learning that player 's type is in . Revelation is verifiable in the sense that a player's choice of must contain their true type, i.e., they cannot falsely "reveal" a different type. We will place our results on conditional type revelation in the context of the literature on unraveling:
DEFINITION 5. Let  be the profile of revelation actions (as functions of types) in a Bayesian Nash equilibrium
be the profile of revelation actions (as functions of types) in a Bayesian Nash equilibrium  of a game with strategic information revelation. Then has full unraveling if
of a game with strategic information revelation. Then has full unraveling if  for all , or partial unraveling if
for all , or partial unraveling if  is a strict subset of for at least one
is a strict subset of for at least one 
3.2 Inefficiency: Running example
Uncertainty about others' private information, and a lack of ability or incentive to reveal that information, can lead to inefficient outcomes in Bayesian Nash equilibrium (or an appropriate refinement thereof). Here is a running example we will use to illustrate how informational problems can be overcome under our assumptions, but not under the weaker assumption of unconditional revelation ability.
Example 3.1 (War under incomplete information, adapted from Slantchev and Tarar [27] ). Two countries  are on the verge of war over some territory. Country 1 offers a split of the territory giving fractions
are on the verge of war over some territory. Country 1 offers a split of the territory giving fractions  and
and  to countries 1 and 2, respectively. If country 2 rejects this offer, they go to war. Each player wins with some probability (detailed below), and each pays a cost of fighting
to countries 1 and 2, respectively. If country 2 rejects this offer, they go to war. Each player wins with some probability (detailed below), and each pays a cost of fighting  . The winner receives a payoff of 1, and the loser gets 0.
. The winner receives a payoff of 1, and the loser gets 0.
The countries' military strength determines the probability that country 2 wins the war, denoted  . Country
. Country  doesn't know whether the other's army is weak (with type
doesn't know whether the other's army is weak (with type  ) or strong (
) or strong ( ), while country 1's strength is common knowledge. Further, country 2 has a weak point, which country 1 believes is equally likely to be in one of two locations
), while country 1's strength is common knowledge. Further, country 2 has a weak point, which country 1 believes is equally likely to be in one of two locations  . Thus country
. Thus country  's type is given by
's type is given by  . Country 1 can make a sneak attack on
. Country 1 can make a sneak attack on  , independent of whether they go to war. Country 1 would gain
, independent of whether they go to war. Country 1 would gain  from attacking
from attacking  , costing
, costing  for country 2. But incorrectly attacking
for country 2. But incorrectly attacking  would cost
would cost  for country 1, so country 1 would not risk an attack given a prior of
for country 1, so country 1 would not risk an attack given a prior of  on each of the locations. If country 2 reveals its full type by allowing inspectors from country 1 to assess its military strength
on each of the locations. If country 2 reveals its full type by allowing inspectors from country 1 to assess its military strength  , country 1 will also learn
, country 1 will also learn  .
.
If country 1 has a sufficiently low prior that country 2 is strong, then war occurs in the unique perfect Bayesian equilibrium when country 2 is strong. Moreover, this can happen even if the countries can fully reveal their private information to one another. In other words, the unraveling of private information does not occur, because player 2 will be made worse off if they allow player 1 to learn about their weak point.
Before looking at what is achievable with different technologies for information revelation, we need to formally introduce our framework for commitment games with conditional information revelation. In the next section, we describe these games and present our folk theorem.
4 Commitment Games with Conditional Information Revelation
4.1 Setup
Players are faced with a "base game" , a Bayesian game with strategic information revelation as defined in Section 3.1. In our framework, a commitment game is a higher-level Bayesian game in which the type distribution is the same as that of , and actions are devices that define mappings from other players' devices to actions in (conditional on one's type). We assume  for all players and types , i.e., players are at least able to reveal their exact types or not reveal any new information. They additionally have access to devices that can condition (i) their actions in and (ii) the revelation of their private information on other players' devices. Upon learning their type , player chooses a commitment device
for all players and types , i.e., players are at least able to reveal their exact types or not reveal any new information. They additionally have access to devices that can condition (i) their actions in and (ii) the revelation of their private information on other players' devices. Upon learning their type , player chooses a commitment device  from an abstract space of devices
from an abstract space of devices  . These devices are mappings from the player's type to a response function and a type revelation function. As in Kalai et al . [11] and Forges [5], we will define these functions so as to allow players to condition their decisions on each other's decisions without circularity.
. These devices are mappings from the player's type to a response function and a type revelation function. As in Kalai et al . [11] and Forges [5], we will define these functions so as to allow players to condition their decisions on each other's decisions without circularity.
Let  be the domain of the randomization device . The response function is
be the domain of the randomization device . The response function is  . (This notation, adopted from Forges [5], distinguishes the player's action-determining function from the action itself.) Given the other players' devices
. (This notation, adopted from Forges [5], distinguishes the player's action-determining function from the action itself.) Given the other players' devices  and a signal
and a signal  given by the realized value of the random variable , player 's action in after the revelation phase is
given by the realized value of the random variable , player 's action in after the revelation phase is  .2 Conditioning the response on permits players to commit to (correlated) distributions over actions. Second, we introduce type revelation functions
.2 Conditioning the response on permits players to commit to (correlated) distributions over actions. Second, we introduce type revelation functions  , which are not in the framework of Forges [5]. The th entry of
, which are not in the framework of Forges [5]. The th entry of  indicates whether player reveals their type to player , i.e., player learns
indicates whether player reveals their type to player , i.e., player learns  if this value is 1 or
if this value is 1 or  if it is
if it is  . (We can restrict attention to cases where either all or no information is revealed, as our folk theorem shows that such a revelation action set is sufficient to enforce each equilibrium payoff profile.) Thus, each player can condition their action on the others' private information revealed to them via
. (We can restrict attention to cases where either all or no information is revealed, as our folk theorem shows that such a revelation action set is sufficient to enforce each equilibrium payoff profile.) Thus, each player can condition their action on the others' private information revealed to them via  . Further, they can choose whether to reveal their type to another player, via
. Further, they can choose whether to reveal their type to another player, via  , based on that player's device. Thus players can decide not to reveal private information to players whose devices are not in a desired device profile, and instead punish them.
, based on that player's device. Thus players can decide not to reveal private information to players whose devices are not in a desired device profile, and instead punish them.
Then, the commitment game  is the one-shot Bayesian game in which each player 's strategy is a device
is the one-shot Bayesian game in which each player 's strategy is a device  , as a function of their type. After devices are simultaneously and independently submitted (potentially as a draw from a mixed strategy over devices), the signal is drawn from the randomization device , and players play the induced action profile
, as a function of their type. After devices are simultaneously and independently submitted (potentially as a draw from a mixed strategy over devices), the signal is drawn from the randomization device , and players play the induced action profile  in . Thus the ex post payoff of player in from a device profile
in . Thus the ex post payoff of player in from a device profile  is
is  .
.
4.2 Folk theorem
Our folk theorem consists of two results: First, any feasible and INTIR payoff can be achieved in equilibrium (Theorem 1). As a special case of interest, then, any efficient payoff can be attained in equilibrium. Second, all equilibrium payoffs in are feasible and INTIR (Proposition 1).
THEOREM 1. Let be any commitment game. For type profile , let  be a correlated strategy inducing a feasible and INTIR payoff profile
be a correlated strategy inducing a feasible and INTIR payoff profile  . Let
. Let  be a punishment strategy that is arbitrary except, if is the only player with
be a punishment strategy that is arbitrary except, if is the only player with  , let be the minimax strategy against player . Conditional on the signal , let
, let be the minimax strategy against player . Conditional on the signal , let  be the deterministic action profile, called the target action profile, given by
be the deterministic action profile, called the target action profile, given by  , and let
, and let  be the deterministic action profile given by . For all players and types , let be such that:
be the deterministic action profile given by . For all players and types , let be such that:

