Annual Review & Fundraiser 2022
Contents
Summary
- Our goal: CLR’s goal is to reduce the worst risks of astronomical suffering (s-risks). Our concrete research programs are on AI conflict, Evidential Cooperation in Large Worlds (ECL), and s-risk macrostrategy. We ultimately want to identify and advocate for interventions that reliably shape the development and deployment of advanced AI systems in a positive way.
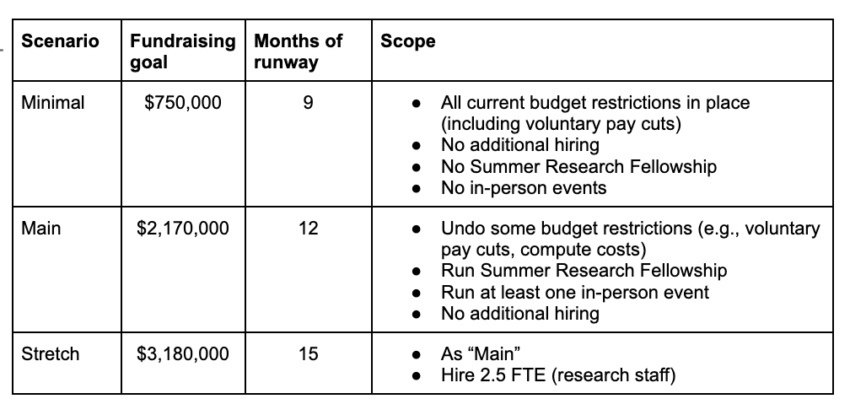
- Fundraising: We have had a short-term funding shortfall and a lot of medium-term funding uncertainty. Our minimal fundraising goal is $750,000. We think this is a particularly good time to donate to CLR for people interested in supporting work on s-risks, work on Cooperative AI, work on acausal interactions, or work on generally important longtermist topics.
- Causes of Conflict Research Group: In 2022, we started evaluating various interventions related to AI conflict (e.g., surrogate goals, preventing conflict-seeking preferences). We also started developing methods for evaluating conflict-relevant properties of large language models. Our priorities for next year are to continue developing and evaluating these, and to continue our work with large language models.
- Other researchers: In 2022, others researchers at CLR worked on topics including the implications of ECL, the optimal timing of AI safety spending, the likelihood of earth-originating civilization encountering extraterrestrials, and program equilibrium. Our priorities for the next year include continuing some of this work, alongside other work including on strategic modeling and agent foundations.
- S-risk community-building: Our s-risk community building programs received very positive feedback. We had calls or meetings with over 150 people interested in contributing to s-risk reduction. In 2023, we plan to at least continue our existing programs (i.e., intro fellowship, Summer Research Fellowship, retreat) if we can raise the required funds. If we can even hire additional staff, we want to expand our outreach function and create more resources for community members (e.g., curated reading lists, career guide, introductory content, research database).
What CLR is trying to do and why
Our goal is to reduce the worst risks of astronomical suffering (s-risks). These are scenarios where a significant fraction of future sentient beings are locked into intense states of misery, suffering, and despair.19 We currently believe that such lock-in scenarios most likely involve transformative AI systems. So we work on making the development and deployment of such systems safer.20
Concrete research programs:
- AI conflict: We want to better understand how we can prevent AI systems from engaging in catastrophic conflict. (The majority of our research efforts)
- Evidential21 Cooperation in Large Worlds (ECL): ECL refers to the idea that we make it more likely that other agents across the universe take actions that are good for our values by taking actions that are good according to their values. A potential implication is that we should act so as to maximize an impartial weighted sum of the values of agents across the universe.22
- S-risk macrostrategy: In general, we want to better understand how we can reduce suffering in the long-term future. There might be causes or considerations that we have overlooked so far.
Most of our work is research with the goal of identifying threat models and possible interventions. In the case of technical AI interventions (which is the bulk of our object-level work so far), we then plan to evaluate these interventions and advocate for their inclusion in AI development.
Next to our research, we also run events and fellowships to identify and support people wanting to work on these problems.
Fundraising
Funding situation
Due to recent events, we have had a short-term funding shortfall. This caused us to reduce our original budget for 2023 by 30% and take various cost-saving measures, including voluntary pay cuts by our staff, to increase our runway to six months.
Our medium-term funding situation is hard to predict at the moment, as there is still a lot of uncertainty. We hope to gain more clarity about this in the next few months.
Fundraising goals
Our minimal fundraising goal is to increase our runway to nine months, which would give us enough time to try and secure a grant from a large institutional funder in the first half of 2023. Our main goal is to increase our runway to twelve months and roll back some of the budget reductions, putting us in a more comfortable financial position again. Our stretch goal is to increase our runway to fifteen months and allow for a small increase in team size in 2023. See the table below for more details.
Reasons to donate to CLR
Given the financial situation sketched above, we believe that CLR is a good funding opportunity this year. Whether it makes sense for any given individual to donate to CLR depends on many factors. Below, we sketch the main reasons donors could be excited about our work. In an appendix, we collected some testimonials by people who have a lot of context on our work.
Supporting s-risk reduction.
You might want to support CLR’s work because it is one of the few organizations addressing risks of astronomical suffering directly.23 You could consider s-risk reduction worthwhile for a number of reasons: (1) You find the combination of suffering-focused ethics and longtermism compelling. (2) You think the expected value of the future is not sufficiently high to warrant prioritizing extinction risk reduction over improving the quality of the future. (3) You want to address the fact that work on s-risks is comparatively neglected within longtermism and AI safety.
Since the early days of our organization, we have made significant progress on clarifying and modeling the concrete threats we are trying to address and coming up with technical candidate interventions (see Appendix).
Supporting work on addressing AI conflict.
Next to the benefits to s-risk reduction, you might value some of our work because it addresses failure modes arising in multipolar AI scenarios more broadly (e.g., explored here, here). In recent years, we have helped to build up the field of Cooperative AI intended to address these risks (e.g., Stastny et al. 2021).
Supporting work on better understanding acausal interactions.
Such interactions are possibly a crucial consideration for longtermists (see, e.g., here). Some argue that, when acting, we should consider the non-causal implications of our actions (see, e.g., Ahmed (2014), Yudkowsky and Soares (2018), Oesterheld and Conitzer (2021)). If this is the case, these effects could dwarf their causal influence (see, e.g., here). Better understanding the implications of this would then be a key priority. CLR is among the few organizations doing and supporting work on this (e.g., here).
Much of our work on cooperation in the context of AI plausibly becomes particularly valuable from this perspective. For instance, if we are to act so as to maximize a compromise utility function that includes the values of many agents across the universe24, as the ECL argument suggests, then it becomes much more important that AI systems, even if aligned, cooperate well with agents with different values.25
Supporting cause-general longtermism research.
CLR has also done important research from a general longtermist lens, e.g., on decision theory, meta ethics, AI timelines, risks from malevolent actors, and extraterrestrial civilizations. Our Summer Research Fellowship has been a springboard for junior researchers who then moved on to other longtermist organizations (e.g., ARC, Redwood Research, Rethink Priorities, Longview Philanthropy).26
How to donate
To donate to CLR, please go to the Fundraiser page on our website.
- Donors from Germany, Switzerland, and the Netherlands can donate tax-deductibly via our website
- Donors from the USA and UK can donate tax-deductibly through the Giving What We Can platform
- Donors from all other countries can donate to us via our website, but unfortunately tax deduction will not be available. For donations >$10,000, please get in touch and we will see if we can facilitate a donation swap.
For frequently asked questions on donating to CLR, see our Donate page.
Our progress in 2022
Causes of Conflict Research Group
This group is led by Jesse Clifton. Members of the group are Anni Leskelä, Anthony DiGiovanni, Julian Stastny, Maxime Riché, Mia Taylor, and Nicolas Macé.