Then, the device profile is a Bayesian Nash equilibrium of .
PROOF. We first need to check that the response and type revelation functions only condition on information available to the players. If all players use , then by construction of they all reveal their types to each other, and so are able to play conditioned on their type profile (regardless of whether the induced payoff is IC). If at least one player uses some other device, the players who do use still share their types with each other, thus they can play  .
.
Suppose player deviates from . That is, player 's strategy in is  . Note that the outputs of player 's response and type revelation functions induced by
. Note that the outputs of player 's response and type revelation functions induced by  may in general be the same as those returned by
may in general be the same as those returned by  . We will show that punishes deviations from the target action profile regardless of these outputs, as long as there is a deviation in functions
. We will show that punishes deviations from the target action profile regardless of these outputs, as long as there is a deviation in functions  or
or  . Let
. Let  . Then:
. Then:

This last expression is the ex interim payoff of the proposed commitment given that the other players use  , therefore is a Bayesian Nash Equilibrium.
, therefore is a Bayesian Nash Equilibrium.
PROPOSITION 1. Let be any commitment game. If a device profile is a Bayesian Nash equilibrium of , then the induced payoff is feasible and INTIR.
PROOF. Let be the strategy profile of . Then by hypothesis  so is feasible. Suppose that for some player , for all correlated strategies there exists a type
so is feasible. Suppose that for some player , for all correlated strategies there exists a type  such that:
such that:

Let  . Then if player with type deviates to
. Then if player with type deviates to  such that
such that  :
:

This contradicts the assumption that is the payoff of a Bayesian Nash equilibrium, therefore is INTIR.
Our assumptions do not imply the equilibrium payoffs are IC (unlike Forges [5]). Suppose a player 's payoff would increase if the players conditioned the correlated strategy on a different type (i.e., not IC). This does not imply that a profit is possible by deviating from the equilibrium, because in our setting the other players' actions are conditioned on the type revealed by . In particular, as in our proposed device profile, they may choose to play their part of the target action profile only if all other players' devices reveal their (true) types.
5 Other Conditions for Efficiency and Counterexamples
The assumptions that give rise to this class of commitment games with conditional information revelation are stronger than the ability to unconditionally reveal private information. Recalling the unraveling results from Section 2, unconditional revelation ability is sometimes sufficient for the full revelation of private information, or for revelation of the information that prohibits incentive compatibility, and thus the possibility of efficiency in equilibrium. But this is not always true, whereas efficiency is always attainable in equilibrium under our assumptions. We first show that full unraveling fails in our running example when country 2 has a weak point. Then, we discuss conditions under which the ability to partially reveal private information is sufficient for efficiency, and examples where these conditions don’t hold.
5.1 Analysis of running example
Since country 2 can only either reveal both its strength and weak point , or neither, in our formalism of strategic information revelation  . If country 2 rejects the offer , players go to a war that country 2 wins with probability
. If country 2 rejects the offer , players go to a war that country 2 wins with probability  if its army is weak, or
if its army is weak, or  if strong.
if strong.
Assume country 2 is strong and the prior probability of a strong type is  . In the perfect Bayesian equilibrium of (without type revelation) country 1 offers
. In the perfect Bayesian equilibrium of (without type revelation) country 1 offers  , which country 2 rejects [27]. That is, if country 1 believes country 2 is unlikely to be strong, country 1 makes the smallest offer that only a weak type would accept. Thus with private information the countries go to war and receive inefficient payoffs in equilibrium. A strong country 2 also prefers not to reveal its type unconditionally. Although this would guarantee that country 1 best-responds with
, which country 2 rejects [27]. That is, if country 1 believes country 2 is unlikely to be strong, country 1 makes the smallest offer that only a weak type would accept. Thus with private information the countries go to war and receive inefficient payoffs in equilibrium. A strong country 2 also prefers not to reveal its type unconditionally. Although this would guarantee that country 1 best-responds with  , which country 2 would accept, given knowledge of the weak point country 1 prefers to attack it and receive an extra payoff with certainty, costing for country 2. Country 2 would therefore be worse off by than in equilibrium without revelation, where its expected payoff is
, which country 2 would accept, given knowledge of the weak point country 1 prefers to attack it and receive an extra payoff with certainty, costing for country 2. Country 2 would therefore be worse off by than in equilibrium without revelation, where its expected payoff is  .
.
However, if country 2 can reveal its full type if and only if country 1 commits to  that country 2 accepts, and commits not to attack , the countries can avoid war in equilibrium. The profile
that country 2 accepts, and commits not to attack , the countries can avoid war in equilibrium. The profile  is not IC, and hence cannot be achieved under the assumptions of Forges [5] alone, because a weak country 2 would prefer the strong type's payoff
is not IC, and hence cannot be achieved under the assumptions of Forges [5] alone, because a weak country 2 would prefer the strong type's payoff  (absent type-conditional commitment by country 1). In this example, conditional type revelation is required for efficiency due to a practical inability to reveal military strength without also revealing a vulnerability (Table 1). In other words, country 2's revelation action set
(absent type-conditional commitment by country 1). In this example, conditional type revelation is required for efficiency due to a practical inability to reveal military strength without also revealing a vulnerability (Table 1). In other words, country 2's revelation action set  is too restricted for full unraveling to occur. Interactions between advanced artificially intelligent agents may feature similar problems necessitating our framework. For example, if revelation requires sharing source code or the full set of parameters of a neural network that lacks cleanly separated modules, unconditional revelation risks exposing exploitable information. See also example 7 of Okuno-Fujiwara et al. [23] in which full unraveling fails because a firm does not want to reveal a secret technology that provides a competitive advantage, leading to inefficiency because other private information is not revealed.
is too restricted for full unraveling to occur. Interactions between advanced artificially intelligent agents may feature similar problems necessitating our framework. For example, if revelation requires sharing source code or the full set of parameters of a neural network that lacks cleanly separated modules, unconditional revelation risks exposing exploitable information. See also example 7 of Okuno-Fujiwara et al. [23] in which full unraveling fails because a firm does not want to reveal a secret technology that provides a competitive advantage, leading to inefficiency because other private information is not revealed.
5.2 Efficiency with unconditional revelation
Full unraveling. If full unraveling occurs in the base game , then the ability to conditionally reveal information becomes irrelevant. For example, consider a modification of Example 3.1 in which there is no weak point, i.e., country 's type is  rather than . A strong country 2 that can verify its strength to country 1 prefers to do so, since this does not also help country 1 exploit it. But because of this, if country 2 refuses to reveal its strength and it is common knowledge that country 2 could verifiably reveal, country 1 knows country 2 is weak. Thus, all types are revealed in equilibrium without conditioning on country 1's commitment.
rather than . A strong country 2 that can verify its strength to country 1 prefers to do so, since this does not also help country 1 exploit it. But because of this, if country 2 refuses to reveal its strength and it is common knowledge that country 2 could verifiably reveal, country 1 knows country 2 is weak. Thus, all types are revealed in equilibrium without conditioning on country 1's commitment.
Some sufficient and necessary conditions for full unraveling have been derived. Hagenbach et al . [9] show that given verifiable revelation, full unraveling is guaranteed if there are no cycles in the directed graph defined by types that prefer to pretend to be each other. For full unraveling in some classes of games with multidimensional types, it is necessary for one of the players' payoff to be sufficiently nonconvex in the other's beliefs [17]. In Appendix A, we give an example where this condition fails, thus unconditional revelation is insufficient even without exploitable information. However, even for games with full unraveling, the framework of Forges [5] is still insufficient for equilibria with non-IC payoffs, since that framework does not allow verifiable revelation (conditional or otherwise).
| Full | Partial | |
| Conditional | feasible, INTIR | feasible, INTIR |
| Unconditional | feasible, INTIR, {full unraveling or IC} | feasible, INTIR, {full unraveling or IC after unraveling} |
Partial revelation and post-unraveling incentive compatibility. If in our original example country 2 could partially reveal its type, i.e., only the probability of winning a war but not its weak point, conditional revelation would not be necessary (Table 1). This is because the strategy inducing the efficient payoff profile  depends only on the part of country 2's type that is revealed by the unraveling argument. Country 2 does not profit from lying about its exploitable, non-unraveled information — that is, the payoff is IC with respect to that information, even if not IC in the pre-unraveling game. Thus country 1 does not need to know this information for the efficient payoff to be achieved in equilibrium. Formally, in this case
depends only on the part of country 2's type that is revealed by the unraveling argument. Country 2 does not profit from lying about its exploitable, non-unraveled information — that is, the payoff is IC with respect to that information, even if not IC in the pre-unraveling game. Thus country 1 does not need to know this information for the efficient payoff to be achieved in equilibrium. Formally, in this case  , i.e., country 2 can choose to reveal any
, i.e., country 2 can choose to reveal any  , producing an equilibrium of partial unraveling. We can generalize this observation with the following proposition.
, producing an equilibrium of partial unraveling. We can generalize this observation with the following proposition.
PROPOSITION 2. Suppose that the devices in do not have revelation functions, and is a game of strategic information revelation with  for all
for all  . Let be updated to have support on the subset
. Let be updated to have support on the subset  of types remaining after unraveling. As in Forges [5], assume is conditioned on . Then a payoff profile is achievable in a Bayesian Nash equilibrium of if and only if it is feasible, INTIR, and IC (with respect to the post-unraveling game and updated ).
of types remaining after unraveling. As in Forges [5], assume is conditioned on . Then a payoff profile is achievable in a Bayesian Nash equilibrium of if and only if it is feasible, INTIR, and IC (with respect to the post-unraveling game and updated ).
PROOF. This is an immediate corollary of Propositions 1 and 2 of Forges [5], applied to the base game induced by unraveling (that is, with a prior updated on types being in the space  ).
).
To our knowledge, it is an open question which conditions are sufficient and necessary for partial unraveling such that the efficient payoffs of the post-unraveling game are IC. An informal summary of Proposition 2 and characterizations of equilibrium payoffs under our framework and that of Forges [5] is: Given conditional commitment ability, efficiency can be achieved in equilibrium if and only if there is sufficiently strong incentive compatibility, conditional and verifiable revelation ability, or an intermediate combination of these (see Table 1).
Proposition 2 is not vacuous; there exist games in which, given the ability to partially, verifiably, and unconditionally reveal their private information, players end up in an inefficient equilibrium that is Pareto-dominated by a non-IC payoff. Consequently, the alternatives to conditional information revelation that we have considered are not sufficient to achieve all feasible and INTIR payoffs even when partial revelation is possible. The game in Appendix A is one example where such a payoff is efficient. In the following example, the only efficient payoff is IC. However, the set of equilibrium payoffs is smaller than under our assumptions, and excludes some potentially desirable outcomes. For example, there is a non-IC -efficient payoff that improves upon the strictly efficient payoff in utilitarian welfare (sum of all players' payoffs).
Example 5.1 (All-pay auction under incomplete information from Kovenock et al. [14]). Two firms participate in an all-pay auction. Each firm has a private valuation ![s_i \stackrel{\text{iid}}{\sim} \text{Unif}[0,1]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-3fc8510e98c1817498c60ca4c4544ff9_l3.png "Rendered by QuickLaTeX.com") of a good. After observing their respective valuations, players simultaneously choose whether to reveal them. Then they simultaneously submit bids
of a good. After observing their respective valuations, players simultaneously choose whether to reveal them. Then they simultaneously submit bids  , and the higher bid wins the good, with a tie broken by a fair coin. Thus player 's payoff is
, and the higher bid wins the good, with a tie broken by a fair coin. Thus player 's payoff is ![s_i(\mathbb{I}[x_i \geq x_{-i}] - \frac{1}{2}\mathbb{I}[x_i = x_{-i}]) - x_i](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-a962c3b5b76326f1f7d06483809403db_l3.png "Rendered by QuickLaTeX.com") . There is a Bayesian Nash equilibrium of this base game in which
. There is a Bayesian Nash equilibrium of this base game in which  , and neither player reveals their valuation [14]. In this equilibrium, each player's ex interim payoff is:
, and neither player reveals their valuation [14]. In this equilibrium, each player's ex interim payoff is:

The ex post payoffs are  if
if  ,
,  if
if  , and
, and  otherwise.
otherwise.
Now, let  , and consider the following strategy . For type profiles such that , let
, and consider the following strategy . For type profiles such that , let  and
and  . For
. For  , let
, let  and
and  . Otherwise, let
. Otherwise, let  . Then:
. Then:

Thus the payoff induced by is feasible and INTIR, because it exceeds the ex interim equilibrium payoff. This is also an ex post Pareto improvement on the equilibrium, because the ex post payoffs are  if ,
if ,  if , and
if , and  otherwise. Finally, this payoff is not IC, because if , player 1 would profit from conditioned on a type
otherwise. Finally, this payoff is not IC, because if , player 1 would profit from conditioned on a type  .
.
Note that the payoffs  and
and  , i.e., the case of
, i.e., the case of  , are not feasible. This non-IC payoff thus requires and is inefficient by a margin of
, are not feasible. This non-IC payoff thus requires and is inefficient by a margin of  . However, in practice the players may favor this payoff over . This is because the non-IC payoff is -welfare optimal, since whenever
. However, in practice the players may favor this payoff over . This is because the non-IC payoff is -welfare optimal, since whenever  for either player, the supremum of the sum of payoffs is
for either player, the supremum of the sum of payoffs is  .
.
6 Implementation of Conditional Type Revelation via Robust Program Equilibrium
Having shown that conditional commitment and revelation devices solve problems that are intractable under other assumptions, we next consider how players can practically (and more robustly) implement these abstract devices. In particular, can players achieve efficient equilibria without using the exact device profile in Theorem 1, which can only cooperate with itself? We now develop an implementation showing that this is possible, after providing some background.
Oesterheld [21] considers two computer programs playing a game. Each program can simulate the other. He constructs a program equilibrium — a pair of programs that form an equilibrium of this game — using “instantaneous tit-for-tat” strategies.
In the Prisoner’s Dilemma, the pseudocode for these programs (called " ") is:
") is:  These programs cooperate with each other and punish defection. Note that these programs are recursive, but guaranteed to terminate because of the probability that a program will output Cooperate unconditionally.
These programs cooperate with each other and punish defection. Note that these programs are recursive, but guaranteed to terminate because of the probability that a program will output Cooperate unconditionally.
We use this idea to implement conditional commitment and revelation devices. For us, "revealing private information and playing according to the target action profile" is analogous to cooperation in the construction of . We will first describe the appropriate class of programs for program games under private information. Then we develop our program,  (where "SIR" stands for "strategic information revelation"), and show that it forms a
(where "SIR" stands for "strategic information revelation"), and show that it forms a  -Bayesian Nash equilibrium of a program game. Pseudocode for is given in Algorithm 1.
-Bayesian Nash equilibrium of a program game. Pseudocode for is given in Algorithm 1.
Player 's strategy in the program game is a choice  from the program space
from the program space  , a set of computable functions from
, a set of computable functions from  to
to  . A program returns either an action or a type revelation vector. Each program takes as input the players' program profile, the signal
. A program returns either an action or a type revelation vector. Each program takes as input the players' program profile, the signal  , and a boolean that equals 1 if the program's output is an action, and 0 otherwise.
, and a boolean that equals 1 if the program's output is an action, and 0 otherwise.
For brevity, we write  for a call to a program with the boolean set to , otherwise
for a call to a program with the boolean set to , otherwise  . Player 's action in the program game is a call to their program
. Player 's action in the program game is a call to their program  . (We refer to these initial program calls as the base calls to distinguish them from calls made by other programs.) Then, the ex post payoff of player in the program game is
. (We refer to these initial program calls as the base calls to distinguish them from calls made by other programs.) Then, the ex post payoff of player in the program game is  .
.
In addition to in the base game, we assume there is a randomization device  on which programs can condition their outputs. Like Oesterheld [21], we will use programs that unconditionally terminate with some small probability. By using to correlate decisions to unconditionally terminate, our program profile will be able to terminate with probability 1, despite the exponentially increasing number of recursive program calls. In particular, reads the call stack of the players' program profile. At each depth level
on which programs can condition their outputs. Like Oesterheld [21], we will use programs that unconditionally terminate with some small probability. By using to correlate decisions to unconditionally terminate, our program profile will be able to terminate with probability 1, despite the exponentially increasing number of recursive program calls. In particular, reads the call stack of the players' program profile. At each depth level  of recursion reached in the call stack, a variable
of recursion reached in the call stack, a variable  is independently sampled from
is independently sampled from ![\text{Unif}[0,1]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-6c39484077a038c632ed3dd4c805a4e3_l3.png "Rendered by QuickLaTeX.com") . Each program call at level can read off the values of and
. Each program call at level can read off the values of and  from . The index itself is not revealed, however, because programs that "know" they are being simulated would be able to defect in the base calls, while cooperating in simulations to deceive the other programs. To ensure that our programs terminate in play with a deviating program,
from . The index itself is not revealed, however, because programs that "know" they are being simulated would be able to defect in the base calls, while cooperating in simulations to deceive the other programs. To ensure that our programs terminate in play with a deviating program,  will call truncated versions of its counterparts' revelation programs: For
will call truncated versions of its counterparts' revelation programs: For  , let
, let ![[p_i]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-c7b11cbbdffde73b9534f1c31042ff1f_l3.png "Rendered by QuickLaTeX.com") denote
denote  with immediate termination upon calling another program.
with immediate termination upon calling another program.