Subjective assessment
Have we made relevant research progress?27
We believe we have made significant progress (e.g., relative to previous years) on improving our expertise in the reasons why AI systems might engage in conflict and the circumstances under which technical work done now could reduce these risks. We’ve built up methods and knowledge that we expect to make us much better at developing and assessing interventions for reducing conflict. (Some of this is reflected in our public-facing work.) We have begun to capitalize on this in the latter part of 2022, as we’ve begun moving from improving our general picture of the causes of conflict and possibilities for intervention to developing and evaluating specific interventions. These interventions include surrogate goals, preventing conflict-seeking preferences, preventing commitment races, and developing cooperation-related content for a hypothetical manual for overseers of AI training.
The second main way in which we’ve made progress is the initial work we’ve done on the evaluation of large language models (LLMs). There are several strong arguments that those interested in intervening on advanced AI systems should invest in experimental work with existing AI systems (see, e.g., The case for aligning narrowly superhuman models). Our first step here has been to work on methods for evaluating cooperation-relevant behaviors and reasoning of LLMs, as these methods are prerequisites for further research progress. We are in the process of developing the first Cooperative AI dataset for evaluating LLMs as well as methods for automatically generating data on which to evaluate cooperation-relevant behaviors, which is a prerequisite for techniques like red-teaming language models with language models. We are preparing to submit this work to a machine learning venue. We have also begun developing methods for better understanding the reasoning abilities of LLMs when it comes to conflict situations in order to develop evaluations that could tell us when models have gained capabilities that are necessary to engage in catastrophic conflict.
Has the research reached its target audience?
We published a summary of our thinking (as of earlier this year) on when technical work to reduce AGI conflict makes a difference on the Alignment Forum/LessWrong, which is visible to a large part of our target audience (AI safety & longtermist thinkers). We have also shared internal documents with individual external researchers to whom they are relevant. A significant majority of the research that we’ve done this year has not been shared with target audiences, though. Much of this is work-in-progress on evaluating interventions and evaluating LLMs which will be incorporated into summaries shared directly with external stakeholders, and in some cases posted on the Alignment Forum/LessWrong or submitted for publication in academic venues.
What feedback on our work have we received from peers and our target audience?
Our Alignment Forum sequence When does technical work to reduce AGI conflict make a difference? didn’t get much engagement. We did receive some positive feedback on internal drafts of this sequence from external researchers. We also solicited advice from individual alignment researchers throughout the year. This advice was either encouraging of existing areas of research focus or led us to shift more attention to areas that we are now focusing on (summarized in “relevant research progress” section above).
Selected output
- Anthony DiGiovanni, Jesse Clifton: Commitment games with conditional information revelation. (to appear at AAAI 2023).
-
- Anthony DiGiovanni, Nicolas Macé, Jesse Clifton: Evolutionary Stability of Other-Regarding Preferences under Complexity Costs. Workshop on Learning, Evolution, and Games.
- Jesse Clifton, Samuel Martin, Anthony DiGiovanni: When does technical work to reduce AGI conflict make a difference? (Alignment Forum Sequence)
- Anthony DiGiovanni, Jesse Clifton: Sufficient Conditions for Cooperation Between Rational Agents, Working Paper.
Other researchers: Emery Cooper, Daniel Kokotajlo, Tristan Cook
Emery, Daniel28, and Tristan work on a mix of macrostrategy, ECL, decision theory, anthropics, forecasting, AI governance, and game theory.
Subjective assessment
Have we made relevant research progress?29
The main focus of Emery’s work in the last year has been on the implications of ECL for cause prioritization. This includes work on the construction of the compromise utility function30 under different anthropic and decision-theoretic assumptions, on the implications of ECL for AI design, and on more foundational questions. Additionally, Emery worked on a paper (in progress) extending our earlier Robust Program Equilibrium paper31. She also did some work on the implications of limited introspection ability for evidential decision theory (EDT) agents, and some related work on anthropics.
Daniel left for OpenAI early in the year, but not before making significant progress building a model of ECL and identifying key cruxes for the degree of decision relevance of ECL.
Tristan primarily worked on the optimal spending schedule for AI risk interventions and the probability that an Earth-originating civilization would encounter alien civilizations. To that end, he built and published two comprehensive models.
Overall, we believe we made moderate research progress, but Emery and Daniel have accumulated a large number of unpublished ideas to be written up.
Has the research reached its target audience?
The primary goal of Tristan’s reports was to inform CLR’s own prioritization. For example, the existence of alien civilizations in the far future is a consideration for our work on conflict. That said, Tristan’s work on Grabby Aliens received considerable engagement on the EA Forum and on LessWrong.
As mentioned above, a lot of Emery and Daniel’s work is not yet fully written up and published. Whilst the target audience for some of this work is internal, it’s nevertheless true that we haven’t been as successful in this regard as we would like. We have had fruitful conversations with non-CLR researchers about these topics, e.g., people at Open Philanthropy and MIRI.
What feedback on our work have we received from peers and our target audience?
The grabby aliens report was well received by and cited by S. Jay Olson (co-author of a recent paper on extraterrestrial civilizations with Toby Ord), who described it as “fascinating and complete”, and Tristan has received encouragement from Robin Hanson to publish academically, which he plans to do.
Selected output
- Emery Cooper, Caspar Oesterheld: Towards >2 player epsilon-grounded FairBot (Working title, forthcoming).
- Tristan Cook: Replicating and extending the grabby aliens model. EA Forum.
- Tristan Cook, Guillaume Corlouer: The optimal timing of spending on AGI safety work; why we should probably be spending more now. EA Forum.
- Tristan Cook: Neartermists should consider AGI timelines in their spending decisions. EA Forum.
- Daniel Kokotajlo: ECL Big Deal? (unpublished Google Doc, forthcoming).
- Daniel Kokotajlo: Immanuel Kant and the Decision Theory App Store. LessWrong.
S-Risk Community Building
Subjective assessment
Progress on all fronts seems very similar to last year, which we characterized as “modest”.
Have we increased the (quality-adjusted) size of the community?
Community growth has continued to be modest. We are careful in how we communicate about s-risks, so our outreach tools are limited. Still, we had individual contact with over 150 people who could potentially make contributions to our mission. Out of those, perhaps five to ten could turn out to be really valuable members of our community.
Have we created opportunities for in-person (and in-depth online) contact for people in our community?
We created more opportunities for discussion and exchange than before. We facilitated more visits to our office, hosted meetups around EAG, and we ran an S-Risk Retreat with about 30 participants. We wanted to implement more projects in this direction, but our limited staff capacity made that impossible.
Have we provided resources for community members that make it more likely they contribute significantly to our mission?
Our team has continued to provide several useful resources this year. We administered the CLR Fund, which supported various efforts in the community. We provided ad-hoc career advice to community members. We are currently experimenting with a research database prototype. We believe there are many more things we could be doing, but our limited staff capacity has held us back.
Output & activities
- S-Risk Intro Fellowship: In February and March, we ran two S-Risk Intro Fellowships with seven participants each. The participant feedback was generally very positive.32
- Summer Research Fellowship: We ran a Summer Research Fellowship with nine fellows.33 Again, feedback was generally very positive.34 Sylvester Kollin published two posts on decision theory in the context of the fellowship. David Udell moved on to work on shard theory. Hjalmar Wijk is now at ARC. Mia Taylor started working at CLR.
- S-Risk Retreat: In October, we ran an S-Risk Retreat with 33 participants. Again, feedback was generally very positive.35
- CLR Fund: We made the following grants in 2022:
-
- Johannes Treutlein: Top-up of a previous scholarship grant for a Master's degree at the University of Toronto.
- Samuel Martin: Six-month extension grant for research on whether work on reducing AI conflict is redundant with work on AI alignment.
- Anton L.: Funding for a two-month research project on the implications of normative uncertainty for whether to prioritize s-risks.
- Nandi Schoots: Funding for a three-month research project on simplicity bias in neural nets.
- Lukas Holter Melgaard: Funding for a three-month research project on summarizing Vanessa Kosoy’s Infrabayesianism.