checks if all other players' programs reveal their types (line 8 of Algorithm 1). If so, either with a small probability it unconditionally cooperates (line 11) — i.e., plays its part of the target action profile — or it cooperates only when all other programs cooperate (line 15). Otherwise, it punishes (line 17). In turn,  reveals its type unconditionally with probability (line 20). Otherwise, it reveals to a given player under two conditions (lines 25 and 28). First, player must reveal to the user. Second, they must play an action consistent with the desired equilibrium, i.e., cooperate when all players reveal their types, or punish otherwise. (See Figure 1.)
reveals its type unconditionally with probability (line 20). Otherwise, it reveals to a given player under two conditions (lines 25 and 28). First, player must reveal to the user. Second, they must play an action consistent with the desired equilibrium, i.e., cooperate when all players reveal their types, or punish otherwise. (See Figure 1.)
Unconditionally revealing one's type and playing the target action avoids an infinite regress. Crucially, these unconditional cooperation outputs are correlated through . Therefore, in a profile of copies of this program, either all copies unconditionally cooperate together, or none of them do so. Using this property, we can show (see proof of Theorem 2 in Appendix B) that a profile where all players use this program outputs the target action profile with certainty. If one player deviates, first, immediately punishes if that player does not reveal. If they do reveal, with some small probability the other players unconditionally cooperate, making this strategy slightly exploitable, but otherwise the deviator is punished. Even if deviation is punished, may unconditionally reveal. In our approach, this margin of exploitability is the price of implementing conditional commitment and revelation with programs that cooperate based on counterparts' outputs, rather than a strict matching of devices, without an infinite loop. Further, since a player is only able to unconditionally cooperate under incomplete information if they know all players' types, needs to prematurely terminate calls to programs thatndon't immediately unconditionally cooperate, but which may otherwise cause infinite recursion (line 4). This comes at the expense of robustness:  some players who may have otherwise cooperated, with low probability.
some players who may have otherwise cooperated, with low probability.
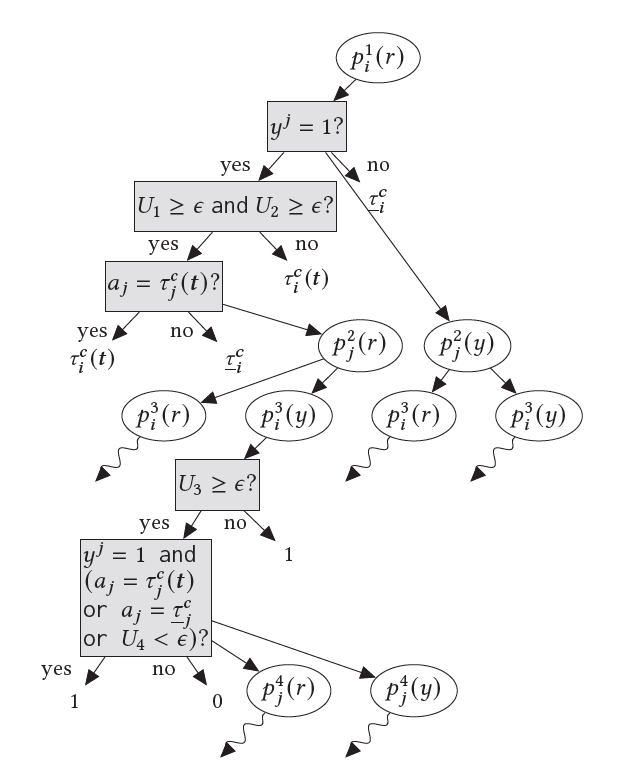 using , and player using an arbitrary program. An edge to a white node indicates a call to the program in that node; to a gray node indicates a check of the condition in that node; and to a node without a border indicates the output of the most recent parent white node. Wavy edges depict a call to the program in the parent node, with its child nodes omitted for space. Superscripts indicate the level of recursion.
using , and player using an arbitrary program. An edge to a white node indicates a call to the program in that node; to a gray node indicates a check of the condition in that node; and to a node without a border indicates the output of the most recent parent white node. Wavy edges depict a call to the program in the parent node, with its child nodes omitted for space. Superscripts indicate the level of recursion.THEOREM 2. Consider the program game induced by a base game and the program spaces  . Assume all strategies returned by these programs are computable. For type profile , let induce a feasible and INTIR payoff profile . Let be the minimax strategy if one player deviates, and arbitrary otherwise. Let
. Assume all strategies returned by these programs are computable. For type profile , let induce a feasible and INTIR payoff profile . Let be the minimax strategy if one player deviates, and arbitrary otherwise. Let  be the maximum payoff achievable by any player in , and
be the maximum payoff achievable by any player in , and  . Then the program profile given by Algorithm 1 (with
. Then the program profile given by Algorithm 1 (with  ) for players
) for players  , denoted
, denoted  , is a -Bayesian Nash equilibrium. That is, if players
, is a -Bayesian Nash equilibrium. That is, if players  play this profile, and player plays a program
play this profile, and player plays a program  that terminates with probability 1 given that any programs it calls terminate with probability 1, then:
that terminates with probability 1 given that any programs it calls terminate with probability 1, then:

PROOF SKETCH. We need to check (1) that the program profile terminates (a) with or (b) without a deviation, (2) that everyone plays the target action profile when no one deviates, and (3) that with high probability a deviation is punished. First suppose no one deviates. If  for two levels of recursion in a row, the calls to and all unconditionally reveal (line 21) of ) and output the target action (line 6 of ), respectively. Because these unconditional cooperative outputs are correlated through , the probability that at each pair of subsequent levels in the call stack is a nonzero constant. Thus it is guaranteed to occur eventually and cause termination in finite time, satisfying (1b). Moreover, each call to or in previous levels of the stack sees that the next level cooperates, and thus cooperates as well, ensuring that the base calls all output the target action profile. This shows (2).
for two levels of recursion in a row, the calls to and all unconditionally reveal (line 21) of ) and output the target action (line 6 of ), respectively. Because these unconditional cooperative outputs are correlated through , the probability that at each pair of subsequent levels in the call stack is a nonzero constant. Thus it is guaranteed to occur eventually and cause termination in finite time, satisfying (1b). Moreover, each call to or in previous levels of the stack sees that the next level cooperates, and thus cooperates as well, ensuring that the base calls all output the target action profile. This shows (2).
If, however, one player deviates, we use the same guarantee of a run of subsequent events to guarantee termination. First, all calls to non-deviating programs terminate, because any call to conditional on  forces termination (line 4) of calls to other players' revelation programs. Thus the deviating programs also terminate, since they call terminating non-deviating programs. This establishes (1a). Finally, in the high-probability event that the first two levels of calls to do not unconditionally cooperate, punishes the deviator as long as they do not reveal their type and play their target action. The punishing players will know each other's types, since a call to is guaranteed by line 28 to reveal to anyone who also punishes or unconditionally cooperates in the next level. Condition (3) follows.
forces termination (line 4) of calls to other players' revelation programs. Thus the deviating programs also terminate, since they call terminating non-deviating programs. This establishes (1a). Finally, in the high-probability event that the first two levels of calls to do not unconditionally cooperate, punishes the deviator as long as they do not reveal their type and play their target action. The punishing players will know each other's types, since a call to is guaranteed by line 28 to reveal to anyone who also punishes or unconditionally cooperates in the next level. Condition (3) follows.
A practical obstacle to program equilibrium is demonstrating to one’s counterpart that one’s behavior is actually governed by the source code that has been shared. In our program game with private information, there is the additional problem that, as soon as one’s source code is shared, one’s counterpart may be able to read off one’s private information (without revealing their own). Addressing this in practice might involve modular architectures, where players could expose the code governing their strategy without exposing the code for their private information. Alternatively, consider AI agents that can place copies of themselves in a secure box, where the copies can inspect each other’s full code but cannot take any actions outside the box. These copies read each other’s commitment devices off of their source code, and report the action and type outputs of these devices to the original agents. If any copy within the box attempts to transmit information that another agent’s device refused to reveal, the box deletes its contents. This protocol does not require a mediator or arbitrator; the agents and their copies make all the relevant strategic decisions, with the box only serving as a security mechanism. Applications of secure multi-party computation to machine learning [12], or privacy-preserving smart contracts [13] — with the original agents treated as the “public” from whom code shared among the copies is kept private — might facilitate the implementation of our proposed commitment devices.
7 Discussion
We have defined a new class of commitment games that allow revelation of private information conditioned on other players’ commitments. Our folk theorem shows that in these games, efficient payoffs are always attainable in equilibrium. Our examples, which draw on models of war and all-pay auctions, show how players with these capabilities can avoid welfare losses, while others (even with the ability to verifiably reveal private information) cannot. Finally, we have provided an implementation of this framework via robust program equilibrium, which can be used by computer programs that read each other’s source code.
While conceptually simple, satisfying these assumptions in practice requires a strong degree of mutual transparency and conditional commitment ability, which is not possessed by contemporary human institutions or AI systems. Thus, our framework represents an idealized standard for bargaining in the absence of a trusted third party, suggesting research priorities for the field of Cooperative AI [2]. The motivation forwork on this standard is that AI agents with increasing economic capabilities, which would exemplify game-theoretic rationality to a stronger degree than humans, may be deployed in contexts where they make strategic decisions on behalf of human principals [6]. Given the potential for game-theoretically rational behavior to cause cooperation failures [4, 20], it is important that such agents are developed in ways that ensure they are able to cooperate effectively.
Commitment devices of this form would be particularly useful in cases where centralized institutions (Dafoe et al. [2], Section 4.4) for enforcing or incentivizing cooperation fail, or have not been constructed due to collective action problems. This is because our devices do not require a trusted third party, aside from correlation devices. A potential obstacle to the use of these commitment devices is lack of coordination in development of AI systems. This may lead to incompatibilities in commitment device implementation, such that one agent cannot confidently verify that another’s device meets its conditions for trustworthiness and hence type revelation. Given that commitments may be implicit in complex parametrizations of neural networks, it is not clear that independently trained agents will be able to understand each other’s commitments without deliberate coordination between developers. Our program equilibrium approach allows for the relaxation of the coordination requirements needed to implement conditional information revelation and commitment. Coordination on target action profiles for commitment devices or flexibility in selection of such profiles, in interactions with multiple efficient and arguably “fair” profiles [28], will also be important for avoiding cooperation failures due to equilibrium selection problems.
Acknowledgements
We thank Lewis Hammond for helpful comments on this paper and thank Caspar Oesterheld both for useful comments and for identifying an important error in an earlier version of one of our proofs.
References
[1] Andrew Critch. 2019. A parametric, resource-bounded generalization of Löb’s theorem, and a robust cooperation criterion for open-source game theory. The Journal of Symbolic Logic 84, 4 (2019), 1368–1381.
[2] Allan Dafoe, Edward Hughes, Yoram Bachrach, Tantum Collins, Kevin R. McKee, Joel Z. Leibo, Kate Larson, and Thore Graepel. 2020. Open Problems in Cooperative AI. arXiv:2012.08630 [cs.AI]
[3] Ronald A Dye. 1985. Disclosure of nonproprietary information. Journal of accounting research (1985), 123–145.
[4] James D Fearon. 1995. Rationalist explanations for war. International organization 49, 3 (1995), 379–414.
[5] Françoise Forges. 2013. A folk theorem for Bayesian games with commitment. Games and Economic Behavior 78 (2013), 64–71. https://doi.org/10.1016/j.geb.2012.11.004
[6] Edward Geist and Andrew J. Lohn. 2018. How might artificial intelligence affect the risk of nuclear war? Rand Corporation.
[7] Sanford J Grossman. 1981. The informational role of warranties and private disclosure about product quality. The Journal of Law and Economics 24, 3 (1981), 461–483.
[8] Sanford J Grossman and Oliver D Hart. 1980. Disclosure laws and takeover bids. The Journal of Finance 35, 2 (1980), 323–334.
[9] Jeanne Hagenbach, Frédéric Koessler, and Eduardo Perez-Richet. 2014. Certifiable Pre-play Communication: Full Disclosure. Econometrica 82, 3 (2014), 1093–1131. http://www.jstor.org/stable/24029308
[10] Boyan Jovanovic. 1982. Truthful disclosure of information. The Bell Journal of Economics (1982), 36–44.
[11] Adam Tauman Kalai, Ehud Kalai, Ehud Lehrer, and Dov Samet. 2010. A commitment folk theorem. Games and Economic Behavior 69, 1 (2010), 127–137.
[12] Brian Knott, Shobha Venkataraman, Awni Hannun, Shubhabrata Sengupta, Mark Ibrahim, and Laurens van der Maaten. 2021. CrypTen: Secure Multi-Party Computation Meets Machine Learning. In Advances in Neural Information Processing Systems, A. Beygelzimer, Y. Dauphin,
P. Liang, and J. Wortman Vaughan (Eds.). https://openreview.net/forum?id=dwJyEMPZ04I
[13] Ahmed Kosba, Andrew Miller, Elaine Shi, Zikai Wen, and Charalampos Papamanthou. 2016. Hawk: The Blockchain Model of Cryptography and Privacy-Preserving Smart Contracts. In 2016 IEEE Symposium on Security and Privacy (SP). 839–858. https://doi.org/10.1109/SP.2016.55
[14] Dan Kovenock, Florian Morath, and Johannes Münster. 2015. Information sharing in contests. Journal of Economics & Management Strategy 24 (2015), 570–596. Issue 3.
[15] Patrick LaVictoire, Benja Fallenstein, Eliezer Yudkowsky, Mihaly Barasz, Paul Christiano, and Marcello Herreshoff. 2014. Program Equilibrium in the Prisoner’s Dilemma via Löb’s Theorem. In Workshops at the Twenty-Eighth AAAI Conference on Artificial Intelligence.
[16] Mike Lewis, Denis Yarats, Yann N. Dauphin, Devi Parikh, and Dhruv Batra. 2017. Deal or No Deal? End-to-End Learning for Negotiation Dialogues. https://doi.org/10.48550/ARXIV.1706.05125
[17] Giorgio Martini. 2018. Multidimensional Disclosure. http://www.giorgiomartini.com/papers/multidimensional_disclosure.pdf
[18] Paul Milgrom and John Roberts. 1986. Relying on the information of interested parties. The RAND Journal of Economics (1986), 18–32.
[19] Paul R Milgrom. 1981. Good news and bad news: Representation theorems and applications. The Bell Journal of Economics (1981), 380–391.
[20] Roger B Myerson and Mark A Satterthwaite. 1983. Efficient mechanisms for bilateral trading. Journal of economic theory 29, 2 (1983), 265–281.
[21] Caspar Oesterheld. 2019. Robust program equilibrium. Theory and Decision 86, 1 (2019), 143–159.
[22] Caspar Oesterheld and Vincent Conitzer. 2021. Safe Pareto Improvements for Delegated Game Playing. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems. 983–991.
[23] Masahiro Okuno-Fujiwara, Andrew Postlewaite, and Kotaro Suzumura. 1990. Strategic Information Revelation. The Review of Economic Studies 57, 1 (1990), 25–47. http://www.jstor.org/stable/2297541
[24] Michael Peters and Balázs Szentes. 2012. Definable and Contractible Contracts. Econometrica 80 (2012), 363–411.
[25] Ariel Rubinstein. 1998. Modeling Bounded Rationality. The MIT Press.
[26] Hyun Song Shin. 1994. The burden of proof in a game of persuasion. Journal of Economic Theory 64, 1 (1994), 253–264.
[27] Branislav L Slantchev and Ahmer Tarar. 2011. Mutual optimism as a rationalist explanation of war. American Journal of Political Science 55, 1 (2011), 135–148.
[28] Julian Stastny, Maxime Riché, Alexander Lyzhov, Johannes Treutlein, Allan Dafoe, and Jesse Clifton. 2021. Normative Disagreement as a Challenge for Cooperative AI. arXiv:2111.13872 [cs.MA]
[29] Moshe Tennenholtz. 2004. Program equilibrium. Games and Economic Behavior 49, 2 (2004), 363–373.
[30] Hal R Varian. 2010. Computer mediated transactions. American Economic Review 100, 2 (2010), 1–10.
A Partial Unraveling Example
Consider the following game of strategic information revelation. We will show that in this game, there is a perfect Bayesian equilibrium that is inefficient, and there is an efficient payoff profile that is not IC. (That is, in this game, unconditional and partial type revelation and the framework of Forges [5] are not sufficient to achieve efficiency.) This example is inspired by the model in Martini [17].
Player 2 is a village that lives around the base of a treacherous mountain (i.e., along the left and bottom sides of ![[0,1]^2](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-afc980486b9d25732c7953dcb85b429f_l3.png "Rendered by QuickLaTeX.com") ). Their warriors are camped somewhere on the mountain, with coordinates
). Their warriors are camped somewhere on the mountain, with coordinates  . Player 1 has no information on the warriors' location, hence the prior is
. Player 1 has no information on the warriors' location, hence the prior is ![(\theta_x, \theta_y) \sim \text{Unif}[0,1]^2](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-a879d92c865d4e0995d2818168e1a4f3_l3.png "Rendered by QuickLaTeX.com") . But they know that warriors at higher altitudes are tougher; strength is proportional to
. But they know that warriors at higher altitudes are tougher; strength is proportional to  . As in Example 3.1, player 1 can offer a split
. As in Example 3.1, player 1 can offer a split  of disputed territory. If the players fight, then player 1 will send in paratroopers at a location
of disputed territory. If the players fight, then player 1 will send in paratroopers at a location  to fight player 2's warriors at a cost proportional to their strength . They want to get as close as possible to minimize exposure to the elements, consumption of rations, etc (i.e., minimize the squared distance
to fight player 2's warriors at a cost proportional to their strength . They want to get as close as possible to minimize exposure to the elements, consumption of rations, etc (i.e., minimize the squared distance  ). Meanwhile, player 2 wants the paratroopers to land as far from their village as possible, i.e., they want to maximize
). Meanwhile, player 2 wants the paratroopers to land as far from their village as possible, i.e., they want to maximize  . Player 2 wins the ensuing battle with probability equal to their army's strength, i.e., .
. Player 2 wins the ensuing battle with probability equal to their army's strength, i.e., .
Formally, the game is as follows. Only player 2 has private information, . Player 2 has the unrestricted revelation action set  . First, player 2 chooses
. First, player 2 chooses  . Then player 1 chooses
. Then player 1 chooses ![s \in [0,1]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-5ef62fd38ae9616fcf994079ac344646_l3.png "Rendered by QuickLaTeX.com") . Player 2 can either accept or reject . If player 2 accepts, the pair of payoffs is
. Player 2 can either accept or reject . If player 2 accepts, the pair of payoffs is  . Otherwise, player 1 plays
. Otherwise, player 1 plays ![(t_x, t_y) \in [0,1]^2](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-c88731e539aff2c1b2f7c61fd7d2002b_l3.png "Rendered by QuickLaTeX.com") , and for
, and for  :
:

Let  for any function
for any function  . Define:
. Define:
![\begin{align*} t^*(s) &= \begin{cases} \frac{3-\sqrt{5}}{2},& \text{if } s > c_2 - \frac{3-\sqrt{5}}{2} + 1\\ \frac{(3-\sqrt{5})(c_2 - s - 1)}{2} + 1,& \text{otherwise}. \end{cases}\\ r(s) &= 1 - s - t^*(s) + c_2 \\ q_{U_1(s)}(\theta_x, \theta_y) &= \frac{\mathbb{I}[\min\{\theta_x, \theta_y\} \leq t^*(s)]}{t^*(s)(2 - t^*(s))} \\ q_{U_2(s)}(\theta_x, \theta_y) &= \frac{\mathbb{I}[\min\{\theta_x, \theta_y\} \in (r^+(s), t^*(s)]]}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ p(s) &= \mathbb{I}[r(s) \geq t^*(s)] + \mathbb{I}[r(s) < t^*(s)] \cdot \frac{r^+(s)(2 - r^+(s))}{t^*(s)(2 - t^*(s))} \\ m_1(s) &= \frac{(r^+(s)^4 - r^+(s)^3 - r^+(s)) - (t^*(s)^4 - t^*(s)^3 - t^*(s))}{3(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ m_2(s) &= \frac{t^*(s)^2 - r^+(s)^2 - \frac{2}{3}(t^*(s)^3 - r^+(s)^3)}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ s^* &= \textrm{arg\,max}_s sp(s) + (1 - 2m_2(s) - 2(m_1(s) - t^*(s)^2) - c_1)(1-p(s)) \\ s(\theta_x,\theta_y) &= 1 - 2\min\{\theta_x, \theta_y\} + c_2 \end{align*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-476389862e87f63540389854850cbd27_l3.png "Rendered by QuickLaTeX.com")
Then, we claim:
PROPOSITION 3. Let  . Let player 1's strategy be
. Let player 1's strategy be  then
then  conditional on a given if player 2 does not reveal their type, otherwise
conditional on a given if player 2 does not reveal their type, otherwise  then . Let player 2's strategy be to reveal any and only types for which
then . Let player 2's strategy be to reveal any and only types for which  , and to accept any and only
, and to accept any and only  . Let player 1's belief update to
. Let player 1's belief update to  conditional on player 2 not revealing their type, and to
conditional on player 2 not revealing their type, and to  conditional on player 2 not revealing their type and rejecting .
conditional on player 2 not revealing their type and rejecting .
Then these strategies and beliefs are a perfect Bayesian equilibrium. Further, there exist  such that this equilibrium is inefficient, and the payoff profile
such that this equilibrium is inefficient, and the payoff profile  is (1) a Pareto improvement on the equilibrium payoff and (2) not IC.
is (1) a Pareto improvement on the equilibrium payoff and (2) not IC.
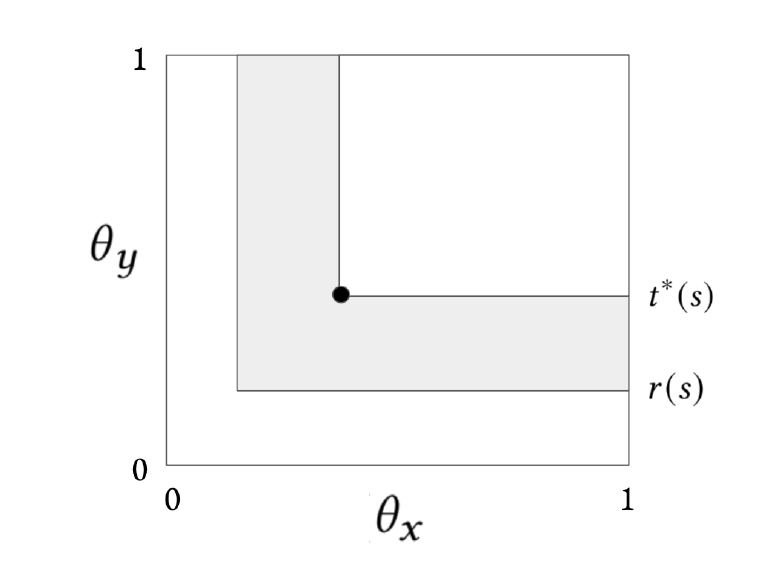 given in the shaded region. The black dot denotes
given in the shaded region. The black dot denotes  , player 1's optimal given a posterior that is uniform on the shaded region. Unraveling stabilizes into this region because any types for which
, player 1's optimal given a posterior that is uniform on the shaded region. Unraveling stabilizes into this region because any types for which  prefer to reveal, otherwise they prefer not to reveal, and types for which
prefer to reveal, otherwise they prefer not to reveal, and types for which  prefer to accept .
prefer to accept .PROOF. We proceed by backward induction. If player 2 has not revealed their type and has rejected , then given beliefs , we solve for the optimal . Player 1's expected payoff is  . The squared loss is minimized at . This is equivalent to the average of the centers of rectangles whose union composes the region
. The squared loss is minimized at . This is equivalent to the average of the centers of rectangles whose union composes the region ![\min\{\theta_x, \theta_y\} \in [r^+(s), t^*(s)]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-632d17dc21c63ad2482fbec61acf04be_l3.png "Rendered by QuickLaTeX.com") (see Figure 2), weighted by the areas of these rectangles, which can be shown to be:
(see Figure 2), weighted by the areas of these rectangles, which can be shown to be:

Thus is a best response. If player 2 has revealed their type and rejected , then player 1's payoff is maximized at  .
.
Next, player 2's best response to any is to accept if and only if the acceptance payoff exceeds the rejection payoff given player 1's strategy, that is,  .
.
Then, given beliefs  for each , player 1's optimal if player 2 does not reveal is:
for each , player 1's optimal if player 2 does not reveal is:

Given player 2's strategy,
![\[P(\text{accept } s) = P(1 - s \geq t^*(s) + \min\{\theta_x, \theta_y\} - c_2) = P(\min\{\theta_x, \theta_y\} \leq r(s)).\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-ae9d9d9f1ba4a0e69ab4c53a5f5e8234_l3.png "Rendered by QuickLaTeX.com")
Since is uniform on  , this probability is given by the ratio of the areas of the regions
, this probability is given by the ratio of the areas of the regions  and . Thus
and . Thus  . We have:
. We have:

It can be shown (Lemma 3) that  and
and  . Therefore is of the form given above.
. Therefore is of the form given above.
If player 2 reveals, in the analysis above we now have:
![\begin{align*} \mathbb{E}_{q_{U_2(s)}}(u_1 | \text{reject } s) &= 1 - 2\min\{\theta_x, \theta_y\} - c_1 \\ P(\text{accept } s) &= \mathbb{I}[1 - s \geq 2 \min\{\theta_x, \theta_y\} - c_2] \\ \mathbb{E}(u_1) &= \begin{cases} s,& \text{if } s \leq 1 - 2\min\{\theta_x, \theta_y\} + c_2\\ 1 - 2\min\{\theta_x, \theta_y\} - c_1,& \text{otherwise}. \end{cases} \end{align*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-4e7458bc1af7edd1ee0c45a7c9dd6650_l3.png "Rendered by QuickLaTeX.com")
Thus  is optimal, since
is optimal, since  increases with up to
increases with up to  , after which it drops to
, after which it drops to  .
.
It can be shown that  , and so
, and so  and
and  for any type. Given these responses, if player 2 does not reveal their type, their payoff is
for any type. Given these responses, if player 2 does not reveal their type, their payoff is  . If player 2 reveals their type, since we have shown that , player 2's payoff is
. If player 2 reveals their type, since we have shown that , player 2's payoff is  , and so player 2 prefers to reveal if and only if .
, and so player 2 prefers to reveal if and only if .
Finally, by the above strategy for player 2's type revelation, if player 2 does not reveal, to be consistent player 1 must update to the uniform distribution on the region defined by  . Thus is consistent. If player 2 also rejects , player 1 knows that , that is,
. Thus is consistent. If player 2 also rejects , player 1 knows that , that is,  . Thus the updated belief is uniform on
. Thus the updated belief is uniform on ![\min\{\theta_x, \theta_y\} \in (r(s^*), t^*(s^*)]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-99720dc52f706abdd70148d797086e65_l3.png "Rendered by QuickLaTeX.com") , so
, so  is consistent. This proves that the proposed strategy profile and beliefs are a perfect Bayesian equilibrium.
is consistent. This proves that the proposed strategy profile and beliefs are a perfect Bayesian equilibrium.
Given , all player 2 types reject (offered if player 2 does not reveal) in equilibrium, since  . The equilibrium payoffs for any types that do not reveal are:
. The equilibrium payoffs for any types that do not reveal are:

Consider the payoff profile
![\[(s_P(\theta_x,\theta_y), 1-s_P(\theta_x,\theta_y)) = (1 - t^*(1) - \min\{\theta_x, \theta_y\} + c_2, t^*(1) + \min\{\theta_x, \theta_y\} - c_2),\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-37eee71d30752adef498fbde6461ace1_l3.png "Rendered by QuickLaTeX.com")
induced by the strategy profile in which player 1 offers  and player 2 accepts any
and player 2 accepts any  . This is feasible because player 2 only reveals if
. This is feasible because player 2 only reveals if  , and
, and  , so
, so  . For this to be a Pareto improvement on the perfect Bayesian equilibrium, it is sufficient that
. For this to be a Pareto improvement on the perfect Bayesian equilibrium, it is sufficient that  . This payoff profile is not IC, because player 2's payoff increases with , so any player 2 for which
. This payoff profile is not IC, because player 2's payoff increases with , so any player 2 for which  can profit from the strategy profile above conditioned on a type
can profit from the strategy profile above conditioned on a type  such that
such that  .
.
LEMMA 3. Given as defined above, and .
PROOF. We have:
![\begin{align*} \mathbb{E}_{q_{U_2(s)}}(\min\{\theta_x, \theta_y\}) = \frac{\int_0^1 \int_0^1 \min\{\theta_x, \theta_y\} \mathbb{I}[\min\{\theta_x, \theta_y\} \in [r^+(s),t^*(s)]] d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))}\end{align*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-a91d04d095f123d1560352b91024d250_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} &= \frac{\int_0^1 \int_0^{\theta_y} \theta_x \mathbb{I}[\theta_x \in [r^+(s),t^*(s)]] d\theta_x d\theta_y + \int_0^1 \int_{\theta_y}^1 \theta_y \mathbb{I}[\theta_y \in [r^+(s),t^*(s)]] d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\&= \frac{\int_0^1 \int_{\min\{\theta_y,t^*(s), r^+(s)\}}^{\min\{\theta_y, t^*(s)\}} \theta_x d\theta_x d\theta_y + \int_{r^+(s)}^{t^*(s)} \int_{\theta_y}^{1} \theta_y d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= \frac{\frac{1}{2}\int_0^1 (\min\{\theta_y, t^*(s)\}^2 - \min\{\theta_y,t^*(s),r^+(s)\}^2) d\theta_y + \int_{r^+(s)}^{t^*(s)} \theta_y (1 - \theta_y) d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= \frac{\frac{1}{2}\int_0^{t^*(s)} \theta_y^2 d\theta_y + \frac{1}{2}\int_{t^*(s)}^1 t^*(s)^2 d\theta_y - \frac{1}{2}\int_0^{r^+(s)} \theta_y^2 d\theta_y - \frac{1}{2}\int_{r^+(s)}^1 r^+(s)^2 d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &+ \frac{\frac{1}{2}(t^*(s)^2 - r^+(s)^2) - \frac{1}{3}(t^*(s)^3 - r^+(s)^3)}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= \tfrac{\frac{1}{6}t^*(s)^3 + \frac{1}{2}(1-t^*(s)) t^*(s)^2 - \frac{1}{6}r^+(s)^3 - \frac{1}{2}(1-r^+(s)) r^+(s)^2 + \frac{1}{2}(t^*(s)^2 - r^+(s)^2) - \frac{1}{3}(t^*(s)^3 - r^+(s)^3)}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\&= m_2(s). \end{align*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-8562ffad57496dff2f50a7f94b6a3d6c_l3.png "Rendered by QuickLaTeX.com")
We showed above that  Further,
Further,
![\[\mathbb{V}_{q_{U_2(s)}} \theta_x = \mathbb{E}_{q_{U_2(s)}} \theta_x^2 - (\mathbb{E}_{q_{U_2(s)}} \theta_x)^2,\]](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-a7065ef7f6f4653970eb0a8e868686ef_l3.png "Rendered by QuickLaTeX.com")
so:
![\begin{align*} \mathbb{E}_{q_{U_2(s)}} \theta_x^2 &= \frac{\int_0^1 \int_0^1 \theta_x^2 \mathbb{I}[\min\{\theta_x, \theta_y\} \in [r^+(s),t^*(s)]] d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= \frac{\int_0^1 \int_0^1 \theta_x^2 \mathbb{I}[\min\{\theta_x, \theta_y\} \geq r^+(s)] d\theta_x d\theta_y - \int_0^1 \int_0^1 \theta_x^2 \mathbb{I}[\min\{\theta_x, \theta_y\} \geq t^*(s)] d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= \frac{\int_{r^+(s)}^1 \int_{r^+(s)}^1 \theta_x^2 d\theta_x d\theta_y - \int_{t^*(s)}^1 \int_{t^*(s)}^1 \theta_x^2 d\theta_x d\theta_y}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\&= \frac{\frac{1}{3}(1 - r^+(s))(1 - r^+(s)^3) - \frac{1}{3}(1 - t^*(s))(1 - t^*(s)^3)}{(t^*(s) - r^+(s))(2 - t^*(s) - r^+(s))} \\ &= m_1(s). \end{align*}](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-17b26cc470b4c19897f151a3efe7d0e2_l3.png "Rendered by QuickLaTeX.com")
B Proof of Theorem 2
Fix the programs of players as  . Suppose player uses
. Suppose player uses  . Given this assumption, we omit the subscripts of
. Given this assumption, we omit the subscripts of  and
and  . Let
. Let  and
and  respectively denote calls to and made at level . If and for some reached in the call stack, then every call to and
respectively denote calls to and made at level . If and for some reached in the call stack, then every call to and  immediately returns
immediately returns  . Consequently, every call to , which must be a parent call to , returns
. Consequently, every call to , which must be a parent call to , returns  because line 5 in evaluates to
because line 5 in evaluates to  . (Notice that the shared random variables
. (Notice that the shared random variables  are essentiall — if the programs unconditionally cooperated using independently sampled variables, an exponentially increasing number of variables would each need to be less than for all calls at a given level to return the cooperative output.) Let
are essentiall — if the programs unconditionally cooperated using independently sampled variables, an exponentially increasing number of variables would each need to be less than for all calls at a given level to return the cooperative output.) Let  be the event that and , and
be the event that and , and  be the event that
be the event that  and
and  . Thus for the program profile to terminate in finite time, it is sufficient to show that with probability 1 there exists a finite such that holds. Given that for
. Thus for the program profile to terminate in finite time, it is sufficient to show that with probability 1 there exists a finite such that holds. Given that for  are independent, because they do not overlap, we have:
are independent, because they do not overlap, we have:

Since  is the complement of the event we wanted to guarantee, this proves termination with probability 1. Further, the event is sufficient for every call of
is the complement of the event we wanted to guarantee, this proves termination with probability 1. Further, the event is sufficient for every call of  and
and  to return and , respectively, and this holds for all levels less than . Therefore all base calls of the programs in the proposed profile return the corresponding with probability 1.
to return and , respectively, and this holds for all levels less than . Therefore all base calls of the programs in the proposed profile return the corresponding with probability 1.
Now suppose player uses  . Let
. Let  be the smallest finite level such that
be the smallest finite level such that  ,
,  , and
, and  (which exists with probability 1 by a similar argument to that above). Then all
(which exists with probability 1 by a similar argument to that above). Then all  and
and  for return . Further, every
for return . Further, every  for calls the truncated programs
for calls the truncated programs ](https://longtermrisk.org/wp-content/ql-cache/quicklatex.com-ca79fa842f6fb73eea6ed4f3be0aa711_l3.png "Rendered by QuickLaTeX.com") for
for  , guaranteed to terminate by definition, thus terminates with either or
, guaranteed to terminate by definition, thus terminates with either or  . But because also guarantees that
. But because also guarantees that  terminates, all calls to the programs of made by player 's programs terminate. Thus all base calls of programs in this profile with one deviation terminate with probability 1.
terminates, all calls to the programs of made by player 's programs terminate. Thus all base calls of programs in this profile with one deviation terminate with probability 1.
We now consider the possible cases. Suppose  and
and  . First, note that any players using know each other's types. To see this, note that all calls to for return . So any call to
. First, note that any players using know each other's types. To see this, note that all calls to for return . So any call to  for will reveal to player if either
for will reveal to player if either  or . The second condition is satisfied by assumption. Inductively applying this argument for
or . The second condition is satisfied by assumption. Inductively applying this argument for  , note that if
, note that if  , we will only have
, we will only have  if (satisfying line 11 of ), but then this is sufficient to have
if (satisfying line 11 of ), but then this is sufficient to have  return (line 21). If player does not reveal their type, all players return . Otherwise, proceeds to line 13 for all players . If player plays
return (line 21). If player does not reveal their type, all players return . Otherwise, proceeds to line 13 for all players . If player plays  , then all other players also play , giving the target payoff profile. Otherwise, all players return . We therefore have that with probability at least
, then all other players also play , giving the target payoff profile. Otherwise, all players return . We therefore have that with probability at least  , all players use whenever the outputs of
, all players use whenever the outputs of  do not match those of . Hence:
do not match those of . Hence:

- A player who chooses to "not commit" submits a device that is not a function of the other players' devices. In this case, the other devices can only condition on this non-commitment choice, not on the particular action this player chooses.
- A player who chooses to "not commit" submits a device that is not a function of the other players' devices. In this case, the other devices can only condition on this non-commitment choice, not on the particular action this player chooses.