- Tim Chan: Scholarship for completing a computer science conversion Master’s.
- Miranda Zhang: Funding for living expenses while working on clarifying her possible career paths.
- Bogdan-Ionut Cirstea: Funding for a year-long research project on short timelines.
- Asher Soryl: Research funding for a project on the ethics of panspermia, among others.
- Gary O'Brien: Teaching buy-out during the last year of their PhD to research (long-term) wild animal suffering.
- Individual outreach: We conducted over one hundred fifty 1:1 calls and meetings with potentially promising people. This also included various office visits by people.
General organizational health
Guiding question: Are we a healthy organization with sufficient operational capacity, an effective board, appropriate evaluation of our work, reliable policies and procedures, adequate financial reserves and reporting, and high morale?
Operational capacity
Our capacity is currently not as high as we would like it to be as a staff member left in the summer and we only recently made a replacement hire. So various improvements to our setup have been delayed (e.g., IT & security improvements, a systematic policy review, some visa-related issues, systematic risk management). That being said, we are still able to maintain all the important functions of the organization (i.e., accounting, payments, payroll, onboarding/offboarding, hiring support, office management, feedback & review, IT maintenance).
Board
Members of the board: Tobias Baumann, Max Daniel, Ruairi Donnelly (chair), Chi Nguyen, Jonas Vollmer.
The board are ultimately responsible for CLR. Their specific responsibilities include deciding CLR’s leadership and structure, engaging with the team about strategy and planning, resolving organizational conflicts, and advising and providing accountability for CLR leadership. In 2022 they considered various decisions related to CLR’s new office, hiring/promotion, and overall financials. The team generally considered their advice to be valuable.
Evaluation function
We collect systematic feedback on big community-building and operations projects through surveys and interviews. We collect feedback on our research by submitting articles to journals & conferences and by requesting feedback on drafts of documents from relevant external researchers.
Policies & guidelines
In 2022, we did not have any incidents that required a policy-driven intervention or required setting up new policies. Due to a lack of operational capacity in 2022, we failed to conduct a systematic review of all of our policies.
Financial health
See “Fundraising” section above.
Morale
We currently don’t track staff morale quantitatively. Our impression is that this varies significantly between staff members and is more determined by personal factors than organizational trends.
Our plans for next year
Causes of Conflict Research Group
Our plans for 2023 fall into three categories.
Evaluating large language models. We will continue building on the work on evaluating LLMs that we started this year. Beyond writing up and submitting our existing results, the priority for this line of work is scoping out an agenda for assessing cooperation-relevant capabilities. This will account for work on evaluation that’s being done by other actors in the alignment space and possible opportunities for eventually slotting into those efforts.
Developing and evaluating cooperation-related interventions. We will continue carrying out the evaluations of the interventions that we started this year. On the basis of these evaluations, we’ll decide which interventions we want to prioritize developing (e.g., working out in more detail how they would be implemented under various assumptions about what approaches to AI alignment will be taken). In parallel, we’ll continue developing content for an overseer’s manual for AI systems.
General s-risk macrostrategy. Some researchers on the team will continue spending some of their time thinking about s-risk prioritization more generally, e.g., thinking about the value of alternative priorities to our group’s current focus on AI conflict.
Other researchers: Emery Cooper, Daniel Kokotajlo, Tristan Cook
Emery plans to prioritize finishing and writing up her existing research on ECL. She also has plans for some more general posts on ECL, including on some common confusions, and on more practical implications for cause prioritization. Emery also plans to focus on finishing the paper extending Robust Program Equilibrium, and to explore further more object-level work.
Daniel no longer works at CLR but plans to organize a research retreat focused on ECL in the beginning of 2023.
Tristan broadly plans to continue strategy-related modeling, such as on the spread of information hazards. He also plans to help to complete a project that calculates the marginal utility of AI x-risk and s-risk work under different assumptions about AGI timelines, and to potentially contribute to work on ECL.
S-Risk Community Building
We had originally planned to expand our activities across all three community-building functions. Without additional capacity, we would have to curtail these plans.
Outreach. If resources allow, we will host another Intro Fellowship and Summer Research Fellowship. We will also continue our 1:1 meetings & calls. We also plan to investigate what kind of mass outreach within the EA community would be most helpful (e.g., online content, talks, podcasts). Without such outreach, we expect that community growth will stagnate at its current low rate.
Resources. We plan to create more long-lasting and low-marginal-cost resources for people dedicated to s-risk reduction (e.g., curated reading lists, career guide, introductory content, research database). As the community grows and diversifies, these resources will have to become more central to our work.
Exchange. If resources allow, we will host another S-Risk Retreat. We also want to experiment with other online and in-person formats. Again, as the community grows and diversifies, we need to find a replacement for more informal arrangements.
Appendix: Testimonials
Nate Soares (Executive Director, Machine Intelligence Research Institute): "My understanding of CLR's mission is that they're working to avoid fates worse than the destruction of civilization, especially insofar as those fates could be a consequence of misaligned superintelligence. I'm glad that someone on earth is doing CLR's job, and CLR has in the past seemed to me to occasionally make small amounts of legible-to-me progress in pursuit of their mission. (Which might sound like faint praise, and I sure would endorse CLR more full-throatedly if they spent less effort on what seem to me like obvious dead-ends, but at the same time it's not like anybody else is even trying to do their job, and their job is worthy of attempting. According to me, the ability to make any progress at all in this domain is laudable)"
Lukas Finnveden (Research Analyst, Open Philanthropy): “CLR’s focus areas seem to me like the most important areas for reducing future suffering. Within these areas, they’ve shown competence at producing new knowledge, and I’ve learnt a lot that I value from engaging with their research.”
Daniel Kokotajlo (Policy/Governance, OpenAI): “I think AI cooperation and s-risk reduction are high priority almost regardless of your values / ethical views. The main reason to donate to, or work for, CLR is that the best thinking about s-risks and AI cooperation happens here, better than the thinking at MIRI or Open Phil or anywhere else. CLR also contains solid levels of knowledge of AI governance, AI alignment, AI forecasting (less so now that I’m gone), cause prioritisation, metaethics, agent foundations, anthropics, aliens, and more. Their summer fellows program is high quality and has produced many great alumni. Their ops team is great & in general they are well-organized. I left CLR to join the OpenAI governance team because I was doing mostly AI forecasting which benefits from being in a lab — but I was very happy at CLR and may even one day return.”
Michael Aird (Senior Research Manager, Rethink Priorities): 'I enjoyed my time as a summer research fellow at CLR in 2020, and I felt like I learned a lot about doing research and about various topics related to longtermist strategy, AI risk, and ethics. I was also impressed by the organization's culture and how the organization and fellowship was run, and I drew on some aspects of that when helping to design a research fellowship myself and when starting to manage people.'
Testimonials by other Summer Research Fellows can be found here.
Appendix: Our progress so far
What follows below is a somewhat stylized/simplified account of the history of the Center on Long-Term Risk prior to 2022. It is not meant to capture every twist and turn.
2011-2016: Incubation phase
What is now called the “Center on Long-Term Risk” starts out as a student group in Switzerland. Under the name “Foundational Research Institute,” we do pre-paradigmatic research into possible risks of astronomical suffering and create basic awareness of these scenarios in the EA community. A lot of pioneering thinking is done by Brian Tomasik. In 2016, we coin the term “risks of astronomical suffering” (s-risks). Key publications from that period:
-
- Brian Tomasik (2011): Risks of Astronomical Future Suffering.
- Brian Tomasik (2015): Reasons to Be Nice to Other Value Systems.
- David Althaus, Lukas Gloor (2016): Reducing Risks of Astronomical Suffering. A Neglected Priority.
2016-2019: Early growth
More researchers join; the organization professionalizes and matures. We publish our first journal articles related to s-risks. Possible interventions are being developed and discussed, surrogate goals among them. In 2017, we start sharing our work with other researchers in the longtermist community. That culminates in a series of research workshops in 2019. Key publications from that period:
- Kaj Sotala, Lukas Gloor (2017): Superintelligence As a Cause or Cure For Risks of Astronomical Suffering. Informatica, 41 (4), 2017
- Caspar Oesterheld (2017): Multiverse-wide Cooperation via Correlated Decision Making.
- Tobias Baumann (2018): Using surrogate goals to deflect threats. (runner-up at the AI alignment prize)
- Caspar Oesterheld (2018: Robust program equilibrium. Theory and Decision (86).
- Caspar Oesterheld (2019): Approval-directed agency and the decision theory of Newcomb-like problems. Synthese (198). (Runner-up in the “AI alignment prize”)
- Caspar Oesterheld, Vince Conitzer (202136): Safe Pareto Improvements for Delegated Game Playing, Proc. of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2021), Online, May 3–7, 2021, IFAAMAS.
2019-2022: Maturation
Before 2019, we were pursuing many projects other than research on s-risks. In 2019, this stops. We start focusing exclusively on research. Increasingly, we connect our ideas to existing lines of academic inquiry. We also start engaging more with concrete proposals and empirical work in AI alignment. Key publications from that period:
-
- Jesse Clifton (2019): Cooperation, Conflict, and Transformative Artificial Intelligence. A Research Agenda.
- Daniel Kokotajlo (2019): The Commitment Races Problem.
- David Althaus, Tobias Baumann (2020): Reducing long-term risks from malevolent actors (EA forum prize, second place. First Decade Review, third prize.)
- Julian Stastny, Maxime Riché, Alexander Lyzhov, Johannes Treutlein, Allan Dafoe, Jesse Clifton (2021): Normative Disagreement as a Challenge for Cooperative AI. Cooperative AI workshop and the Strategic ML workshop at NeurIPS 2021.
- Daniel Kokotajlo (2021): AI Timelines sequence.
- Jesse Clifton, Anthony DiGiovanni, Samuel Martin (2022): When does technical work to reduce AGI conflict make a difference?
- Here is the more technical definition: S-risks are risks of events that bring about suffering in cosmically significant amounts. By “significant”, we mean significant relative to expected future suffering.
- We consider ourselves to be working on “AI safety”. Whether it is also encompassed by “AI alignment” depends on how broadly you define “alignment”. In any case, our work is fairly different from other work in AI alignment (also see this sequence).
- The term “evidential” here is potentially misleading: whilst ECL is often framed in terms of evidential decision theory (EDT), the argument is more general, and applies to many decision theories. One notable exception is causal decision theory (CDT), which for the most part does not endorse ECL. For more details on this, see the ECL paper itself.
- With little dependence on our own values.
- We don’t have the space here to make a case for CLR over other organizations focused on s-risks.
- With little dependence on our own values.
- That said, we currently believe that, although there might be significant overlap, there are likely still some important differences in focus between the portfolio of cooperation work recommended by ECL considerations and that recommended by thinking on s-risks ignoring ECL. We more generally want to ensure that in our work on ECL we consider other kinds of work that could be higher priority but which might be less salient to us.
- We have not systematically assessed to what extent CLR made a significant difference in the career trajectory of these researchers.
- We consider raising the salience of s-risks as potentially harmful. So much of our research remains unpublished. This makes a coherent and informative public review of our research progress difficult.
- Daniel was a Lead Researcher at CLR until mid-2022. He now works at OpenAI on the policy/governance team. However, he continues some other research projects in collaboration with CLR colleagues. He also mentors CLR Summer Research Fellows.
- We consider raising the salience of s-risks as potentially harmful. So much of our research remains unpublished. This makes a coherent and informative public review of our research progress difficult.
- I.e., the utility function that ECL considerations arguably recommend we act so as to optimize, formed as an impartial weighted sum of utility functions of agents across the universe.
- See also the 2016-2019 section of CLR’s history.
- “What is your overall satisfaction with the S-Risk Intro Fellowship?” (8/10), “To what extent has the S-Risk Intro Fellowship met your expectations?” (8.4/10), “How well did the S-Risk Intro Fellowship compare with the ideal intro fellowship?” (7.7/10), “If the same program happened next year, would you recommend a friend (with similar background to you before the fellowship) to apply?” (8.6/10).
- Alan Chan, David Udell, Hjalmar Wijk, James Faville, Mia Taylor, Nathaniel Sauerberg, Nisan Stiennon, Quratul Zainab, Sylvester Kollin.
- “Are you glad that you participated in the fellowship?” (4.8/5), “If the same program happened next year, would you recommend a friend (with similar background to you before the fellowship) to apply?” (9.5/10).
- “To what extent was the event a good use of your time compared to what you would otherwise have been doing?” (geometric mean: 8.1x as valuable compared to the counterfactual), “How likely is it that you would like to attend a similar event next year if we held one? (75.7%), “Overall, how would you rate the practicalities and logistics before and during the workshop?” (4.6/5)
- A significant part of the conceptual work underlying this paper was done before 2019 at CLR.
- Here is the more technical definition: S-risks are risks of events that bring about suffering in cosmically significant amounts. By “significant”, we mean significant relative to expected future suffering.
- We consider ourselves to be working on “AI safety”. Whether it is also encompassed by “AI alignment” depends on how broadly you define “alignment”. In any case, our work is fairly different from other work in AI alignment (also see this sequence).
- The term “evidential” here is potentially misleading: whilst ECL is often framed in terms of evidential decision theory (EDT), the argument is more general, and applies to many decision theories. One notable exception is causal decision theory (CDT), which for the most part does not endorse ECL. For more details on this, see the ECL paper itself.
- With little dependence on our own values.
- We don’t have the space here to make a case for CLR over other organizations focused on s-risks.
- With little dependence on our own values.
- That said, we currently believe that, although there might be significant overlap, there are likely still some important differences in focus between the portfolio of cooperation work recommended by ECL considerations and that recommended by thinking on s-risks ignoring ECL. We more generally want to ensure that in our work on ECL we consider other kinds of work that could be higher priority but which might be less salient to us.
- We have not systematically assessed to what extent CLR made a significant difference in the career trajectory of these researchers.
- We consider raising the salience of s-risks as potentially harmful. So much of our research remains unpublished. This makes a coherent and informative public review of our research progress difficult.
- Daniel was a Lead Researcher at CLR until mid-2022. He now works at OpenAI on the policy/governance team. However, he continues some other research projects in collaboration with CLR colleagues. He also mentors CLR Summer Research Fellows.
- We consider raising the salience of s-risks as potentially harmful. So much of our research remains unpublished. This makes a coherent and informative public review of our research progress difficult.
- I.e., the utility function that ECL considerations arguably recommend we act so as to optimize, formed as an impartial weighted sum of utility functions of agents across the universe.
- See also the 2016-2019 section of CLR’s history.
- “What is your overall satisfaction with the S-Risk Intro Fellowship?” (8/10), “To what extent has the S-Risk Intro Fellowship met your expectations?” (8.4/10), “How well did the S-Risk Intro Fellowship compare with the ideal intro fellowship?” (7.7/10), “If the same program happened next year, would you recommend a friend (with similar background to you before the fellowship) to apply?” (8.6/10).
- Alan Chan, David Udell, Hjalmar Wijk, James Faville, Mia Taylor, Nathaniel Sauerberg, Nisan Stiennon, Quratul Zainab, Sylvester Kollin.
- “Are you glad that you participated in the fellowship?” (4.8/5), “If the same program happened next year, would you recommend a friend (with similar background to you before the fellowship) to apply?” (9.5/10).
- “To what extent was the event a good use of your time compared to what you would otherwise have been doing?” (geometric mean: 8.1x as valuable compared to the counterfactual), “How likely is it that you would like to attend a similar event next year if we held one? (75.7%), “Overall, how would you rate the practicalities and logistics before and during the workshop?” (4.6/5)
- A significant part of the conceptual work underlying this paper was done before 2019 at CLR.